环境声明
系统: Windows10家庭中文版
硬件: 16G内存、8核CPU
Py版本: 3.7.6
编辑器: PyCharm 2021.1(Community Edition)
变量 介绍
所谓的变量就是存储数据的一个容器
命名规范
在Python中变量名只能包含字母、数字、下划线
变量名不能以数字开头
不能使用Python中的关键词命名(如: list、for等)
变量名要有意义
尽量使用蛇形命名来定义变量名
示例代码 普通命名
1 2 3 4 5 6 7 8 9 a = "小明" b = "男" c = 13 name = "小明" sex = "男" age = 13
蛇形命名
单词全部小写,每个单词使用下划线进行连接
1 2 guest_username = "user1" guest_password = "123456"
驼峰命名
小驼峰: 第一个单词以小写字母开始,后面的每个单词以首字母大写开头(如: myFirstName)
1 2 guestUserName = "user1" guestPassword = "123456"
大驼峰: 所有单词都以首字母大写开头,一般用于命名类名
1 2 3 4 5 6 7 8 9 10 11 12 13 class MyUserData (object def __init__ (self ): self.guest_username = "user1" self.guest_password = "123456" def echo_name (self ): print (self.guest_username) if __name__ == "__main__" : myUserData = MyUserData() myUserData.echo_name()
AI命名
在项目中总是要对一些变量名、类名、函数名等进行规范命名,但是实在想不到该使用哪个单词进行命名时就可以使用 CODELF 进行关键词匹配,勾选对应的编程语言后输入相对应的关键词后点击搜索即可获取到相关的变量名
注释 介绍
注释就是该行代码不被运行,在python中使用#或"""来注释代码
代码示例 1 2 3 4 5 6 7 print ("Hello" )Hello
1 2 3 4 5 6 7 8 9 print ("Hello" )""" print("Hi") print("Hei") """ Hello
字符串 介绍
字符串就是一系列的字符,可以大小写字母、数字、特殊符号等,在Python中使用单引号或双引号来定义
使用字符串 示例1
1 2 3 4 5 6 7 txt = "Hello" print (txt)Hello
示例2
1 2 3 4 5 6 7 txt = 'Hello' print (txt)Hello
示例3
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 txt = """Hello World """ txt2 = """\ Hello World """ print (txt)Hello World
示例4
1 2 3 4 5 6 7 8 9 10 11 print ("Hello\n" )print (r"Hello\n" )print ("---" )Hello Hello\n ---
截取字符串 访问子字符串可以使用[]来截取字符串。索引值从0开始, -1代表末尾位置开始
格式: 变量名[头上标:尾下标]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 txt = "HelloWorld" print (txt[0 ]) print (txt[1 ]) print (txt[-1 ]) print (txt[:]) print (txt[5 :]) print (txt[:5 ]) print (txt[3 :6 ]) print (txt[-5 :]) print (txt[:-5 ]) print (txt[-7 :-4 ])
还可以将截取的字符串与其他字符串进行拼接
1 2 3 4 5 6 7 txt = "Hello Jack" print (txt[:6 ] + "Tom" ) print ("Hi " + txt[-4 :]) txt = txt[:6 ] + "Tom" print (txt)
转义字符 需要在字符串中使用特殊字符时就需要用到转义符\进行转义
符号
描述
示例
输出
\续行符
print("Hello\(回车)World")HelloWorld
\\反斜杠
print("\\\\127.0.0.1")\\127.0.0.1
\'单引号
print('Hello\'World')Hello'World
\"双引号
print("Hello\"World")Hello"World
\a响铃
print("\a")
\b退格符
print("Helloo\b World")Hello World
\t横向制表符
print("Hello\t World")Hello World
\n换行符
print("Hello\nWorld")Hello(换行)World
字符串格式化 字符串格式化符号
符号
描述
%c
格式化字符及ASCII码
%s
格式化字符串
%d
格式化整数
%u
格式化无符号整型
%x
格式化无符号十六进制
%X
格式化无符号十六进制(大写)
%f
格式化浮点数
%e
格式化浮点数(科学计数法)
%p
格式化变量的地址(十六进制数)
示例代码
1 2 3 4 5 6 7 8 9 10 11 12 13 print ("97 98 99 --> %c%c%c" % (97 ,98 ,99 )) print ("我是%s 我今年%d岁" % ("动感超人" , 100.10 )) print ("我是%(name)s 我今年%(age)d岁" % {"name" :"动感超人" , "age" :100.10 }) print ("Pi is %.2f" % 3.1415926 ) print ("Pi is %.0f" % 3.1415926 ) print ("不够3位数添0: %.3f" % 3.1 )
字符串内建函数 title() 首字母大写
1 2 txt = "hello world" print (a.title)
upper() 全部字母大写
1 2 txt = 'hello world' print (txt.upper())
lower() 全部字母小写
1 2 txt = 'Hello World' print (txt.lower())
swapcase() 大小写互换
1 2 txt = "Hello World" print (txt.swapcase())
rstrip() 剔除末尾(right)指定字符
1 2 3 4 5 6 7 8 txt = "\n Hello World \n" print ("!" + txt.rstrip() + "!" ) ! Hello World!
1 2 3 4 5 6 7 print ("Hello World " .rstrip('rld ' )) print ("Hello World " .rstrip(' Wdl' )) print ("Hello__aabbc*" .rstrip('_*abcH' ))
lstrip() 剔除开头(left)指定字符
1 2 3 4 5 6 7 8 txt = "\n Hello World \n" print ("!" + txt.lstrip() + "!" ) !Hello World !
1 2 3 4 5 6 7 print ("Hello World" .lstrip('eH' )) print (" Hello World" .lstrip('eH' )) print ("Hello World" .lstrip('el' ))
strip() 剔除首尾指定字符
1 2 3 4 5 6 7 txt = "\n Hello World \n" print ("!" + txt.strip() + "!" ) !Hello World!
1 2 3 4 5 6 print ("Hello World" .strip('eHd' )) print ("Hello World" .strip('eld' ))
join() 将序列中的元素与指定字符拼接
1 2 3 4 5 txt = ("Hello" ,"World" ) s1 = "_" s2 = "" print (s1.join(txt)) print (s2.join(txt))
len() 返回字符串长度
1 2 3 4 5 txt = "Hello World" print ("共有%s个字符" % len (txt))共有11 个字符
count() 统计某个字符在字符串中出现的次数
1 2 3 4 5 txt = "Hello World" print ("字符'l'一共有%s个" % txt.count('l' ))字符'l' 一共有3 个
split() 指定分隔符进行切片
1 2 3 4 5 6 7 8 9 10 11 12 txt = "窗前明月光,疑是地上霜。举头望明月,低头思故乡。" txt_list = txt.split('。' ) print ("类型: %s" % type (txt_list)) print (txt_list) for i in txt_list: print (i) 类型: <class 'list '> ['窗前明月光,疑是地上霜', '举头望明月,低头思故乡', ''] 窗前明月光,疑是地上霜 举头望明月,低头思故乡
1 2 3 4 5 6 7 8 9 10 11 url = "https://www.xxx.com/img/xxx-xx123-xx.jpg" print ("图片类型为: %s" % url.split('.' )[-1 ])print ("图片全名为: %s" % url.split('/' )[-1 ])print ("网站地址为: %s" % url.split('/' )[2 ])图片类型为: jpg 图片全名为: xxx-xx123-xx.jpg 网站地址为: www.xxx.com
splitlines() 按照\n \r\n \r分隔符进行切片
1 2 3 4 5 6 7 8 9 10 11 12 13 14 txt = "窗前明月光,\n疑是地上霜。\n举头望明月,\n低头思故乡。\n" txt_list = txt.splitlines() print ("类型: %s" % type (txt_list)) print (txt_list) for i in txt_list: print (i) 类型: <class 'list '> ['窗前明月光,', '疑是地上霜。', '举头望明月,', '低头思故乡。'] 窗前明月光, 疑是地上霜。 举头望明月, 低头思故乡。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 txt = "窗前明月光,\n疑是地上霜。\n举头望明月,\n低头思故乡。\n" txt_list = txt.splitlines(True ) print ("类型: %s" % type (txt_list)) print (txt_list) for i in txt_list: print (i) 类型: <class 'list '> ['窗前明月光,\n ', '疑是地上霜。\n ', '举头望明月,\n ', '低头思故乡。\n '] 窗前明月光, 疑是地上霜。 举头望明月, 低头思故乡。
填充与对齐 使用格式符填充对齐
1 2 3 4 5 6 7 8 txt = "Hello" txt2 = "Jack|Tom|Jerry" print ("%-20s%s" % (txt,txt2)) print ("%-20s%s" % (txt2,txt))Hello Jack|Tom|Jerry Jack|Tom|Jerry Hello
使用format()函数进行填充对齐,^居中、<左对齐、>右对齐
1 2 3 4 5 6 7 8 9 10 11 print ('{:>8}' .format ('Hello' )) print ('{:*>8}' .format ('Hello' )) print ('{:*<8}' .format ('Hello' )) print ('{:*^11}' .format ('Hello' )) Hello ***Hello Hello*** ***Hello***
1 2 3 4 5 6 7 8 9 10 11 12 website = {'百度' :'baidu.com' ,'谷歌' :'google.com' ,'必应' :'bing.com' } print ("{0:10}{1:10}" .format ("网站名称" ,"网站地址" ))for name,url in website.items(): print ('{0:10}{1:10}' .format (name,url)) 网站名称 网站地址 百度 baidu.com 谷歌 google.com 必应 bing.com
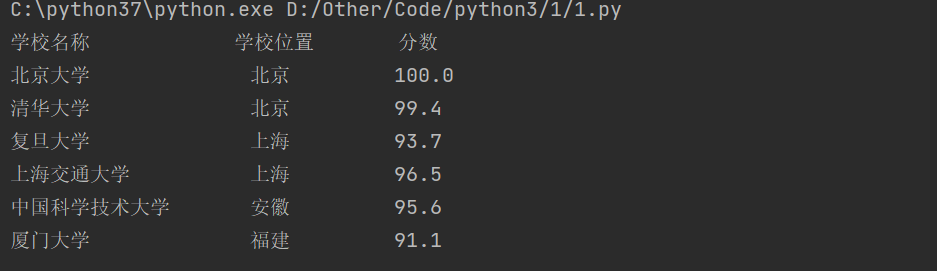
1 2 3 4 5 6 7 8 9 10 11 12 13 school = ['北京大学' ,'清华大学' ,'复旦大学' ,'上海交通大学' ,'中国科学技术大学' ,'厦门大学' ] address = ['北京' ,'北京' ,'上海' ,'上海' ,'安徽' ,'福建' ] fraction = ['100.0' ,'99.4' ,'93.7' ,'96.5' ,'95.6' ,'91.1' ] max_len = 20 print ("{0:16}{1:11}{2:10}" .format ("学校名称" ,"学校位置" ,"分数" ))for i in range (len (school)): str_len = max_len - len (school[i].encode('GBK' )) + len (school[i]) print ('{0:<{1}}\t{2:<10}\t{3}' .format (school[i],str_len,address[i],fraction[i]))
字符串运算 基本运算
1 2 3 4 a = "Hello" b = "World" print (a + b) print (a * 2 )
判断字符是否包含在其他字符中
1 2 3 4 5 6 7 8 a = "Hello" if "H" in a: print ("H存在于变量a中" ) else : print ("H不存在于变量a中" ) H存在于变量a中
判断字符是否不包含在其他字符中
1 2 3 4 5 6 7 8 a = "Hello" if "H" not in a: print ("H不存在于变量a中" ) else : print ("H存在于变量a中" ) H存在于变量a中
字符拼接 使用 + 进行拼接1 2 3 a = 'Hello' b = 'World' print (a + " " + b + "!" )
使用,进行拼接
1 2 3 a = 'Hello' b = 'World' print (a,b,"!" )
使用 % 进行拼接
1 2 3 a = 'Hello' b = 'World' print ("%s %s !" %(a,b))
使用f进行拼接
1 2 3 a = 'Hello' b = 'World' print (f"{a} {b} !" )
使用 format()进行拼接
1 2 3 4 5 6 a = 'Hello' b = 'World' print ("{} {} !" .format (a,b)) print ("{hi} {name} !" .format (hi=a,name='Jack' )) print ('{:,}' .format (123654789 )) print ('{:.2f}' .format (3.1415926 ))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 url = "http://www.xxx.com/?t=%d" for i in range (1 , 10 ): new_url = format (url % i) print (new_url) http://www.xxx.com/?t=1 http://www.xxx.com/?t=2 http://www.xxx.com/?t=3 http://www.xxx.com/?t=4 http://www.xxx.com/?t=5 http://www.xxx.com/?t=6 http://www.xxx.com/?t=7 http://www.xxx.com/?t=8 http://www.xxx.com/?t=9
数字 介绍
Python的数字数据类型用于存储数值,数据类型是不允许被改变的,如果更改了数字数据类型将需要重新分配内存空间
类型
描述
整型 int
通常被称为整型或者整数,由正或负整数组成
浮点型 float
由整数部分与小数部分组成
复数 complex
由实数部分和虚数部分组成
整型 1 2 3 4 5 6 print (2 + 3 ) print (2 - 3 ) print (2 * 3 ) print (2 ** 3 ) print (9 / 3 ) print (10 % 3 )
浮点型 1 2 3 4 5 6 7 print (0.2 + 0.3 ) print (0.2 - 0.3 ) print (0.2 * 3 ) print (0.2 ** 3 ) print (9 / 0.3 ) print (10 % 0.3 )
类型转换 int() 转换为整型
1 2 3 4 a = 3.1415926 print (int (a))
float() 转换为浮点型
1 2 3 a = 10 print (float (a)) print ("%.2f" % float (a))
str() 转换为字符串
1 2 3 4 a = 1 print ("Page: " + a) print ("Page: " + str (a))
运算符 介绍
Python中支持的运算符有: 算术运算符、比较运算符、赋值运算符、位运算符、逻辑运算符、成员运算符、身份运算符
算数运算符 运算符
运算符
描述
+
两对象相加
-
两对象相减
*
两对象相乘
/
两对象相除
%
取模 返回除法的余数
**
幂
//
整除 接近商的整数
示例代码
1 2 3 4 5 6 7 8 9 10 a = 10 b = 3 print (a + b) print (a - b) print (a * b) print (a / b) print (a % b) print (a ** b) print (a // b)
比较运算符 运算符
运算符
描述
==比较对象是否相等
!=比较对象是否不相等
>比较对象是否大于
<比较对象是否小于
>=比较对象是否大于等于
<=比较对象是否小于等于
示例代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 a = 10 b = 20 c = 10 if a == b: print ("a == b" ) else : print ("a != b" ) if a >= b: print ("a >= b" ) else : print ("a <= b" )
赋值运算符 运算符
运算符
描述
=简单赋值运算符
+=加法 a=a+1 等同 a+=1
-=减法 a=a-1 等同 a-=1
*=乘法 a=a*1 等同 a*=1
/=除法 a=a/1 等同 a/=1
%=取模 a=a%1 等同 a%=1
**=幂 a=a**1 等同 a**=1
//=取整 a=a//1 等同 a//=1
示例代码
位运算符
位运算符是把数字变成二进制来进行计算
运算符
运算符
描述
&与运算符(AND): 两个值都为1则返回1,否则返回0
管道符(符号渲染异常)或运算符(OR): 两个值有一个为1则返回1,否则返回0
^异或运算符(XOR): 两个值不同则返回1,否则返回0
~取反运算符(NAND): 1变0 0变1
<<左移动运算符: 各位全部左移若干位,高位丢弃低位补0
>>右移动运算符: 各位全部右移若干位
示例代码
1 2 3 4 5 6 7 8 9 10 11 12 a = 110 b = 58 print (b & a) print (a | b) print (a ^ b) print (a << 2 ) print (a >> 2 ) print (~b)
逻辑运算符 运算符
运算符
描述
and
与: 两边同时成立则返回True
or
或: 一边成立则返回True
not
非: 如果成立则返回False
示例代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 a = 1 b = 0 if a and b: print ("True" ) else : print ("False" ) if a or b: print ("True" ) else : print ("False" ) if not a: print ("True" ) else : print ("False" ) if not (a and b): print ("True" ) else : print ("False" )
成员运算符 运算符
运算符
描述
in
如包含在指定序列中则返回True,否则返回False
not in
如不包含在指定序列中则返回True,否则返回False
示例代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 a = "Hello" b = [1 ,2 ,3 ,4 ,5 ] if "H" in a: print ("变量a中包含字符H" ) else : print ("变量a中不包含字符H" ) if "H" not in a: print ("变量a中不包含字符H" ) else : print ("变量a中包含字符H" ) if 5 in b: print ("列表b中包含数字5" ) else : print ("列表b中不包含数字5" )
身份运算符
is 用于判断两个变量引用对象是否为同一个(同一块内存空间), == 用于判断引用变量的值是否相等。
运算符
运算符
描述
is
判断两个标识符是否引用自同一对象
is not
判断两个标识符是否引用自不同对象
示例代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 a = 1 if 1 is a: print ("变量a与1有相同标识" ) else : print ("变量a与1没有相同标识" ) if 1 is not a: print ("变量a与1没有相同标识" ) else : print ("变量a与1有相同标识" ) if 2 is a: print ("变量a与2有相同标识" ) else : print ("变量a与2没有相同标识" )
运算符优先级 优先级
下表来自菜鸟教程
运算符
描述
**指数 (最高优先级)
~ + -按位翻转, 一元加号和减号 (最后两个的方法名为 +@ 和 -@)
* / % //乘,除,取模和取整除
+ -加法减法
>> <<右移,左移运算符
&位 ‘AND’
^ 管道符位运算符
<= < > >=比较运算符
<> == !=等于运算符
= %= /= //= -= += *= **=赋值运算符
is is not身份运算符
in not in成员运算符
not and or逻辑运算符
示例代码
1 2 3 4 5 6 7 8 a = 5 b = 10 c = 15 d = 20 print ("a + b * c / a =" , a + b * c / a) print ("(a + b) * c / a =" , (a + b) * c / a) print ("c + b ** a =" , c + b ** a)
If判断 介绍
Python条件语句是通过一条或多条语句的执行结果(True | False)来决定指定的代码块
1 2 3 4 5 if 条件: 上方条件成立时(True 或1 )执行该代码块 else : 上方条件不成立时(False 或0 )执行该代码块
基本判断 字符比较
1 2 3 4 5 6 7 8 9 10 txt1 = "Hello" txt2 = "Hello" if txt1 == txt2: print ("txt1与txt2相等" ) else : print ("txt1与txt2不相等" ) txt1与txt2相等
数字比较
1 2 3 4 5 6 7 8 num = 10 + 10 if num != 20 : print ("答错了" ) else : print ("答对了" ) 答对了
多语句判断
1 2 3 4 5 6 7 8 9 10 11 12 13 num = int (input ("输入整数成绩: " )) if num >= 90 : print ("你的等级为A" ) elif num >= 80 : print ("你的等级为B" ) elif num >= 70 : print ("你的等级为C" ) elif num >= 60 : print ("你的等级为D" ) else : print ("你的等级为E" )
多条件判断 单条件成立
1 2 3 4 5 6 7 8 9 10 11 12 a = 1 b = 2 c = 1 if a == b or a == c: print ("变量a等于变量b或变量c" ) else : print ("变量a不等于变量b或变量c" ) 变量a等于变量b或变量c
多条件同时成立
1 2 3 4 5 6 7 8 9 10 11 12 13 username = str (input ("输入用户名: " )) password = str (input ("输入密码: " )) if username == "admin" and password == "123456" : print ("登录成功" ) else : print ("登录失败" ) print ("执行结束" ) 当输入正确的用户名密码后才会返回登录成功 执行结束
if嵌套 示例代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 num = int (input ("输入一个整数: " )) if num % 2 == 0 : if num % 3 == 0 : print ("%s可以被2和3同时整除" % num) else : print ("%s只能被2整除" % num) else : if num % 3 == 0 : print ("%s只能被3整除" % num) else : print ("%s不能被2和3整除" % num) 输入1 返回: 1 不能被2 和3 整除 输入2 返回: 2 只能被2 整除 输入3 返回: 3 只能被3 整除 输入6 返回: 6 可以被2 和3 同时整除
For循环 介绍
for循环一般用于遍历任何序列的项目,如字符串、列表、元组、字典等。
1 2 3 4 5 for 变量 in 序列: 循环体 else : 序列为空时执行的代码块
示例代码 遍历列表
1 2 3 4 5 6 7 8 9 users = ['tom' ,'jack' ,'jerry' ] for user in users: if "jack" == user: print ("Hello Jack" ) print ("END" ) Hello Jack END
数字序列
1 2 3 4 5 6 for i in range (1 ,6 ): print (i) 1 2 3 4 5
1 2 3 4 5 6 for i in range (6 ): print (i) 0 1 2 3 4 5
1 2 3 4 5 6 for i in range (1 ,10 ,2 ): print (i) 1 3 5 7 9
pass 不做执行
1 2 3 4 5 6 7 8 for i in range (5 ): pass print ("END" )END
更多序列遍历会在所属章节说明
跳出循环 break 终止循环
1 2 3 4 5 6 7 8 for i in range (1 ,10 ): if i % 2 == 0 : print (i) break 2
continue 回到循环开头
1 2 3 4 5 6 7 8 9 for i in range (1 ,10 ): if i % 2 != 0 : continue print (i) 2 4 6 8
While循环 介绍
在递归算法中更适合使用While循环,一直循环直到表达式不成立为止
示例代码 猜数字游戏
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 num = 15 in_num = None while in_num != num: in_num = int (input ('猜猜正确数字: ' )) if in_num < num: print ("小了小了" ) elif in_num > num: print ("大了大了" ) else : print ("答对了" ) print ("游戏结束" )猜猜正确数字: 5 小了小了 猜猜正确数字: 16 大了大了 猜猜正确数字: 15 答对了 游戏结束
使用标志结束循环
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 status = True while status: in_name = input ("输入姓名: " ) if in_name == "quit" : status = False else : print ("Hello " + str (in_name)) print ("循环结束" )输入姓名: Jack Hello Jack 输入姓名: Tom Hello Tom 输入姓名: quit 循环结束
跳出循环 break 退出循环
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 num = 15 frequency = 0 in_num = None while in_num != num: in_num = int (input ('猜猜正确数字: ' )) frequency += 1 if frequency >= 3 : print ("机会已用完" ) break if in_num < num: print ("小了小了" ) elif in_num > num: print ("大了大了" ) else : print ("答对了" ) print ("游戏结束" )猜猜正确数字: 10 小了小了 猜猜正确数字: 17 大了大了 猜猜正确数字: 16 机会已用完 游戏结束
continue 回到循环开头
1 2 3 4 5 6 7 8 9 10 11 12 13 num = 0 while num <= 10 : num += 1 if num % 2 != 0 : continue print ("1~10的偶数有: " + str (num)) 1 ~10 的偶数有: 2 1 ~10 的偶数有: 4 1 ~10 的偶数有: 6 1 ~10 的偶数有: 8 1 ~10 的偶数有: 10
列表 介绍
列表是由一系列按照特定顺序排列的元素组成。列表中可以包含字母、数字、中文等,在Python中列表用[]来表示,用,来分隔元素,列表的所索引从0开始
定义列表 定义列表
1 2 3 4 5 6 7 8 users = ['tom' ,'jack' ,'jerry' ] print (type (users)) print (users)<class 'list '> ['tom ', 'jack ', 'jerry ']
使用range()创建列表
1 2 3 4 5 6 7 8 num = list (range (1 ,10 )) num2 = list (range (1 ,10 ,2 )) print (num)print (num2)[1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 ] [1 , 3 , 5 , 7 , 9 ]
使用循环创建列表
1 2 3 4 5 urls = [f'https://xx.xx.xx/?t={page} ' for page in range (1 ,10 )] print (urls)['https://xx.xx.xx/?t=1' , 'https://xx.xx.xx/?t=2' , 'https://xx.xx.xx/?t=3' , 'https://xx.xx.xx/?t=4' , 'https://xx.xx.xx/?t=5' , 'https://xx.xx.xx/?t=6' , 'https://xx.xx.xx/?t=7' , 'https://xx.xx.xx/?t=8' , 'https://xx.xx.xx/?t=9' ]
列表切片 列表切片与字符串截取方法类似,-1代表末尾位置开始
1 2 3 4 5 6 7 8 9 10 11 users = ['tom' ,'jack' ,'jerry' ,'superman' ,'giao' ] print (users[:]) print (users[2 :]) print (users[:2 ]) print (users[1 :3 ]) print (users[-3 :]) print (users[:-3 ]) print (users[1 :-2 ])
遍历切片
1 2 3 4 5 6 7 8 users = ['tom' ,'jack' ,'jerry' ,'superman' ,'giao' ] for user in users[:3 ]: print ("Hello " + user) Hello tom Hello jack Hello jerry
访问列表元素 通过索引访问
1 2 3 4 5 6 7 8 9 10 11 12 users = ['tom' ,'jack' ,'jerry' ] print ("Hello " + users[0 ]) print ("Hello " + users[1 ]) print ("Hello " + users[-1 ]) print ("Hello " + users[-2 ]) Hello tom Hello jack Hello jerry Hello jack
遍历列表
1 2 3 4 5 6 7 8 9 users = ['tom' ,'jack' ,'jerry' ] for user in users: print ("Hello " + user) Hello tom Hello jack Hello jerry
1 2 3 4 5 6 7 8 9 users = ['tom' ,'jack' ,'jerry' ] for num in range (len (users)): print ("Hello " + users[num]) Hello tom Hello jack Hello jerry
1 2 3 4 5 6 users = ['tom' ,'jack' ,'jerry' ] print (" " .join(users)) tom jack jerry
遍历多个列表
1 2 3 4 5 6 7 8 9 10 11 username = ['A' ,'B' ,'C' ,'D' ] password = ['1' ,'2' ,'3' ,'4' ] for user,passwd in zip (username,password): print (f"{user} : {passwd} " ) A : 1 B : 2 C : 3 D : 4
修改列表元素 通过索引修改
1 2 3 4 5 6 7 8 9 10 users = ['tom' ,'jack' ,'jerry' ] print ("修改前: " + str (users))users[0 ] = "giao" print ("修改后: " + str (users))修改前: ['tom' , 'jack' , 'jerry' ] 修改后: ['giao' , 'jack' , 'jerry' ]
添加列表元素
方法
描述
append()
在列表末尾添加元素
insert()
在列表指定位置添加元素
append() 在列表末尾添加元素
1 2 3 4 5 6 7 8 9 10 users = ['tom' ,'jack' ,'jerry' ] print ("添加前: " + str (users))users.append("giao" ) print ("添加后: " + str (users))添加前: ['tom' , 'jack' , 'jerry' ] 添加后: ['tom' , 'jack' , 'jerry' , 'giao' ]
insert() 在列表任意位置添加元素
1 2 3 4 5 6 7 8 9 10 users = ['tom' ,'jack' ,'jerry' ] print ("添加前: " + str (users))users.insert(1 ,"giao" ) print ("添加后: " + str (users))添加前: ['tom' , 'jack' , 'jerry' ] 添加后: ['tom' , 'giao' , 'jack' , 'jerry' ]
删除列表元素
方法
描述
del
根据索引删除列表指定元素
pop()
根据索引删除列表指定元素(可将删除的内容再赋值给其他变量,相当于剪切)
remove()
根据元素内容删除列表指定元素
del 删除列表元素
1 2 3 4 5 6 7 8 9 10 users = ['tom' ,'jack' ,'jerry' ] print ("删除前: " + str (users))del users[0 ] print ("删除后: " + str (users))删除前: ['tom' , 'jack' , 'jerry' ] 删除后: ['jack' , 'jerry' ]
pop() 删除列表元素
1 2 3 4 5 6 7 8 9 10 11 12 users = ['tom' ,'jack' ,'jerry' ] print ("删除前: " + str (users))del_user = users.pop(0 ) print ("删除的元素: " + del_user)print ("删除后: " + str (users))删除前: ['tom' , 'jack' , 'jerry' ] 删除的元素: tom 删除后: ['jack' , 'jerry' ]
remove() 删除列表元素
1 2 3 4 5 6 7 8 9 10 users = ['tom' ,'jack' ,'jerry' ] print ("删除前: " + str (users))users.remove("jack" ) print ("删除后: " + str (users))删除前: ['tom' , 'jack' , 'jerry' ] 删除后: ['tom' , 'jerry' ]
列表元素去重 set() 方法
1 2 3 4 5 6 7 8 9 10 list1 = ['a' , 'b' , 'a' , 'd' , 'e' ] print ("元素去重前: " + str (list1))list1 = list (set (list1)) print ("元素去重后: " + str (list1))元素去重前: ['a' , 'b' , 'a' , 'd' , 'e' ] 元素去重后: {'b' , 'a' , 'e' , 'd' }
keys() 方法
1 2 3 4 5 6 7 8 9 10 list1 = ['a' , 'b' , 'a' , 'd' , 'e' ] print ("元素去重前: " + str (list1))list1 = list ({}.fromkeys(list1).keys()) print ("元素去重后: " + str (list1))元素去重前: ['a' , 'b' , 'a' , 'd' , 'e' ] 元素去重后: ['a' , 'b' , 'e' , 'd' ]
循环遍历法
1 2 3 4 5 6 7 8 9 10 11 12 13 list1 = ['a' , 'b' , 'a' , 'd' , 'e' ] list2 = [] print ("元素去重前: " + str (list1))for i in list1: if i not in list2: list2.append(i) print ("元素去重后: " + str (list2))元素去重前: ['a' , 'b' , 'a' , 'd' , 'e' ] 元素去重后: ['a' , 'b' , 'd' , 'e' ]
去重后按照索引排序
1 2 3 4 5 6 7 8 9 10 11 12 13 list1 = ['a' , 'b' , 'a' , 'd' , 'e' ] print ("去重前: " + str (list1))list2 = list (set (list1)) print ("去重排序前: " + str (list2))list2.sort(key=list1.index) print ("去重排序后: " + str (list2))去重前: ['a' , 'b' , 'a' , 'd' , 'e' ] 去重排序前: ['b' , 'e' , 'd' , 'a' ] 去重排序后: ['a' , 'b' , 'd' , 'e' ]
列表内建函数
方法
描述
sort()
按照字母或数字顺序将列表中的元素进行永久排序
sorted()
按照字母或数字顺序将列表中的元素进行临时排序
reverse()
将列表倒过来
len()
返回列表元素个数
max()
按照字母或数字大小返回列表中最大的元素
min()
按照字母或数字大小返回列表中最小的元素
list()
将其他数据类型转换为列表
count()
统计某个元素出现在列表中的个数
clear()
清空列表
copy()
赋值列表
sort() 列表永久性排序
1 2 3 4 5 6 7 8 list1 = ['b' ,'d' ,'a' ,'c' ,'e' ] print ("排序前: " + str (list1))list1.sort() print ("排序后: " + str (list1))排序前: ['b' , 'd' , 'a' , 'c' , 'e' ] 排序后: ['a' , 'b' , 'c' , 'd' , 'e' ]
sorted() 列表临时性排序
1 2 3 4 5 6 7 8 9 10 list1 = ['b' ,'d' ,'a' ,'c' ,'e' ] print ("排序前: " + str (list1))list2 = sorted (list1) print ("排序后: " + str (list1)) print ("排序后: " + str (list2))排序前: ['b' , 'd' , 'a' , 'c' , 'e' ] 排序后: ['b' , 'd' , 'a' , 'c' , 'e' ] 排序后: ['a' , 'b' , 'c' , 'd' , 'e' ]
reverse() 倒着排序列表
1 2 3 4 5 6 7 8 list1 = ['a' , 'b' , 'c' , 'd' , 'e' ] print ("正序: " + str (list1))list1.reverse() print ("反序: " + str (list1))正序: ['a' , 'b' , 'c' , 'd' , 'e' ] 反序: ['e' , 'd' , 'c' , 'b' , 'a' ]
len() 返回元素个数
1 2 3 4 5 list1 = ['a' , 'b' , 'c' , 'd' , 'e' ] print ("共有%s个元素" % len (list1))共有5 个元素
max() 返回列表最大值
1 2 3 4 5 6 7 8 list1 = ['a' , 'b' , 'c' , 'd' , 'e' ] list2 = [1 ,2 ,3 ,4 ,5 ] print ("list1最大元素为: %s" % max (list1))print ("list2最大元素为: %s" % max (list2))list1最大元素为: e list2最大元素为: 5
min() 返回列表最小值
1 2 3 4 5 6 7 8 list1 = ['a' , 'b' , 'c' , 'd' , 'e' ] list2 = [1 ,2 ,3 ,4 ,5 ] print ("list1最小元素为: %s" % min (list1))print ("list2最小元素为: %s" % min (list2))list1最小元素为: a list2最小元素为: 1
list() 转换为列表
1 2 3 4 5 6 7 8 9 10 11 12 users = ('tom' ,'jack' ,'jerry' ) print ("转换前类型为: " + str (type (users)))print (str (users))users = list (users) print ("转换后类型为: " + str (type (users)))print (str (users))转换前类型为: <class 'tuple '> ('tom' , 'jack' , 'jerry' 转换后类型为: <class 'list '>['tom ', 'jack ', 'jerry ']
count() 统计元素出现次数
1 2 3 4 5 6 7 list1 = ['a' , 'b' , 'a' , 'da' , 'a' ] print ("元素a在列表中共出现了: %s次" % list1.count('a' ))print ("元素b在列表中共出现了: %s次" % list1.count('b' ))元素a在列表中共出现了: 3 次 元素b在列表中共出现了: 1 次
clear() 清空列表
1 2 3 4 5 6 7 8 list1 = ['a' , 'b' , 'a' , 'da' , 'a' ] print ("列表清空前: " + str (list1))list1.clear() print ("列表清空后: " + str (list1))列表清空前: ['a' , 'b' , 'a' , 'da' , 'a' ] 列表清空后: []
copy() 复制列表
1 2 3 4 5 6 7 8 list1 = ['a' , 'b' , 'a' , 'da' , 'a' ] list2 = list1.copy() print ("列表list1: " + str (list1))print ("列表list2: " + str (list2))列表list1: ['a' , 'b' , 'a' , 'da' , 'a' ] 列表list2: ['a' , 'b' , 'a' , 'da' , 'a' ]
列表推导式 1 2 3 4 # 格式 [表达式 for 变量 in 列表] [表达式 for 变量 in range(数字范围)] [表达式 for 变量 in 列表 if 条件]
1 2 3 4 5 6 7 old_list = [1 ,2 ,3 ] new_list = [x*2 for x in old_list] print (new_list)[2 ,4 ,6 ]
1 2 3 4 5 6 new_list = [x for x in range (1 ,5 )] print (new_list)[1 , 2 , 3 , 4 ]
1 2 3 4 5 6 new_list = [x for x in range (1 ,5 ) if x != 3 ] print (new_list)[1 , 2 , 4 ]
元组 介绍
元组与列表相似,不同之处在于元组的元素不能被修改。元组一般用来存储一些不可变的值,而列表一般用来存储可能变化的数据集。在Python中元组用()来表示,用,来分隔元素,元组的所索引从0开始。元组的内建函数与列表内建函数一样,很多操作方法也都一样。
元组不可被修改
当列表被修改时内存地址不变,当元组被修改时内存地址发生改变,说明元组被修改后就相当于重新定义了一个元组
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 users_list = ['tom' ,'jack' ,'jerry' ] print ("列表修改前内存地址为: " + str (id (users_list)))users_list[0 ] = "gaio" print ("列表修改后内存地址为: " + str (id (users_list)))users_tuple = ('tom' ,'jack' ,'jerry' ) print ("\n元组修改前内存地址为: " + str (id (users_tuple)))users_tuple = ('giao' ,'jack' ,'jerry' ) print ("元组修改后内存地址为: " + str (id (users_tuple)))列表修改前内存地址为: 2708531663368 列表修改后内存地址为: 2708531663368 元组修改前内存地址为: 2708531663880 元组修改后内存地址为: 2708532942216
定义元组 示例代码
1 2 3 4 5 6 7 8 9 10 11 users_1 = () users_2 = ('jack' ,) users_3 = ('jack' ,'man' ,'jerry' ) print (users_1)print (users_2)print (users_3)() ('jack' ,) ('jack' , 'man' , 'jerry' )
数据类型转换
1 2 3 4 5 6 7 8 9 users = ['tom' ,'jack' ,'jerry' ] print ("转换前数据类型为: " + str (type (users)))users = tuple (users) print ("转换前数据类型为: " + str (type (users)))转换前数据类型为: <class 'list '> 转换前数据类型为: <class 'tuple '>
访问元组元素 访问元组
1 2 3 4 5 6 7 8 9 10 11 12 13 users = ('tom' ,'jack' ,'jerry' ) print ("Hello " + users[0 ]) print ("Hello " + users[1 ]) print ("Hello " + users[2 ]) print ("Hello " + users[-1 ]) Hello tom Hello jack Hello jerry Hello jerry
遍历元组
1 2 3 4 5 6 7 8 users = ('tom' ,'jack' ,'jerry' ) for user in users: print ("Hello " + user) Hello tom Hello jack Hello jerry
元组切片
1 2 3 4 5 6 7 8 9 10 11 12 13 users = ('tom' ,'jack' ,'jerry' ,'superman' ,'giao' ) print (users[:]) print (users[2 :]) print (users[:2 ]) print (users[1 :3 ]) print (users[-3 :]) print (users[:-3 ]) print (users[1 :-2 ])
遍历切片
1 2 3 4 5 6 7 8 users = ('tom' ,'jack' ,'jerry' ,'superman' ,'giao' ) for user in users[:3 ]: print ("Hello " + user) Hello tom Hello jack Hello jerry
修改元组元素 元组的元素是不允许被修改的,但可以对该元组重新赋值,达到修改的目的
1 2 3 4 5 6 7 8 users = ('tom' ,'jack' ,'jerry' ) print ("修改前: " + str (users))users = ('tom' ,'jack' ,'jerry' ,'giao' ) print ("修改后: " + str (users))修改前: ('tom' , 'jack' , 'jerry' ) 修改后: ('tom' , 'jack' , 'jerry' , 'giao' )
删除元组元素 元组的元素同样不允许被删除,但可以使用del直接删除整个元组
1 2 3 4 5 6 7 8 users = ('tom' ,'jack' ,'jerry' ) print ("删除前: " + str (users))del usersprint ("删除后: " + str (users))删除前: ('tom' , 'jack' , 'jerry' ) 报错: NameError: name 'users' is not defined
元组推导式 元组推导式与列表推导式用法完全相同
1 2 3 4 # 格式 (表达式 for 变量 in 列表) (表达式 for 变量 in range(数字范围)) (表达式 for 变量 in 列表 if 条件)
1 2 3 4 5 6 7 old_tuple = (1 ,2 ,3 ) new_tuple = tuple ((x*2 for x in old_tuple)) print (new_tuple)(2 ,4 ,6 )
1 2 3 4 5 6 new_tuple = tuple ((x for x in range (1 ,5 ))) print (new_tuple)(1 , 2 , 3 , 4 )
1 2 3 4 5 6 new_tuple = tuple ((x for x in range (1 ,5 ) if x != 3 )) print (new_tuple)(1 , 2 , 4 )
字典 介绍
字典是另一种可变容器模型,可以存储任意对象。在Python中字典是一系列的键值对,每一个键都对应着每一个值。在Python中使用{}来表示字典,使用,来分隔字典元素,使用:来分隔键值对
定义字典 普通字典
1 2 3 4 5 6 7 8 9 10 data = {'temp' :'14' ,'humi' :'96' } print ("温度为: " + data['temp' ])print ("湿度为: " + data['humi' ])温度为: 14 湿度为: 96
列表字典
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 fujian = {'temp' :'14' ,'humi' :'96' } beijing = {'temp' :'-1' ,'humi' :'90' } shanghai = {'temp' :'11' ,'humi' :'85' } data = [fujian,beijing,shanghai] print ("data: " + str (data))print ("福建温湿度: {temp}° {humi}%" .format (temp=data[0 ]['temp' ],humi=data[0 ]['humi' ]))print ("北京温湿度: {temp}° {humi}%" .format (temp=data[1 ]['temp' ],humi=data[0 ]['humi' ]))print ("上海温湿度: {temp}° {humi}%" .format (temp=data[2 ]['temp' ],humi=data[0 ]['humi' ]))data: [{'temp' : '14' , 'humi' : '96' }, {'temp' : '-1' , 'humi' : '90' }, {'temp' : '11' , 'humi' : '85' }] 福建温湿度: 14 ° 96 % 北京温湿度: -1 ° 96 % 上海温湿度: 11 ° 96 %
字典列表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 data = { '福建' :['14' ,'96' ], '北京' :['-1' ,'90' ], '上海' :['11' ,'85' ] } print ("data: " + str (data))print ("福建温湿度: {temp}° {humi}%" .format (temp=data['福建' ][0 ],humi=data['福建' ][1 ]))print ("北京温湿度: {temp}° {humi}%" .format (temp=data['北京' ][0 ],humi=data['北京' ][1 ]))print ("上海温湿度: {temp}° {humi}%" .format (temp=data['上海' ][0 ],humi=data['上海' ][1 ]))data: {'福建' : ['14' , '96' ], '北京' : ['-1' , '90' ], '上海' : ['11' , '85' ]} 福建温湿度: 14 ° 96 % 北京温湿度: -1 ° 90 % 上海温湿度: 11 ° 85 %
字典字典
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 data = { '福建' : {'temp' :'14' ,'humi' :'96' }, '北京' : {'temp' :'-1' ,'humi' :'90' }, '上海' : {'temp' :'11' ,'humi' :'85' }, } print ("data: " + str (data))print ("福建温湿度: {temp}° {humi}%" .format (temp=data['福建' ]['temp' ],humi=data['福建' ]['humi' ]))print ("北京温湿度: {temp}° {humi}%" .format (temp=data['北京' ]['temp' ],humi=data['北京' ]['humi' ]))print ("上海温湿度: {temp}° {humi}%" .format (temp=data['上海' ]['temp' ],humi=data['上海' ]['humi' ]))data: {'福建' : {'temp' : '14' , 'humi' : '96' }, '北京' : {'temp' : '-1' , 'humi' : '90' }, '上海' : {'temp' : '11' , 'humi' : '85' }} 福建温湿度: 14 ° 96 % 北京温湿度: -1 ° 90 % 上海温湿度: 11 ° 85 %
混合嵌套
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 data = { 'users' : [ { 'username' : 'admin' , 'password' : '123456' , 'city' : '福建' , 'email' : 'admin@qq.com' }, { 'username' : 'jack' , 'password' : '123321' , 'city' : '北京' , 'email' : 'jack@qq.com' }, { 'username' : 'guest' , 'password' : '654321' , 'city' : '上海' , 'email' : 'guest@qq.com' }, ], 'temp_humi' : { '福建' : { 'temp' : '14' , 'humi' : '96' }, '北京' : { 'temp' : '-1' , 'humi' : '90' }, '上海' : { 'temp' : '11' , 'humi' : '85' }, }, 'status' : '200' } users = data['users' ] temp_humi = data['temp_humi' ] status = data['status' ] print ("data: " + str (data))print ('用户名: {username} 邮箱: {email}' .format (username=users[0 ]['username' ],email=users[0 ]['email' ]))print ("福建温湿度: {temp}° {humi}%" .format (temp=temp_humi['福建' ]['temp' ],humi=temp_humi['福建' ]['humi' ]))print (f"状态码: {status} " )data: {'users' : [{'username' : 'admin' , 'password' : '123456' , 'city' : '福建' , 'email' : 'admin@qq.com' }, {'username' : 'jack' , 'password' : '123321' , 'city' : '北京' , 'email' : 'jack@qq.com' }, {'username' : 'guest' , 'password' : '654321' , 'city' : '上海' , 'email' : 'guest@qq.com' }], 'temp_humi' : {'福建' : {'temp' : '14' , 'humi' : '96' }, '北京' : {'temp' : '-1' , 'humi' : '90' }, '上海' : {'temp' : '11' , 'humi' : '85' }}, 'status' : '200' } 用户名: admin 邮箱: admin@qq.com 福建温湿度: 14 ° 96 % 状态码: 200
访问字典 keys() 遍历键
1 2 3 4 5 6 7 8 9 10 11 12 data = { '福建' :['14' ,'96' ], '北京' :['-1' ,'90' ], '上海' :['11' ,'85' ] } for city in data.keys(): print ("城市: " + city) 城市: 福建 城市: 北京 城市: 上海
values() 遍历值
1 2 3 4 5 6 7 8 9 10 11 12 data = { '福建' :['14' ,'96' ], '北京' :['-1' ,'90' ], '上海' :['11' ,'85' ] } for value in data.values(): print ("数值: " + str (value)) 数值: ['14' , '96' ] 数值: ['-1' , '90' ] 数值: ['11' , '85' ]
items() 遍历键值对
1 2 3 4 5 6 7 8 9 10 11 12 data = { '福建' :['14' ,'96' ], '北京' :['-1' ,'90' ], '上海' :['11' ,'85' ] } for city,value in data.items(): print ("{city}: 温度{temp}° 湿度{humi}%" .format (city=city,temp=value[0 ],humi=value[1 ])) 福建: 温度14 ° 湿度96 % 北京: 温度-1 ° 湿度90 % 上海: 温度11 ° 湿度85 %
修改字典 添加键值对
1 2 3 4 5 6 7 8 9 10 data = {'temp' :'14' ,'humi' :'96' } print ("添加前 " + str (data))data['city' ] = '福建' print ("添加后 " + str (data))添加前 {'temp' : '14' , 'humi' : '96' } 添加后 {'temp' : '14' , 'humi' : '96' , 'city' : '福建' }
修改值
1 2 3 4 5 6 7 8 9 10 data = {'temp' :'14' ,'humi' :'96' } print ("修改前 " + str (data))data['temp' ] = '15' print ("修改后 " + str (data))修改前 {'temp' : '14' , 'humi' : '96' } 修改后 {'temp' : '15' , 'humi' : '96' }
删除键值对
1 2 3 4 5 6 7 8 9 10 data = {'temp' :'14' ,'humi' :'96' } print ("删除前 " + str (data))del data['temp' ]print ("删除后 " + str (data))删除前 {'temp' : '14' , 'humi' : '96' } 删除后 {'humi' : '96' }
字典推导式 1 2 3 4 # 格式 {键:值 for 变量 in 列表} (键:值 for 变量 in range(数字范围)) (键:值 for 变量 in 列表 if 条件)
1 2 3 4 5 6 7 users = ['Jack' ,'Tom' ,'Giao' ] new_dict = {name:len (name) for name in users} print (new_dict){'Jack' : 4 , 'Tom' : 3 , 'Giao' : 4 }
1 2 3 4 5 6 new_dict = {num:num*2 for num in range (1 ,5 )} print (new_dict){1 : 2 , 2 : 4 , 3 : 6 , 4 : 8 }
1 2 3 4 5 6 new_dict = {num:num*2 for num in range (1 ,5 ) if num != 3 } print (new_dict){1 : 2 , 2 : 4 , 4 : 8 }
函数 介绍
函数是组织好的,可以重复利用的代码块。函数代码块以def关键词开头,后面接上函数名和小括号,任何传入函数的参数都必须放在小括号中
函数定义 示例代码
1 2 3 4 5 6 7 8 9 def echo_name (): print ("Hello Jack" ) echo_name() Hello Jack
传参 实参、形参
1 2 3 4 5 def 函数名(形参 ): pass 函数名(实参)
传递一个实参
1 2 3 4 5 6 7 def echo_name (name ): print ("Hello" + str (name)) echo_name("Jack" ) Hello Jack
传递多个实参
1 2 3 4 5 6 7 def echo_name (name, age ): print ("你好%s,你今年已经%s岁了!" % (str (name),str (age))) echo_name("Jack" , 10 ) 你好Jack,你今年已经10 岁了!
关键字传递
1 2 3 4 5 6 7 def echo_name (name, age ): print ("你好%s,你今年已经%s岁了!" % (str (name),str (age))) echo_name(name="Jack" , age=10 ) 你好Jack,你今年已经10 岁了!
默认值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def echo_name (name, age=0 ): if age != 0 : print ("你好%s,你今年已经%s岁了!" % (str (name), str (age))) else : print ("你好%s" % str (name)) echo_name(name="Jack" ) echo_name(name="Jack" , age=10 ) 你好Jack 你好Jack,你今年已经10 岁了!
传递任意数量的实参
1 2 3 4 5 6 7 8 9 10 11 def echo_name (*name ): print (name) echo_name("Jack" ) echo_name("Jack" , "Jerry" ) ('Jack' ,) ('Jack' , 'Jerry' )
函数接受不同类型的实参,必须在函数定义中把接纳任意数量实参的形参放在最后,如: 形参1,形参2,任意数量的形参
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 def echo_name (date, *name ): print ("今年是%s年" % str (date)) for n in name: print ("Hello " + str (n)) echo_name("2022" , "Jack" ) echo_name("2022" , "Jack" , "Jerry" , "Tom" ) 今年是2022 年 Hello Jack 今年是2022 年 Hello Jack Hello Jerry Hello Tom
传递任意数量的关键字实参
定义接收任意数量的关键字实参的形参只需要在形参前面加上**,传递进来的实参会以字典的方式进行存储。一定要把接受任意数量的关键字实参的形参放后面
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 def echo_users (age, name, **other ): user_data = { 'age' : age, 'name' : name } print ("任意数量的关键字实参数据类型为: " + str (type (other))) for key,value in other.items(): user_data[key] = value print (user_data) echo_users("10" , "Jack" ) echo_users("10" , "Jack" , email="xx@xx.com" ) echo_users("10" , "Jack" , email="xx@xx.com" , qq="123456" ) 任意数量的关键字实参数据类型为: <class 'dict '> {'age ': '10' , 'name' : 'Jack' }任意数量的关键字实参数据类型为: <class 'dict '> {'age ': '10' , 'name' : 'Jack' , 'email' : 'xx@xx.com' }任意数量的关键字实参数据类型为: <class 'dict '> {'age ': '10' , 'name' : 'Jack' , 'email' : 'xx@xx.com' , 'qq' : '123456' }
传递列表
函数不仅可以接收字符串、数字的实参,还可以接收字典、列表、元组等序列的实参
1 2 3 4 5 6 7 8 9 10 def echo_name (names ): for name in names: print ("Hello " + name) echo_name(['Jack' ,'Tom' ,'Jerry' ]) Hello Jack Hello Tom Hello Jerry
返回值 可以将函数理解为一个为你工作的工人,返回值相当于该工人干完活后呈现给你的劳动成果。返回值return只要被执行一次就会直接结束该函数的运行
1 2 3 4 5 6 7 8 9 10 11 12 def echo_name (name ): txt = "Hello " + str (name) return txt echo_name("Jack" ) back_data = echo_name("Jack" ) print (back_data)Hello Jack
1 2 3 4 5 6 7 8 9 10 11 def echo_name (name ): txt = "Hello " + str (name) return txt print ("Hi" ) print (echo_name("Jack" ))Hello Jack
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 def echo_users (age, name ): user_data = { 'age' : age, 'name' : name } return user_data data = echo_users("10" , "Jack" ) print (type (data))print (data)<class 'dict '> {'age ': '10' , 'name' : 'Jack' }
全局变量
全局变量是在函数外定义的变量,函数内定义的变量是局部变量,函数内可以直接访问全局变量,同名的局部变量会覆盖掉全局变量,函数内修饰全局变量用global关键词。全局变量并非真全局,只是在模块内全局
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 num = 10 def d (): global num print ("函数内修改前打印: " + str (num)) num = 100 print ("函数内修改后打印: " + str (num)) d() print ("函数内修改后外部打印: " + str (num))函数内修改前打印: 10 函数内修改后打印: 100 函数内修改后外部打印: 100
下方测试内容为: 函数内不用global修视全局变量是否能够修改全局变量
1 2 3 4 5 6 7 8 9 10 num = 10 def a (): print (a) a() 10
1 2 3 4 5 6 7 8 9 10 11 12 num = 10 def b (): print ("修改前: " + str (num)) num = 100 print ("修改后: " + str (num)) b() 报错
1 2 3 4 5 6 7 8 9 10 11 12 13 num = 10 def c (): num = 100 print ("函数内修改后打印: " + str (num)) c() print ("函数内修改后外部打印: " + str (num))函数内修改后打印: 100 函数内修改后外部打印: 10
匿名函数
匿名函数也是函数的一种,但匿名函数只能是一种表达式,返回值就是表达式的结果。匿名函数不需要对函数进行定义,在调用匿名函数时只能先复制给变量后才能进行调用匿名函数的返回结果。匿名函数使用lambda进行修饰
定义匿名函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 def test (num ): return num ** 2 back_data = lambda num: num ** 2 print ("普通函数结果: " + str (test(10 )))print ("匿名函数结果: " + str (back_data(10 )))100 100
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 def test (num, num2 ): if num >= num2: return num - num2 else : return num + num2 back_data = lambda num, num2: num - num2 if num >= num2 else num + num2 print ("普通函数结果: " + str (test(10 , 20 )))print ("匿名函数结果: " + str (back_data(10 , 20 )))30 30
1 2 3 4 5 6 7 8 9 10 11 12 13 list_data = [3 ,2 ,5 ,4 ,1 ] list_data.sort(key=lambda x:x) print ("列表排序后: " + str (list_data))dict_data = [{"index" :3 },{"index" :1 },{"index" :2 }] dict_data.sort(key=lambda x:x['index' ]) print ("字典排序后: " + str (dict_data))列表排序后: [1 , 2 , 3 , 4 , 5 ] 字典排序后: [{'index' : 1 }, {'index' : 2 }, {'index' : 3 }]
后面传参
1 2 3 4 5 6 7 8 back_data = (lambda num: num ** 2 )(10 ) print ("匿名函数结果: " + str (back_data))100
默认值
默认值需要在非默认值的后边,默认值可以被实参覆盖
1 2 3 4 5 6 7 8 back_data = (lambda num,num2=2 : num ** num2)(10 ) print ("匿名函数结果: " + str (back_data))100
导入函数
函数最大的优点就是可以将代码块与主程序分离,也可以将函数存储到独立文件中,再通过import将模块导入主程序中进行调用
导入整个模块
创建两个py文件,一个为主程序,一个为模块,两个文件都在同一个文件夹内,再将模块导入到主程序中
1 2 3 4 5 6 7 def echo_name (name ): print ("Hello " + name) def echo_date (): print ("今年是2022年" )
1 2 3 4 5 6 7 8 9 10 11 import mod_testmod_test.echo_name("Jack" ) mod_test.echo_date() Hello Jack 今年是2022 年
导入特定函数
1 2 3 4 5 6 7 def echo_name (name ): print ("Hello " + name) def echo_date (): print ("今年是2022年" )
1 2 3 4 5 6 7 8 9 10 11 from mod_test import echo_name,echo_dateecho_name("Jack" ) echo_date() Hello Jack 今年是2022 年
导入所有函数
1 2 3 4 5 6 7 def echo_name (name ): print ("Hello " + name) def echo_date (): print ("今年是2022年" )
1 2 3 4 5 6 7 8 9 10 11 from mod_test import *echo_name("Jack" ) echo_date() Hello Jack 今年是2022 年
指定别名
如果觉得模块与函数名过长,或与主程序的函数或模块名冲突,可以为函数或模块指定别名
1 2 3 4 5 6 7 def echo_name (name ): print ("Hello " + name) def echo_date (): print ("今年是2022年" )
1 2 3 4 5 6 7 8 9 10 11 12 from mod_test import echo_name as e_nfrom mod_test import echo_date as e_de_n("Jack" ) e_d() Hello Jack 今年是2022 年
1 2 3 4 5 6 7 8 9 10 11 import mod_test as testtest.echo_name("Jack" ) test.echo_date() Hello Jack 今年是2022 年
导入不同位置的模块
上述实验中的模块与主程序都是在同一个文件夹内,可以直接导入。而在不同文件夹的模块与主程序则需要在模块的文件夹下创建一个__init__.py的空文件后该模块才能被调用
1 2 3 4 5 6 7 8 # 文件结构声明 # 在文件夹mod(该文件夹被称为包)中分别存放文件__init__.py(空文件)与mod_test.py(需要导入的模块) # 与文件夹mod同级的目录中存放着主程序main.py |-- mod | |-- __init__.py | |-- mod_test.py |-- main.py
1 2 3 4 5 6 7 8 def echo_name (name ): print ("Hello " + name) def echo_date (): print ("今年是2022年" )
1 2 3 4 5 6 7 8 9 10 import mod.mod_testmod_test.echo_name("Jack" ) mod_test.echo_date() Hello Jack 今年是2022 年
导入父目录下不同文件夹的模块
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 # 文件结构声明 # 在文件夹mod中分别存放文件__init__.py(空文件)与mod_test.py(需要导入的模块) # 在文件夹main中存放着主程序main.py |-- mod | |-- __init__.py | |-- mod_test.py |-- main | |-- main.py # 导入方法 需要通过sys.path.append()将上级目录添加到python的系统路径中,再导入包 """ 导入格式: from 文件夹 import 模块名 调用格式: 模块名.函数名(实参) 导入格式: import 文件夹.模块名 调用格式: 文件夹.模块名.函数名(实参) 导入格式: from 文件夹 import * 在包目录下的__init__.py需要通过 __all__ = ['模块名'] 来指定模块名才能导入所有模块 调用格式: 模块名.函数名(实参) 导入格式: from 文件夹.模块名 import 函数名 调用格式: 函数名(实参) """
1 2 3 4 5 6 7 def echo_name (name ): print ("Hello " + name) def echo_date (): print ("今年是2022年" )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import syssys.path.append(".." ) from mod import mod_testmod_test.echo_name("Jack" ) mod_test.echo_date() Hello Jack 今年是2022 年
面向对象 介绍 面向对象编程
面向对象编程是最有效的软件编程方法之一。在面向对象编程中可以将具有共同特征的事物或很多相似的个体组合成一个类,并基于这些类来创建对象,根据类来创建的对象被称为实例化。
基本理论
类 : 类是具有相同属性和方法的一类事物的抽象化描述,可以将具有共同特征的事物或很多相似的个体组合成一个类实例化 : 根据类来创建的对象被称为实例化方法 : 类中定义的函数称为方法类变量 : 类变量在整个实例化对象中是公用的,类变量定义在类中且在函数体之外,类变量通常不作为实例变量使用局部变量 : 在方法中定义的变量,该变量只能在当前实例的类中使用实例变量 : 在类中通过self关键词进行修饰的变量,属性是用实例变量来表示的,该变量只能用作调用方法的对象
类定义 语法格式
在Python中定义类最好使用大驼峰命名法(所有单词首字母大写)来定义类名,每个方法之间应当空两行。(文章中为了方便阅读可能不按照规范来写,但在日常项目中最好规范编程)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class 类名(object """描述该类的作用或功能(为代码规范性)""" 类变量 = 值 def 函数1(self,形参2 ,形参3 ): """描述该方法的作用或功能(为代码规范性)""" 局部变量 = 值 self.实例变量名 = 值 其他代码块 def 函数1(self,形参2 ,形参3 ): 函数代码块 实例名 = 类名() 实例名.类变量 实例名.方法名()
一个简单的实例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class NewClass (object """类实例编写学习""" num = 666 def test (self ): """返回字符串Hello World""" return "Hello World" new_class = NewClass() print ("NewClass类中的属性num为: " ,new_class.num)print ("NewClass类中的方法test输出: " ,new_class.test())NewClass类中的属性num为: 666 NewClass类中的方法test输出: Hello World
__init__() 方法
在类中有一个名为__init__()的特殊方法(构造方法),每当创建新实例时该方法就会自动被调用。可以通过该方法对实例变量进行传参或者在该方法下定义其他的实例变量
在下方示例代码中对__init__()方法定义了两个形参(self,name),而Python调用__init__()方法时会自动传递实参给self,因此形参self无需进行传参。在实例化类时对形参name进行传参,形参name再把接收到的实参赋值给实例变量self.name,在sit()方法中调用self.name变量。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 class Dog (object """模拟小狗的一些行为""" __sex = "" def __init__ (self,name ): self.name = name self.__sex = "男" self.age = 0 def sit (self ): """模拟小狗被命令蹲下时""" print (f"{self.name} 蹲下!" ) dog = Dog("小黑" ) print (f"这只狗叫{dog.name} " )dog.sit() dog_2 = Dog("小白" ) print (f"这只狗叫{dog_2.name} " )dog_2.sit() 这只狗叫小黑 小黑蹲下! 这只狗叫小黑 小白蹲下!
修改属性值 直接修改属性值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class Test (object """直接修改实例属性""" num = 10 def __init__ (self ): self.age = 20 test = Test() print ("修改前num: " + str (test.num))print ("修改前age: " + str (test.age))test.num = 100 test.age = 200 print ("修改前num: " + str (test.num))print ("修改后age: " + str (test.age))修改前num: 10 修改前age: 20 修改前num: 100 修改后age: 200
通过方法修改属性值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class Test (object """直接修改实例属性""" def __init__ (self ): self.age = 20 def update_age (self,age ): self.age = age test = Test() print ("修改前age: " + str (test.age))test.update_age(200 ) print ("修改后age: " + str (test.age))修改前age: 20 修改后age: 200
继承 介绍
继承指的是在创建类(子类)时可以指定继承一个已经存在的类(父类),子类就拥有了父类的所有属性与方法,同时子类还可以定义自己的属性与方法。父类的初始化方法需要在子类实现,可以使用super()调用父类中的初始化方法__init__()。在多继承时使用父类名来调用父类中的初始方法(不用super())
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 """ 在子类的初始化方法中定义形参 父类初始化方法中有几个形参,子类初始化方法中就要定义几个形参用于传参给父类(除非父类形参有默认值) """ class 子类名(父类名 ): def __init__ (self,形参2 ,形参3 ,形参4 ,形参5 ): super ().__init__(形参2 ,形参3 ) 父类名.__init__(self,形参2 ,形参3 ) class 子类名(父类名、父类名2 、父类名3 ): def __init__ (self,形参2 ,形参3 ,形参4 ,形参5 ): 父类名.__init__(self,形参2 ,形参3 ) 父类名2. __init__(self,形参4 )
单继承
一个子类继承一个父类的属性与方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 class Anumal (object """所有的动物的基本习性""" def __init__ (self,name,age ): self.name = name self.age = age def eat (self ): print (self.name + "在吃饭" ) def drink (self ): print (self.name + "在喝水" ) def age (self ): print (f"{self.name} 今年{self.age} 岁了" ) class Cat (Anumal ): """猫的基本习性""" def __init__ (self,name,age,say ): super ().__init__(name,age) self.say = say def speak (self ): print (self.name + self.say) cat = Cat("胖橘猫" ,"2" ,"喵喵喵" ) cat.eat() cat.speak() 胖橘猫在吃饭 胖橘猫喵喵喵
多继承
一个子类继承多个父类的属性与方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 class Anumal (object """所有的动物的基本习性""" x = "Anumal" def __init__ (self,name,age ): self.name = name self.age = age def eat (self ): print (self.name + "在吃饭" ) def drink (self ): print (self.name + "在喝水" ) def age (self ): print (f"{self.name} 今年{self.age} 岁了" ) class Speak (object """所有动物的叫声""" xx = "Speak" def __init__ (self,say ): self.say = say def speak (self ): print (self.say) class Cat (Anumal,Speak ): """猫的基本习性""" def __init__ (self,name,age,say,xxx ): Anumal.__init__(self,name,age) Speak.__init__(self,say) self.people_name = xxx def hello (self ): print ("Hello " + self.people_name) cat = Cat("胖橘猫" ,"2" ,"喵喵喵" ,"Jack" ) cat.eat() cat.speak() cat.hello() print (cat.x) print (cat.xx) 胖橘猫在吃饭 喵喵喵 Hello Jack Anumal Speak
方法重写
如果从父类继承的方法不能满足类的需求时,可以对父类方法进行修改(重写覆盖),只需要在子类中定义与父类方法同名的方法即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 class Anumal (object """所有的动物的基本习性""" def __init__ (self,name,age ): self.name = name self.age = age def eat (self ): print (self.name + "在吃饭(父类)" ) class Cat (Anumal ): """猫的基本习性""" def __init__ (self,name,age,say ): super ().__init__(name,age) self.say = say def eat (self ): print (self.name + "在吃大餐(子类)" ) cat = Cat("胖橘猫" ,"2" ,"喵喵喵" ) cat.eat() super (Cat,cat).eat() 胖橘猫在吃大餐(子类) 胖橘猫在吃饭(父类)
导入类 导入整个模块
创建两个py文件,一个为主程序,一个为模块,两个文件都在同一个文件夹内,再将模块导入到主程序中
1 2 3 4 5 6 7 8 class Dog (object def get_name (self ): print ("Dog" ) class Cat (object def get_name (self ): print ("Cat" )
1 2 3 4 5 6 7 import mod_testcat = mod_test.Cat() cat.get_name()
导入特定类
1 2 3 4 5 6 7 from mod_test import Catcat = Cat() cat.get_name()
导入所有类
1 2 3 4 5 6 7 from mod_test import *cat = Cat() cat.get_name()
指定别名
1 2 3 4 5 6 7 import mod_test as m_tcat = m_t.Cat() cat.get_name()
1 2 3 4 5 6 7 from mod_test import Cat as CatCatcat = CatCat() cat.get_name()
导入不同位置的类
上述实验中的模块与主程序都是在同一个文件夹内,可以直接导入。而在不同文件夹的模块与主程序则需要在模块的文件夹下创建一个__init__.py的空文件后该模块才能被调用
1 2 3 4 5 6 7 8 # 文件结构声明 # 在文件夹mod(该文件夹被称为包)中分别存放文件__init__.py(空文件)与mod_test.py(需要导入的模块) # 与文件夹mod同级的目录中存放着主程序main.py |-- mod | |-- __init__.py | |-- mod_test.py |-- main.py
1 2 3 4 5 6 7 from mod import mod_testcat = mod_test.Cat() cat.get_name()
导入父目录下不同文件夹的模块
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 # 文件结构声明 # 在文件夹mod中分别存放文件__init__.py(空文件)与mod_test.py(需要导入的模块) # 在文件夹main中存放着主程序main.py |-- mod | |-- __init__.py | |-- mod_test.py |-- main | |-- main.py # 导入方法 需要通过sys.path.append()将上级目录添加到python的系统路径中,再导入包 """ 导入格式: from 文件夹 import 模块名 调用格式: 模块名.类名(实参) 导入格式: import 文件夹.模块名 调用格式: 文件夹.模块名.类名(实参) 导入格式: from 文件夹 import * 在包目录下的__init__.py需要通过 __all__ = ['模块名'] 来指定模块名才能导入所有模块 调用格式: 模块名.类名(实参) 导入格式: from 文件夹.模块名 import 类名 调用格式: 类名(实参) """
1 2 3 4 5 6 7 8 import syssys.path.append(".." ) from mod import mod_testcat = mod_test.Cat() cat.get_name()
文件操作 方法与属性 常用方法
方法
描述
open(路径,模式,编码)
打开文件
close()
关闭文件
read(读取的字节数)
读取整个文件,不指定字节数则为全部
readline(读取的字节数)
逐行读取文件(包括换行符\n),不指定字节数则为整行
readlines()
逐行读取文件,返回列表(包括换行符\n)
write(写入内容 )
写入文件
open() 模式
模式
描述
r
只读
w
写入(覆盖)
a
写入(追加)
r+
读写
rb
以二进制打开文件,只读
wb
以二进制打开文件,写入(覆盖)
ab
以二进制打开文件,写入(追加)
wb+
以二进制打开文件,读写
文件属性
属性
描述
name
文件路径
encoding
文件编码
mode
文件模式
closed
文件状态(是否关闭)
读取文件 介绍
在Pythonh中对文件进行操作时,最好使用with来打开文件,当执行完成后自动关闭文件,避免忘记关闭文件导致资源的占用。文件的路径可以是绝对(C:/XX/XX)或相对路径(../../XX)
读取文件
1 2 3 4 5 6 7 8 9 10 11 fp = open (文件路径,模式,文件编码) data = fp.read() fp.write(内容) fp.close() with open (文件路径,模式,文件编码) as 别名: data = fp.read() fp.write(内容)
读取整个文件
1 2 3 4 # 1.txt 咏鹅 鹅,鹅,鹅,曲项向天歌。 白毛浮绿水,红掌拨清波。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 with open ('1.txt' ,'r' ,encoding='UTF-8' ) as f: txt = f.read() print ("文件路径: %s" % f.name) print ("文件编码: %s" % f.encoding) print ("文件模式: %s" % f.mode) print ("文件是否关闭: %s" % f.closed) print ("----------" )print (txt)文件路径: 1. txt 文件编码: UTF-8 文件模式: r 文件是否关闭: False ---------- 咏鹅 鹅,鹅,鹅,曲项向天歌。 白毛浮绿水,红掌拨清波。
逐行读取
1 2 3 4 5 6 7 8 9 10 11 12 with open ('1.txt' ,'r' ,encoding='UTF-8' ) as f: print (f.readline()) print (f.readline()) print (f.readline(2 )) 咏鹅 鹅,鹅,鹅,曲项向天歌。 白毛
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 with open ('1.txt' ,'r' ,encoding='UTF-8' ) as f: txt_list = f.readlines() print (txt_list)print ("----------------" )print ('' .join(txt_list))['咏鹅\n' , '鹅,鹅,鹅,曲项向天歌。\n' , '白毛浮绿水,红掌拨清波。' ] ---------------- 咏鹅 鹅,鹅,鹅,曲项向天歌。 白毛浮绿水,红掌拨清波。
1 2 3 4 5 6 7 8 9 10 11 12 with open ('1.txt' ,'r' ,encoding='UTF-8' ) as f: for line in f: print (line) 咏鹅 鹅,鹅,鹅,曲项向天歌。 白毛浮绿水,红掌拨清波。
判断文件中是否包含某个字符
1 2 3 4 5 6 7 8 9 with open ('1.txt' ,'r' ,encoding='UTF-8' ) as f: txt_list = f.readlines() txt = '' .join(txt_list) if "咏鹅" in txt: print ("存在" ) 存在
1 2 3 4 5 6 7 8 with open ('1.txt' , 'r' , encoding='UTF-8' ) as f: txt_list = [txt.strip() for txt in f.readlines()] if "咏鹅" in txt_list: print ("存在" ) 存在
替换字符
1 2 3 4 5 6 7 8 9 10 11 with open ('1.txt' ,'r' ,encoding='UTF-8' ) as f: txt_list = f.readlines() txt = '' .join(txt_list) txt = txt.replace('鹅' ,'鸭' ) print (txt)咏鸭 鸭,鸭,鸭,曲项向天歌。 白毛浮绿水,红掌拨清波。
文件位置
UTF-8编码一个汉字占三个字节,一个英文占一个字节
1 2 3 4 5 6 7 8 9 10 11 with open ('1.txt' , 'r' , encoding='UTF-8' ) as f: print (f.read(1 )) print ("当前位置: %s" % f.tell()) print (f.read(1 )) print ("当前位置: %s" % f.tell()) 咏 当前位置: 3 鹅 当前位置: 6
写入文件 创建并写入
1 2 3 4 5 6 7 8 with open ('2.txt' ,'w' ,encoding='UTF-8' ) as f: f.write("Hello" ) with open ('2.txt' ,'r' ,encoding='UTF-8' ) as f: print (f.read()) Hello
写入多行
1 2 3 4 5 6 7 8 9 10 11 12 13 with open ('2.txt' ,'w' ,encoding='UTF-8' ) as f: f.write("Hello" ) f.write("World\n" ) f.write("Hi\nJack" ) with open ('2.txt' ,'r' ,encoding='UTF-8' ) as f: print (f.read()) HelloWorld Hi Jack
追加内容
1 2 3 4 5 6 7 8 9 10 11 12 13 """2.txt HelloWorld """ with open ('2.txt' ,'a' ,encoding='UTF-8' ) as f: f.write("\nHi" ) with open ('2.txt' ,'r' ,encoding='UTF-8' ) as f: print (f.read()) HelloWorld Hi
写入图片
1 2 3 4 5 6 7 8 9 10 11 12 import requestsimg_url = "https://img-home.csdnimg.cn/images/20201124032511.png" img_data = requests.get(img_url).content with open ('csdn_log.png' ,'wb' ) as f: f.write(img_data) print ("下载完成" )
操作多文件
当with表达式需要使用三个及以上时,使用\换行。使用两个with表达式时进行嵌套with
两个文件
1 2 3 4 with open ('1.txt' ,'r' ,encoding='UTF-8' ) as f1: with open ('2.txt' ,'r' ,encoding='UTF-8' ) as f2: print (f1.read()) print (f2.read())
两个以上
1 2 3 4 5 6 with open ('1.txt' , 'r' , encoding='UTF-8' ) as f1, \ open ('2.txt' , 'r' , encoding='UTF-8' ) as f2, \ open ('3.txt' , 'w' , encoding='UTF-8' ) as f3: print (f1.read()) print (f2.read()) f3.write("Hello" )
n个文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 def read_file (file_name ): """读取文件内容""" try : with open (file_name,'r' ,encoding="utf-8" ) as f: txt = f.read() except FileNotFoundError: return "No File: %s" % file_name return f.name,txt files = ['1.txt' ,'2.txt' ,'xx.txt' ] for file in files: file_info = read_file(file) print ("文件: %s" % file_info[0 ]) print (file_info[1 ])
异常处理 介绍
当Python无法正常处理程序时,就会发生一个异常,并导致程序停止运行。捕捉异常可以使用try/except语句,在try代码块中尝试执行可能产生异常的代码,except代码块用来捕获异常信息并进行处理
总所周知0不能作为除数,在Python中将0作为除数时代码就会抛出异常(异常位置、异常类型、异常解释),程序也终止了,若不想让程序终止则可以使用try/except语句捕获处理异常
异常类型 下表引用自菜鸟教程
异常名称
描述
BaseException
所有异常的基类
SystemExit
解释器请求退出
KeyboardInterrupt
用户中断执行(通常是输入^C)
Exception
常规错误的基类
StopIteration
迭代器没有更多的值
GeneratorExit
生成器(generator)发生异常来通知退出
StandardError
所有的内建标准异常的基类
ArithmeticError
所有数值计算错误的基类
FloatingPointError
浮点计算错误
OverflowError
数值运算超出最大限制
ZeroDivisionError
除(或取模)零 (所有数据类型)
AssertionError
断言语句失败
AttributeError
对象没有这个属性
EOFError
没有内建输入,到达EOF 标记
EnvironmentError
操作系统错误的基类
IOError
输入/输出操作失败
OSError
操作系统错误
WindowsError
系统调用失败
ImportError
导入模块/对象失败
LookupError
无效数据查询的基类
IndexError
序列中没有此索引(index)
KeyError
映射中没有这个键
MemoryError
内存溢出错误(对于Python 解释器不是致命的)
NameError
未声明/初始化对象 (没有属性)
UnboundLocalError
访问未初始化的本地变量
ReferenceError
弱引用(Weak reference)试图访问已经垃圾回收了的对象
RuntimeError
一般的运行时错误
NotImplementedError
尚未实现的方法
SyntaxError
Python 语法错误
IndentationError
缩进错误
TabError
Tab 和空格混用
SystemError
一般的解释器系统错误
TypeError
对类型无效的操作
ValueError
传入无效的参数
UnicodeError
Unicode 相关的错误
UnicodeDecodeError
Unicode 解码时的错误
UnicodeEncodeError
Unicode 编码时错误
UnicodeTranslateError
Unicode 转换时错误
Warning
警告的基类
DeprecationWarning
关于被弃用的特征的警告
FutureWarning
关于构造将来语义会有改变的警告
OverflowWarning
旧的关于自动提升为长整型(long)的警告
PendingDeprecationWarning
关于特性将会被废弃的警告
RuntimeWarning
可疑的运行时行为(runtime behavior)的警告
SyntaxWarning
可疑的语法的警告
UserWarning
用户代码生成的警告
异常处理 单个异常
1 2 3 4 5 6 7 8 try : 可能产生异常的代码块 except 异常类型: 发生异常后执行的代码块 else : 没发生异常执行的代码块
正常情况下0作为除数执行后程序会抛出异常并结束运行,当使用try/except语句对异常进行处理时,就可以避免程序因异常停止
1 2 3 4 5 6 7 8 9 10 11 12 13 14 num1 = int (input ("被除数: " )) num2 = int (input ("除数: " )) try : print (num1 / num2) except ZeroDivisionError: print ("0不能作为除数" ) print ("程序结束" )被除数: 10 除数: 0 0 不能作为除数程序结束
多个异常
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 try : 可能产生异常的代码块 except (异常类型1 ,异常类型2 ): 发生以上多个异常的一个后执行的代码块 else : 没发生异常执行的代码块 try : 可能产生异常的代码块 except 异常类型1 : 发生异常后执行的代码块 except 异常类型2 : 发生异常后执行的代码块 else : 没发生异常执行的代码块
当除数为0时就会抛出ZeroDivisionError: division by zero异常,当除数或被除数为空时就会抛出ValueError: invalid literal for int() with base 10: ''异常,如果不想因为这两个异常导致程序停止,就可以使用try/except语句处理可能发生的多个异常
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 try : num1 = int (input ("被除数: " )) num2 = int (input ("除数: " )) print (num1 / num2) except (ZeroDivisionError, ValueError): print ("Error: 输入错误或被除数为0" ) except : print ("未知异常" ) print ("程序结束" )被除数: 10 除数: Error: 输入错误或被除数为0 程序结束
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 try : try : num1 = int (input ("被除数: " )) num2 = int (input ("除数: " )) except ValueError: print ("Error: 输入错误" ) else : print (num1/num2) except ZeroDivisionError: print ("Error: 被除数为0" ) print ("程序结束" )被除数: 10 除数: Error: 输入错误 程序结束
所有异常
1 2 3 4 5 6 7 8 try : 可能产生异常的代码块 except BaseException: 发生异常后执行的代码块 else : 没发生异常执行的代码块
1 2 3 4 5 6 7 8 9 10 11 12 13 try : num1 = int (input ("被除数: " )) num2 = int (input ("除数: " )) print (num1 / num2) except BaseException: print ("程序异常" ) print ("程序结束" )被除数: 0 除数: 0 程序异常 程序结束
捕获异常信息
1 2 3 4 5 6 7 8 9 10 11 12 13 try : 可能产生异常的代码块 except 异常类型 as 异常别名: 发生以上多个异常的一个后执行的代码块 else : 没发生异常执行的代码块 异常别名.args str (异常别名) repr (异常别名)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 try : num1 = int (input ("被除数: " )) num2 = int (input ("除数: " )) print (num1 / num2) except (ZeroDivisionError, ValueError) as e: print ("Error: 输入错误或被除数为0" ) print ("--------------" ) print (e.args) print (str (e)) print (repr (e)) except : print ("未知异常" ) print ("程序结束" )被除数: 10 除数: 0 Error: 输入错误或被除数为0 -------------- ('division by zero' ,) division by zero ZeroDivisionError('division by zero' ) 程序结束
try/finally
1 2 3 4 5 6 7 8 9 10 try : 可能产生异常的代码块 except 异常类型: 发生以上多个异常的一个后执行的代码块 else : 没发生异常执行的代码块 finally : 不管有没有异常都执行的代码块
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 try : num1 = int (input ("被除数: " )) num2 = int (input ("除数: " )) print (num1 / num2) except (ValueError,ValueError): print ("Error: 输入错误或被除数为0" ) except : print ("未知异常" ) else : print ("无异常" ) finally : print ("有无异常不关我事" ) print ("程序结束" )被除数: 10 除数: Error: 输入错误或被除数为0 有无异常不关我事 程序结束
不处理异常
1 2 3 4 5 6 7 8 try : 可能产生异常的代码块 except 异常类型: pass else : 没发生异常执行的代码块
1 2 3 4 5 6 7 8 try : print (1 /0 ) except : pass print ("程序结束" )程序结束
抛出异常 语法
主动抛出异常
当用户输入的值不是你预期的数值时就可以主动抛出异常
1 2 3 4 5 6 7 8 9 10 11 12 num1 = int (input ("被除数: " )) num2 = int (input ("除数: " )) if num2 == 0 : raise ZeroDivisionError("被除数不能为0" ) 被除数: 10 除数: 0 Traceback (most recent call last): File "D:/Other/Code/python3/1/main/1.py" , line 4 , in <module> raise ZeroDivisionError("被除数不能为0" ) ZeroDivisionError: 被除数不能为0
1 2 3 4 5 6 7 8 9 num = 1 if num < 10 : raise Exception("num不能小于10; num: %s" % num) Traceback (most recent call last): File "D:/Other/Code/python3/1/main/1.py" , line 3 , in <module> raise Exception("num不能小于10; num: %s" % num) Exception: num不能小于10 ; num: 1
无需参数的raise
1 2 3 4 5 6 7 8 9 10 try : num = input ("整型: " ) if not num.isdigit(): raise ValueError("输入的值不是整型" ) except ValueError as e: print (repr (e)) 整型: a ValueError('输入的值不是整型' )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 try : num = input ("整型: " ) if not num.isdigit(): raise ValueError("输入的值不是整型" ) except ValueError as e: print (repr (e)) raise 整型: a ValueError('输入的值不是整型' ) Traceback (most recent call last): File "D:/Other/Code/python3/1/main/1.py" , line 4 , in <module> raise ValueError("输入的值不是整型" ) ValueError: 输入的值不是整型
自定义异常 介绍
可以创建一个异常类用于自定义异常,该类继承Exception类
语法
1 2 3 4 5 6 7 8 9 10 11 class 自定义异常类型(Exception ): def __init__ (self ): pass def __str__ (self ): return 异常返回值 raise 自定义异常类型(传参)
自定义异常
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class MyError (Exception ): """自定义异常""" def __init__ (self,value ): self.value = value num = 1 try : if num < 10 : raise MyError("num不能小于10" ) except MyError as e: print (e) num不能小于10
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class MyError (Exception ): def __init__ (self,value ): self.value = value self.message = "测试" def __str__ (self ): return self.message num = 1 try : if num < 10 : raise MyError("num不能小于10" ) except MyError as e: print (e) print (e.value) print (e.message) 测试 num不能小于10 测试


 wechat
wechat alipay
alipay