华为虚拟化主备容灾配置
实验环境
- 实验环境:O3社区· UltraVR虚拟化主备容灾解决方案实验
- UltraVR产品文档:OceanStor BCManager 8.5.0 UltraVR 产品文档
- 实验参考:O3社区· 分布式存储超融合容灾解决方案部署联调
- HyperReplication特性指南:https://support.huawei.com/enterprise/zh/doc/EDOC1000181461
- OceanStor BCManager下载:https://support.huawei.com/enterprise/zh/oceanprotect/bcmanager-pid-21597093/software
- UltraVR安装方式:https://support.huawei.com/hedex/hdx.do?docid=EDOC1100483007&id=ZH-CN_TOPIC_0000002075863357
本实验并非全部完整的实验,o3社区在本实验环境中提前创建了FusionCompute和存储的对接用户、存储的主机、存储的远端设备等;所以在真实场景中,建议参考UltraVR产品文档进行


基础知识
主备容灾与双活的区别
- 主备容灾是一主一备、故障切换;双活是双主并行、无缝接管
- 主备容灾(兜底保护):同一时间只有主端(生产端)运行业务,备端(灾备端)仅同步存储主端数据,处于 “待命” 状态,不对外提供服务
- 双活容灾(业务连续):主备两端(或多端)同时运行相同业务,均对外提供服务,数据实时同步,两端地位对等,无明显主备之分
基本概念
- UltraVR:是华为公司开发的对FusionCompute虚拟机进行保护、容灾的管理软件,通过存储复制(
HyperReplication)、存储双活两种方式,为FusionCompute虚拟化环境提供虚拟机级别的容灾保护 - 计划性迁移:当生产站点发生计划内风险(如停电、日常运维等)的情况下,可对指定的恢复计划执行计划性迁移,整个过程自动化,不需人工干预,自动完成灾备端业务接管
- 容灾测试:在不对生产站点的业务进行任何干扰的情况下,可对指定的恢复计划进行测试,实现恢复计划对受保护虚拟机的保护健康性进行测试,提前暴露风险,同时可完成对恢复计划RTO的测试及预估
- 清理测试数据:在不影响生产业务的情况下清理灾备站点的演练数据,还原至容灾演练前资源状态
- 重保护:在业务计划性迁移后进行容灾重保护,实现当生产站点设备恢复后,对灾备站点接管的业务进行反向保护(重新建立从主端到备端的数据复制关系)
- 故障恢复:当生产站点故障的情况下,可对指定的恢复计划执行故障恢复,整个过程自动化,不需人工干预,自动完成业务恢复
- 一致性组:指多个业务相关联的Pair的集合
- 例如:主端存储系统的三个主端卷分别存放某数据库的数据、日志和修改信息,任何一个卷的数据失效将导致三个卷中的数据整体无法使用。这三个卷所在的Pair构成的集合即是一个一致性组。在实际配置中,需要先创建一个一致性组,再手动将这三个Pair依次添加到已创建的一致性组中
- 上述案例,如果没有在主端存储系统创建一致性组,某个Pair没有同步成功,会导致主从端存储系统数据不一致
- 远程复制Pair:在生产存储(主LUN)和灾备存储(从LUN)之间的数据复制关系,基于两台存储设备之间的复制链路建立,在进行数据复制之前,必须先建立主LUN与从LUN之间的Pair关系;主端存储系统的一个主LUN和从端存储系统的一个从LUN构成一个Pair
- 正常状态:表示主LUN和从LUN的数据同步完成
- 分裂状态:表示主LUN和从LUN之间的数据复制暂停或中止
- 异常断开状态:远程复制所用的链路断开或远程复制主LUN或从LUN故障,数据展示无法同步
- 待恢复状态:当异常断开恢复后,且恢复策略为手动,则需要手动执行同步操作数据才会进行同步
- 失效状态:处于该状态的Pair无法使用且无法恢复,只能删除。需要在主从两端删除Pair,否则可能导致之后创建Pair失败
- 正在同步状态:主LUN向从LUN同步数据;此时从LUN不能被读写,如果此时发生灾难,则从LUN数据不能用于业务恢复
容灾原理
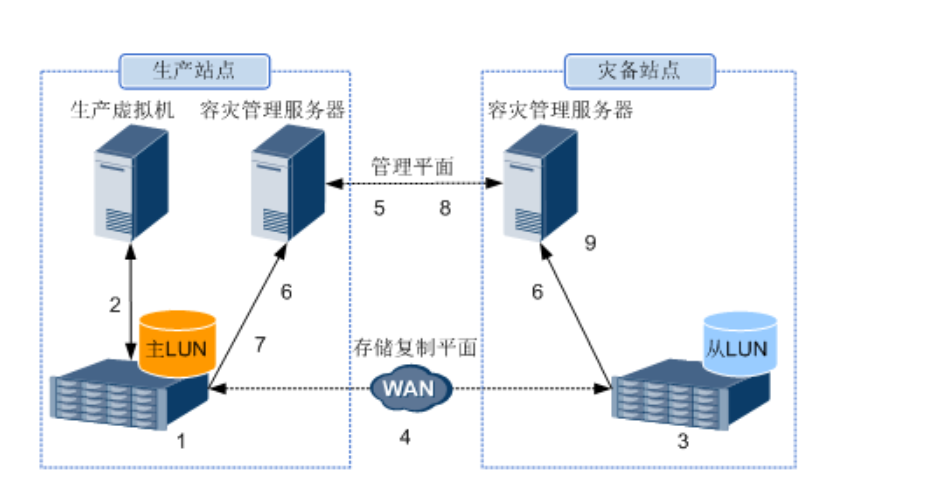
- 存储复制技术利用存储设备的远程复制功能,将生产中心存储上的业务数据远程复制到灾备中心,实现生产中心的数据复制和保护
- 当生产站点的主LUN和灾备站点的从LUN建立同步远程复制关系以后,会启动初始同步,也就是将主LUN数据全量拷贝到从LUN
存储复制保护流程
- 在生产站上创建LUN,并规格好需要容灾的主LUN
- 将需要保护的生产虚拟机通过存储迁移到规划好的主LUN上,或者直接安装到主LUN上
- 在灾备站点创建LUN,并规划好与主LUN同样大小的从LUN
- 存储设备间配置复制链路,配置LUN远程复制关系和一致性组
- 在容灾管理服务器中配置 生产站点和容灾站点的信息,并配置站点间的资源映射(集群映射和端口组映射)
- 注册存储设备,发现远程复制LUN与一致性组
- 创建存储保护组,选择受保护虚拟机,并设置保护策略
- 容灾保护相关配置数据同步
- 针对保护策略创建恢复计划
UltraVR安装
UltraVR主机安装
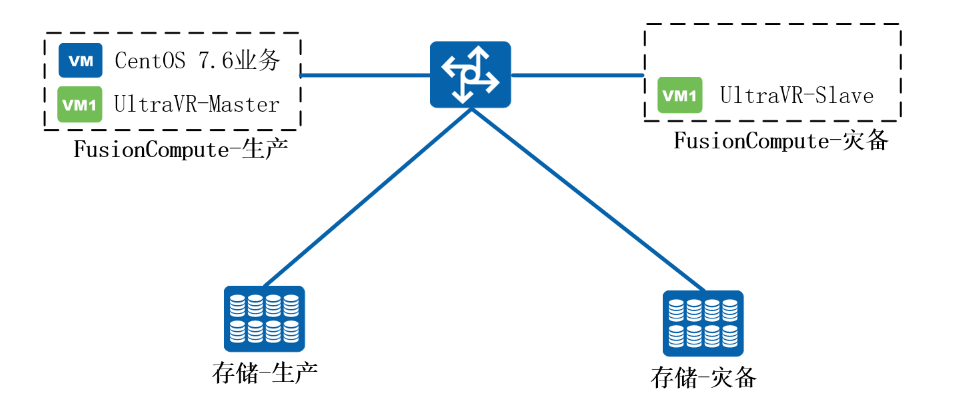
UltraVR可通过FusionCompute虚拟机模板安装和软件包安装两种方式,本实验采用虚拟机模板安装
- 在
生产站点和灾备站点的FusionCompute平台上安装并配置UltraVR主机IP地址
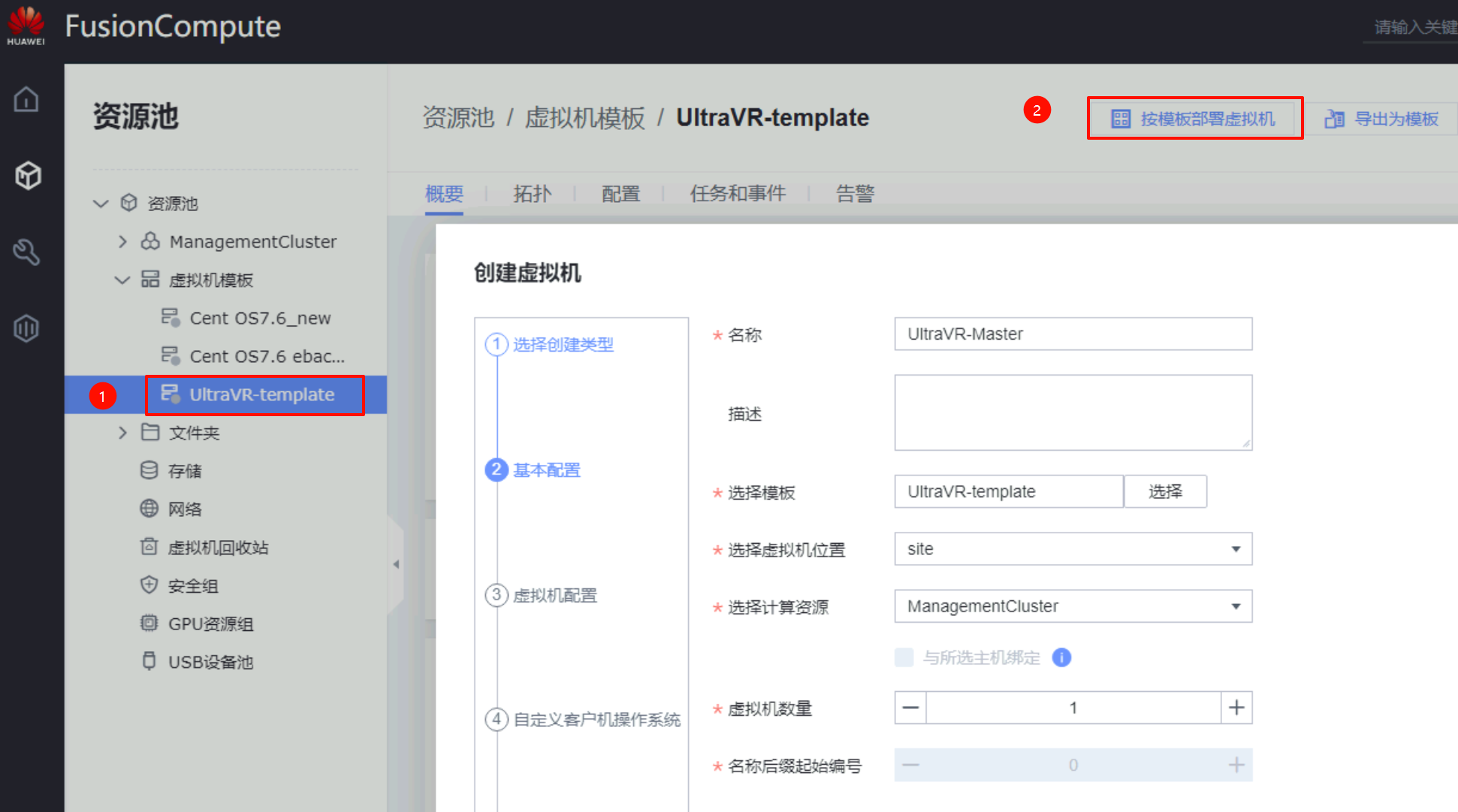
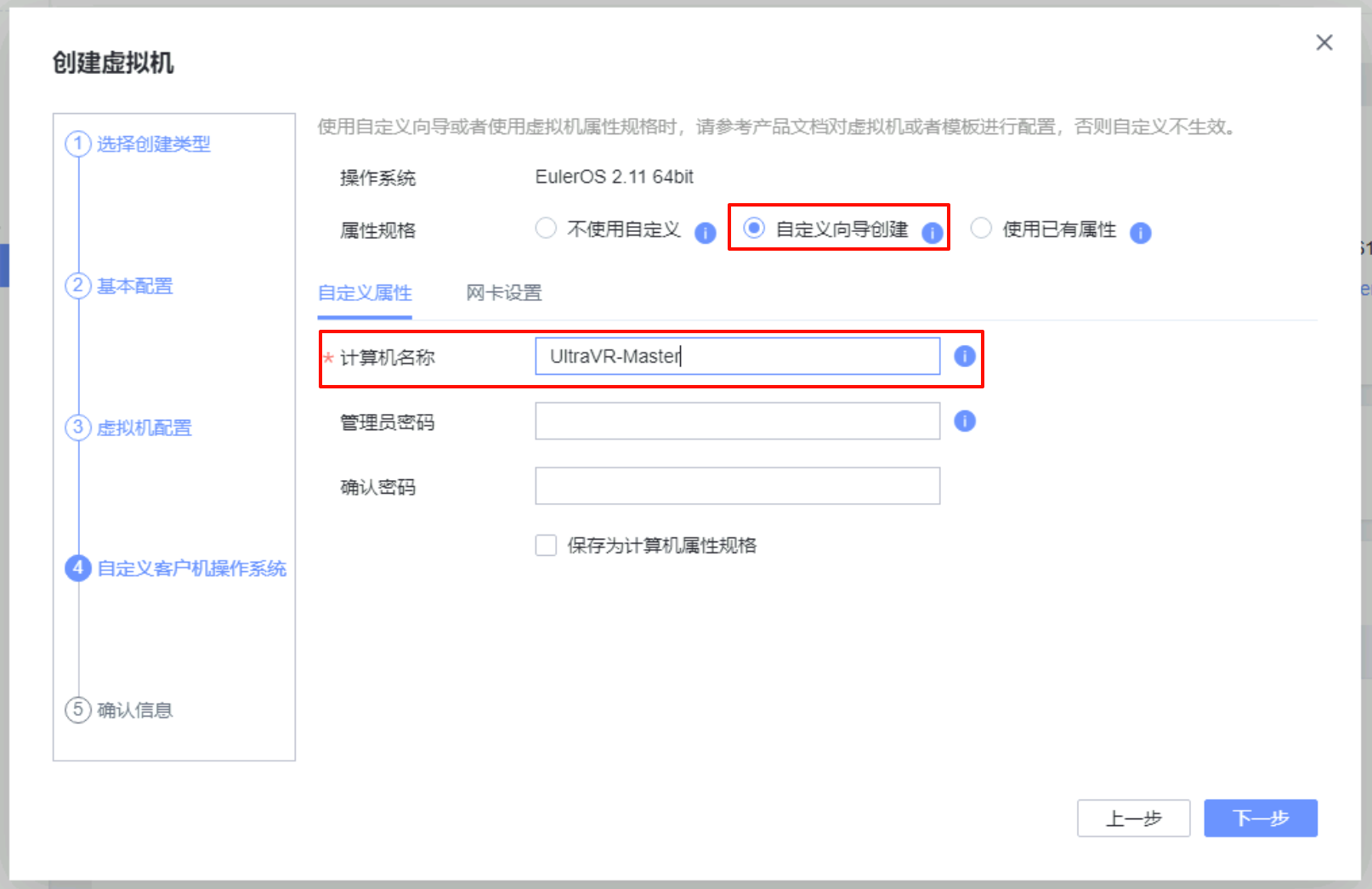
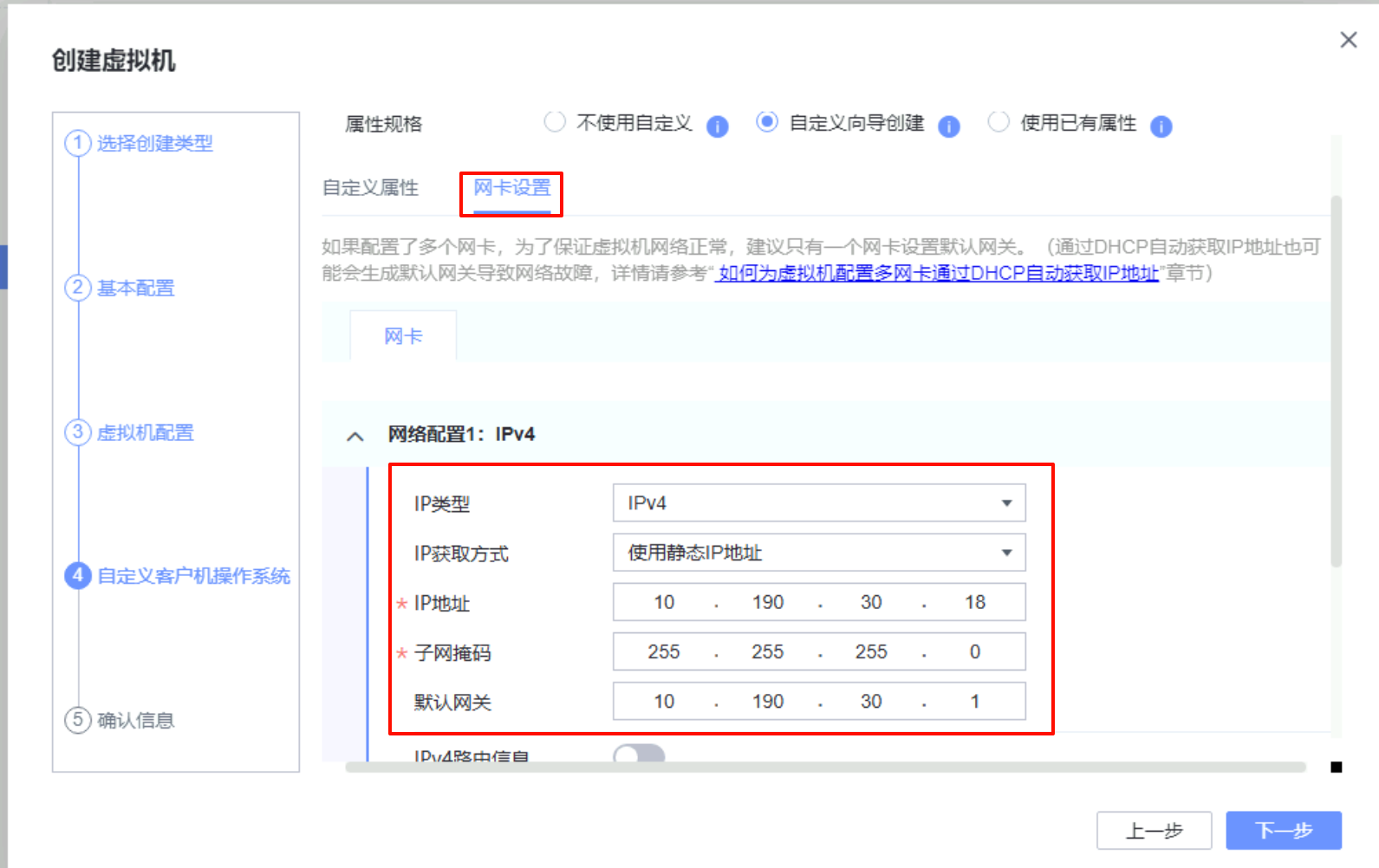
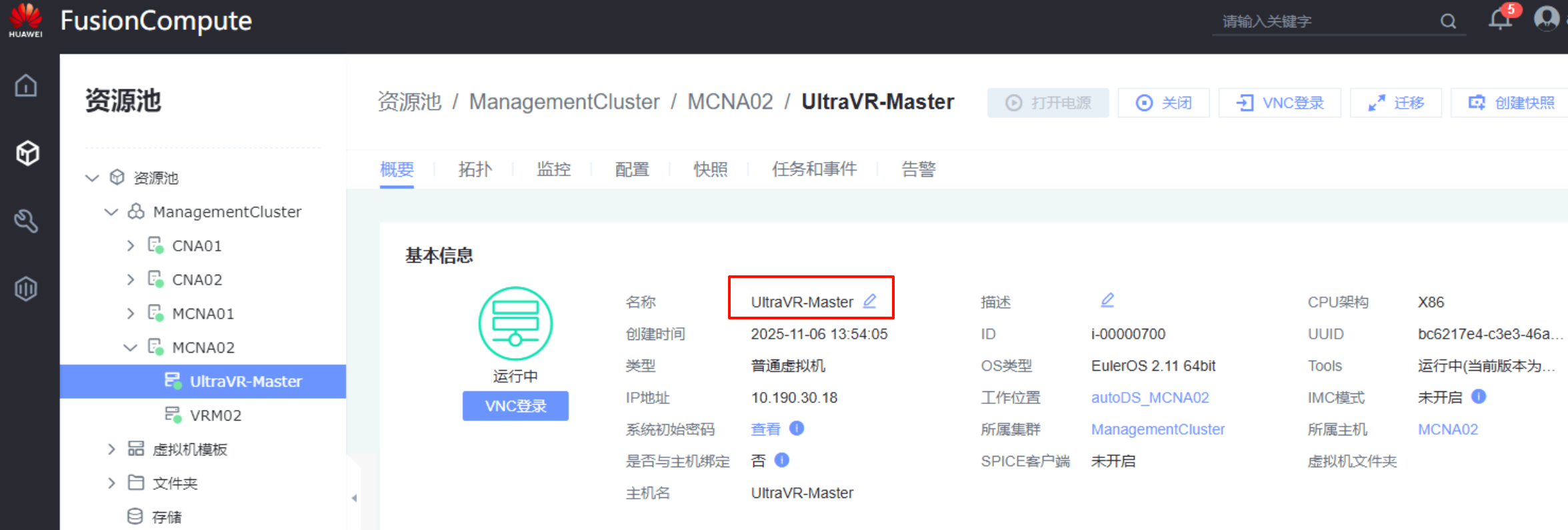
生产站点:UltraVR-Master
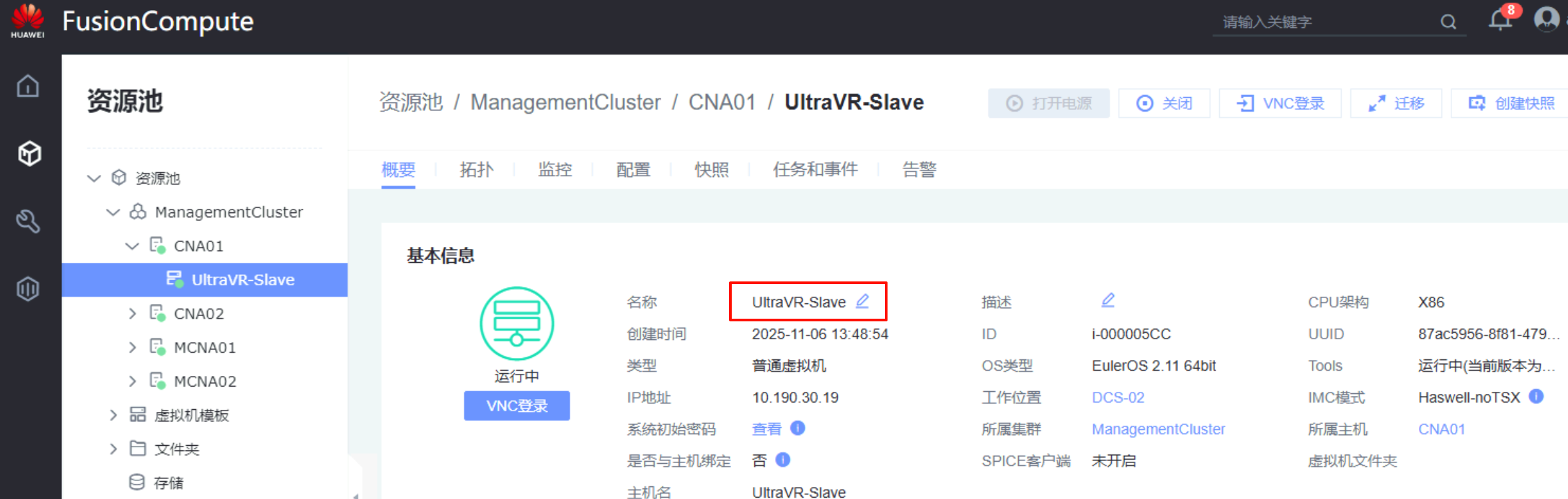
灾备站点:UltraVR-Slave
UltraVR软件配置
生产站点配置
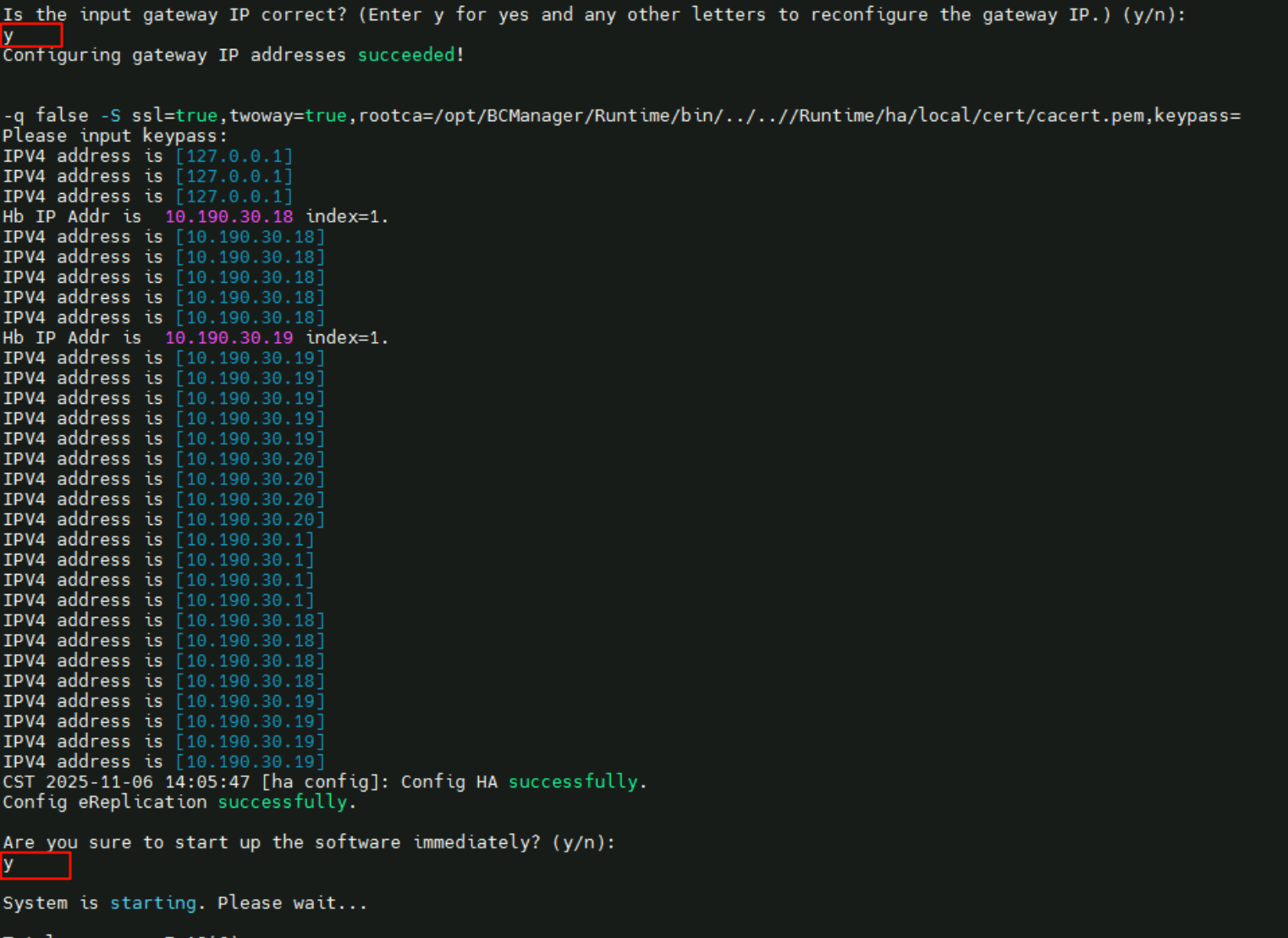
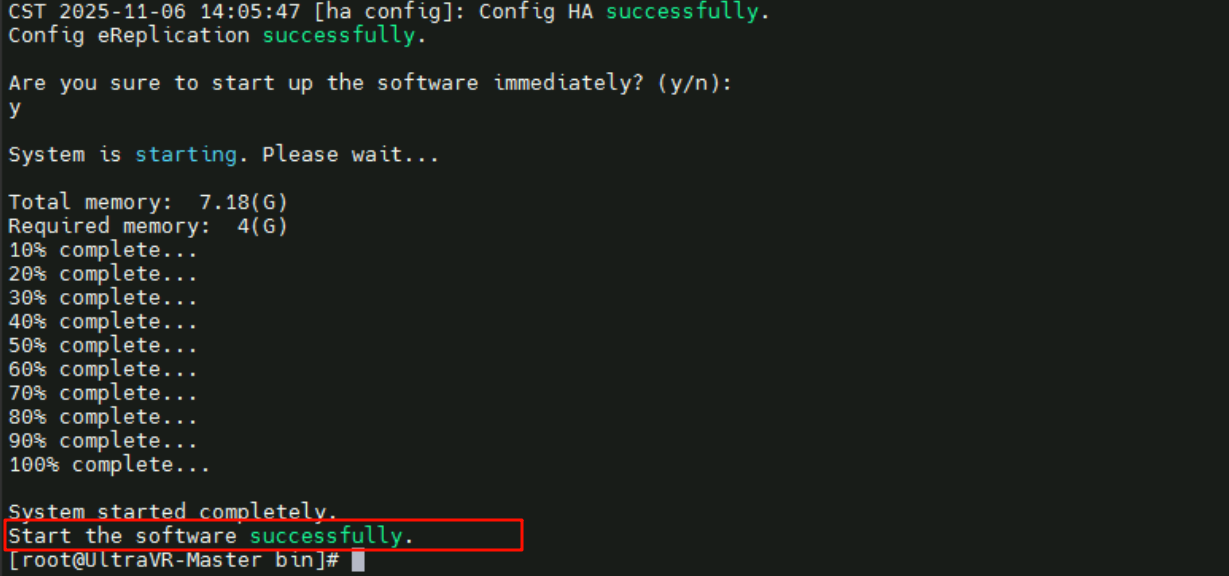
1 | cd /opt/BCManager/Runtime/bin |
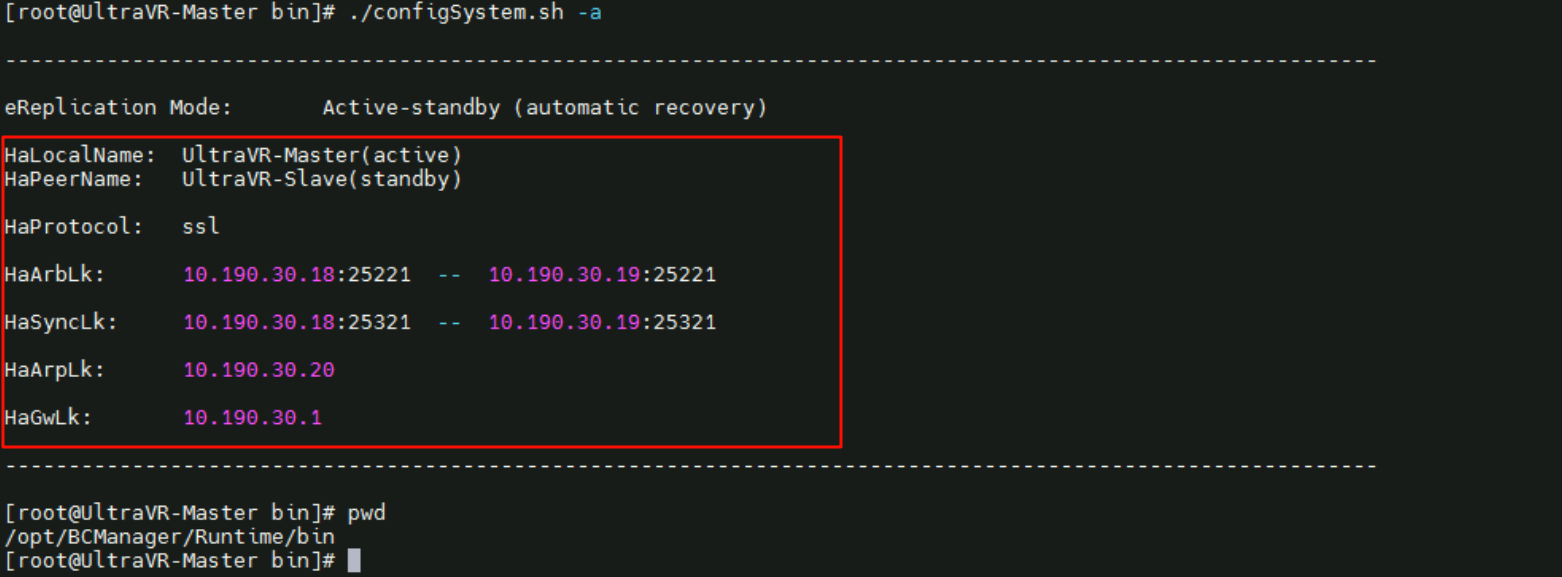
- 配置部署模式为:
Active-standby主备自动模式
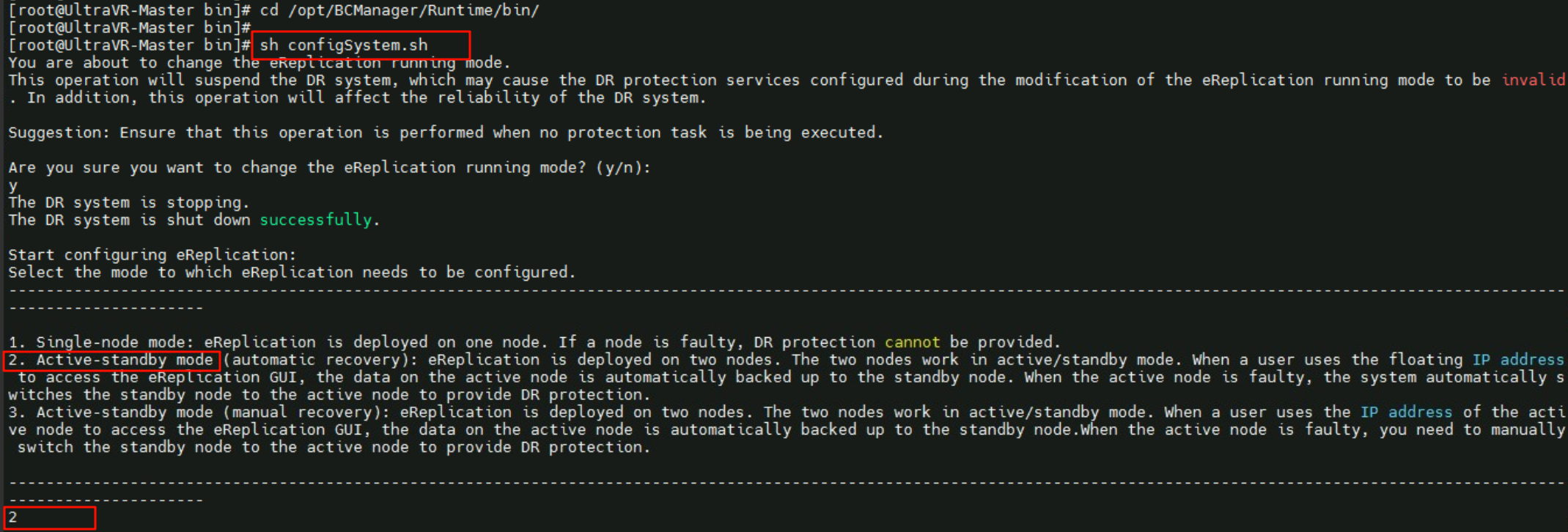
- 生产站点的UltraVR模式为:
active主端 - 本端名称为
UltraVR-Master、远端名称为UltraVR-Slave - 管理IP界面为网卡
enp4s1 192.168.30.18/24、浮动地址为10.190.30.20 - 配置心跳IP数量为
1,本端心跳IP10.190.30.18、远端心跳IP10.190.30.19
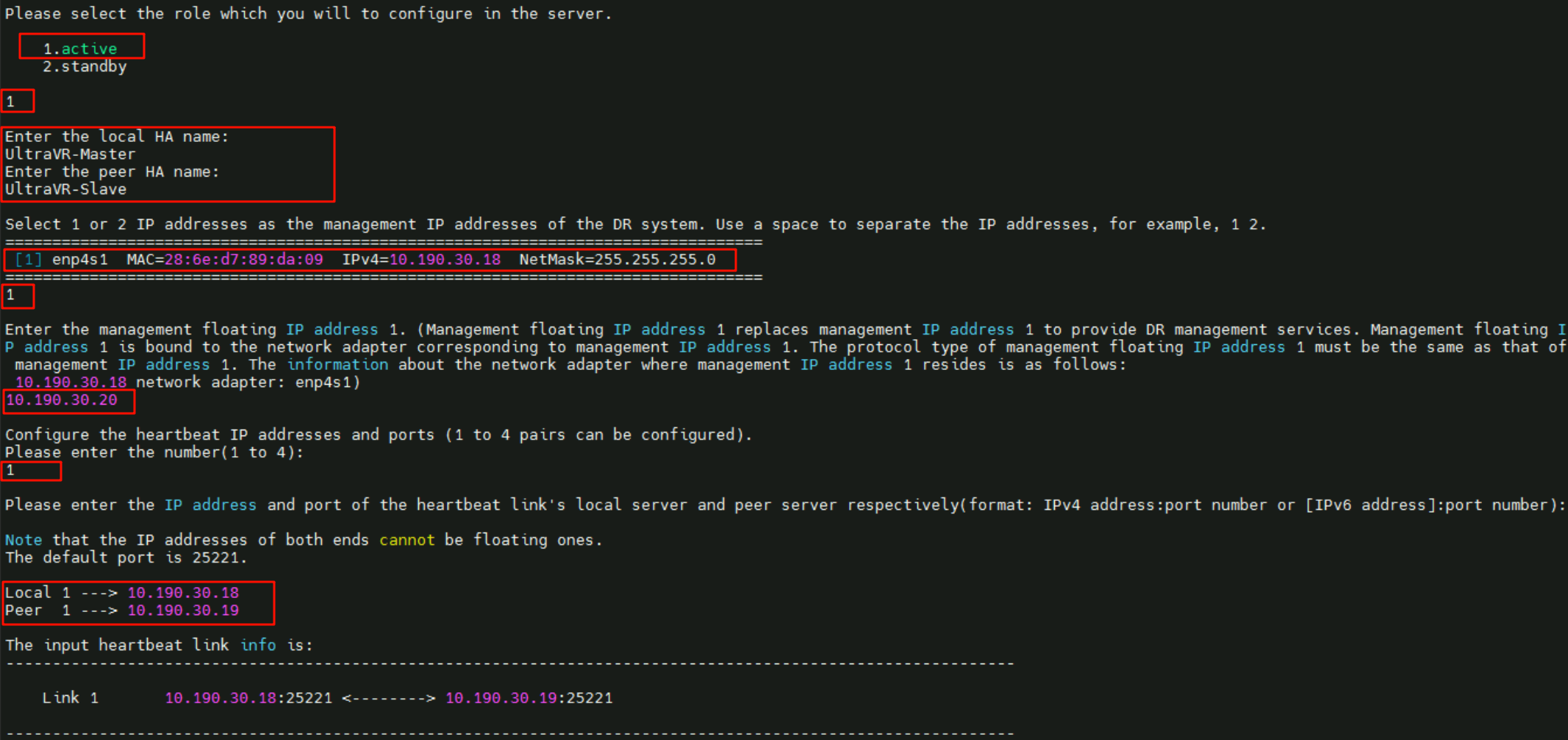
- 配置文件同步IP数量为
1,本端心跳IP10.190.30.18、远端心跳IP10.190.30.19
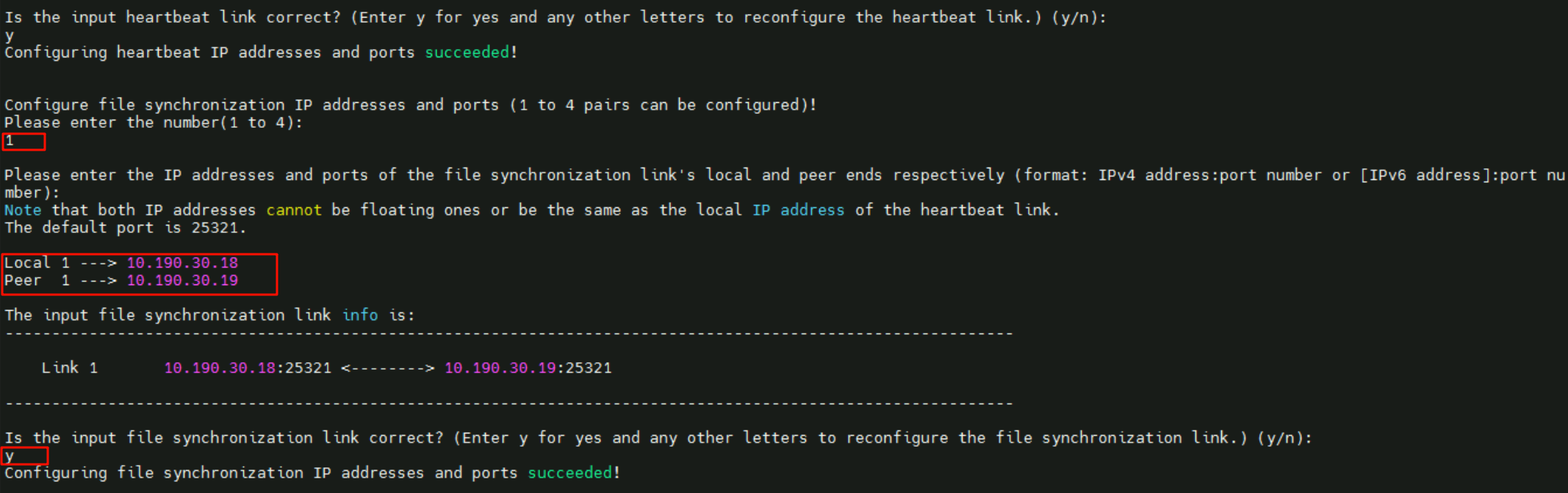
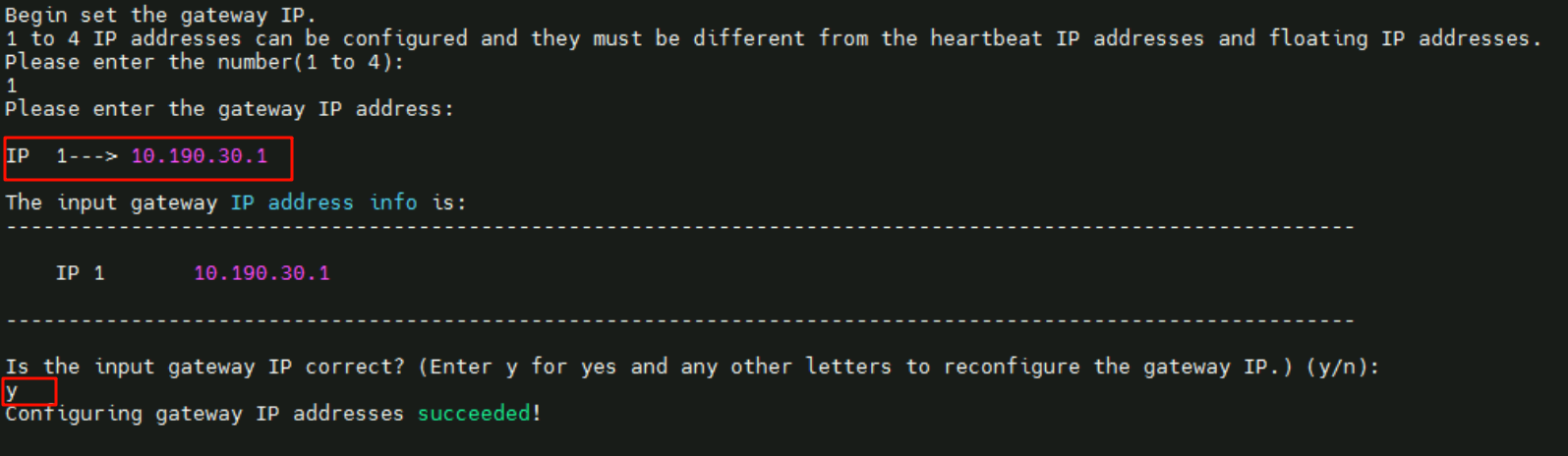
- 配置
1个网关IP,地址为10.190.30.1
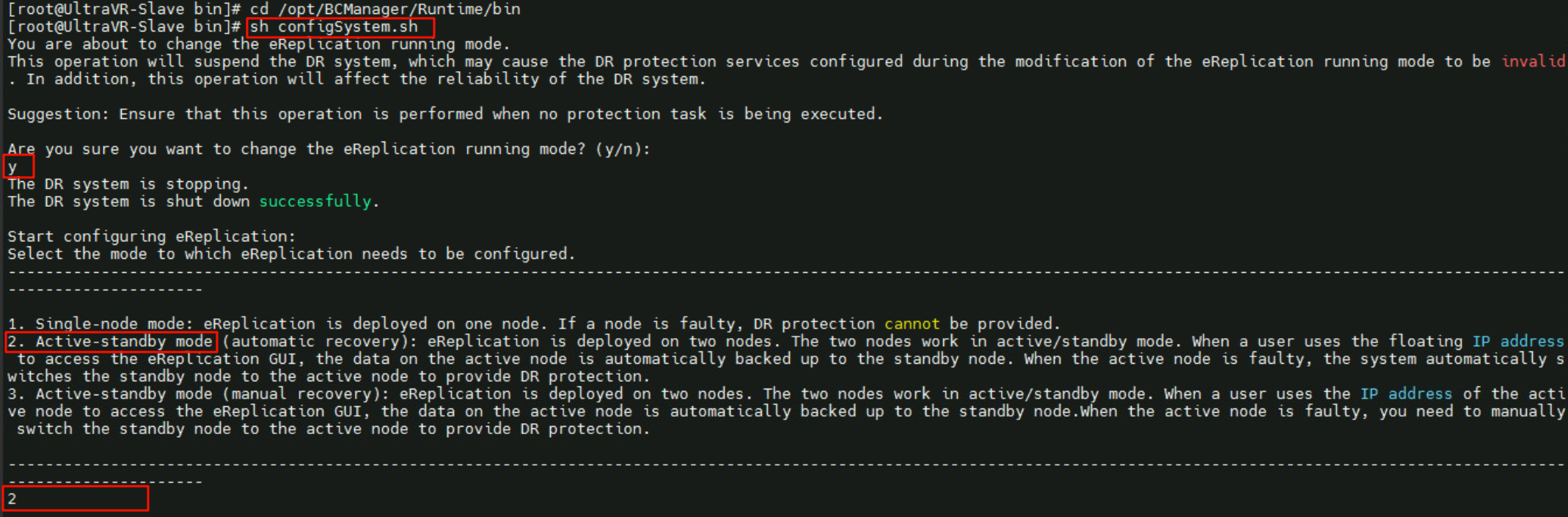
灾备站点配置
配置与生产站点反着来,流程都是一样的
- 配置部署模式为:
Active-standby主备自动模式
- 生产站点的UltraVR模式为:
standby备端 - 本端名称为
UltraVR-Slave、远端名称为UltraVR-Master - 管理IP界面为网卡
enp4s1 192.168.30.19/24、浮动地址为10.190.30.20
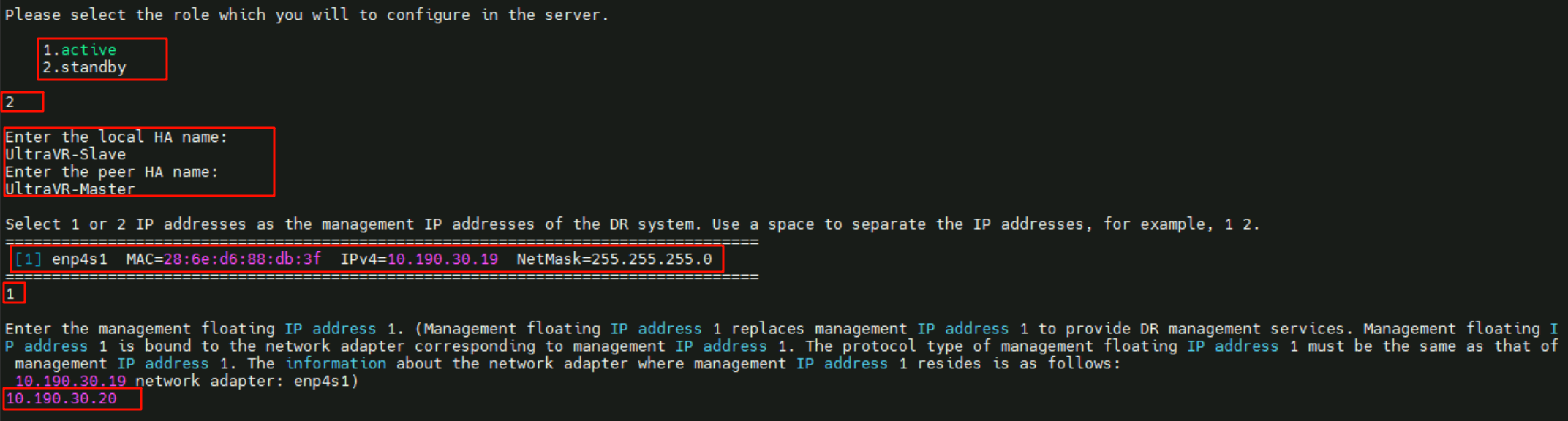
- 配置心跳IP数量为
1,本端心跳IP10.190.30.19、远端心跳IP10.190.30.18
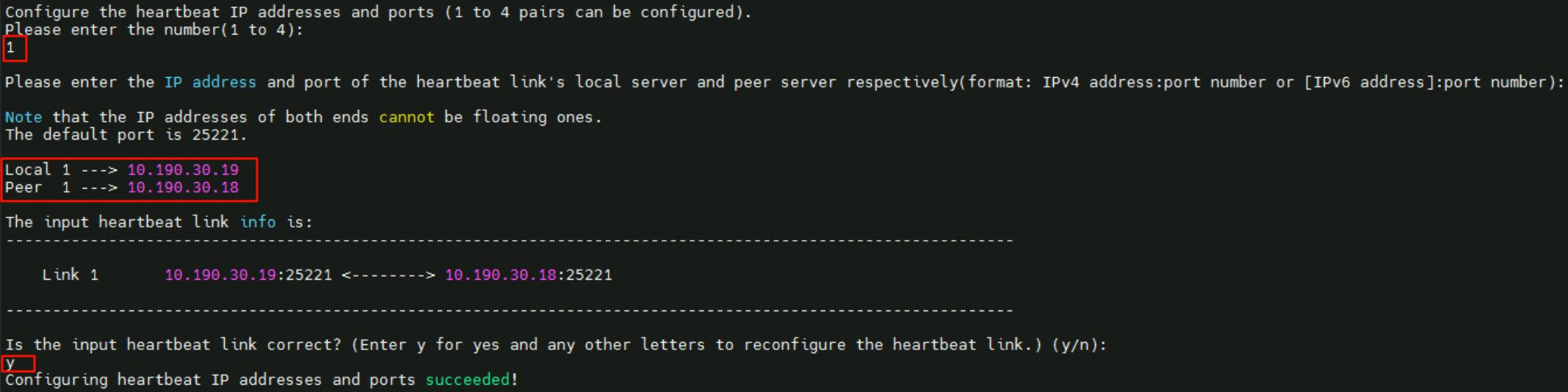
- 配置文件同步IP数量为
1,本端心跳IP10.190.30.19、远端心跳IP10.190.30.18
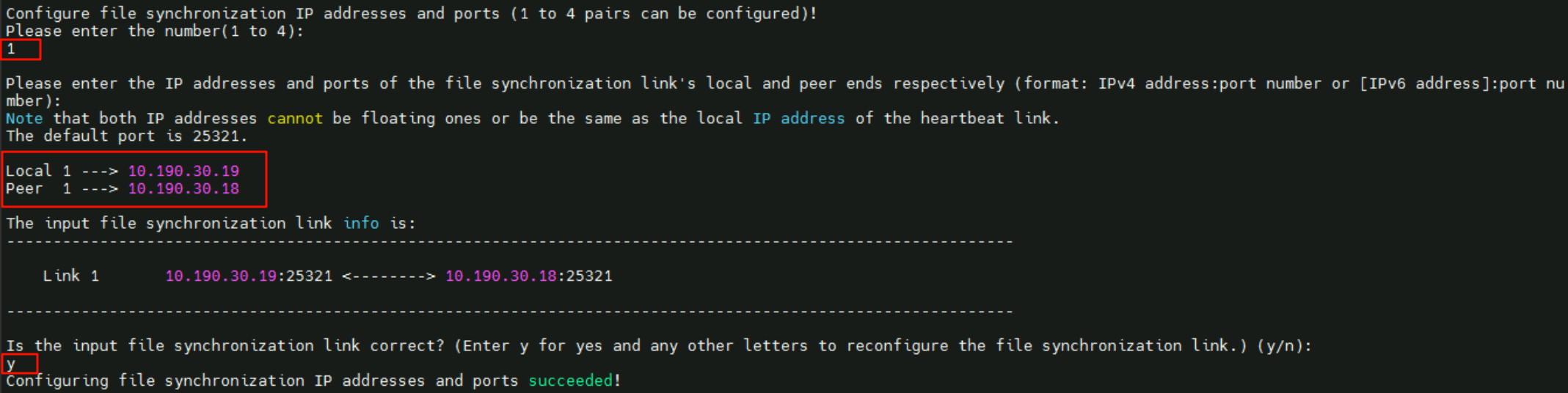
- 配置
1个网关IP,地址为10.190.30.1
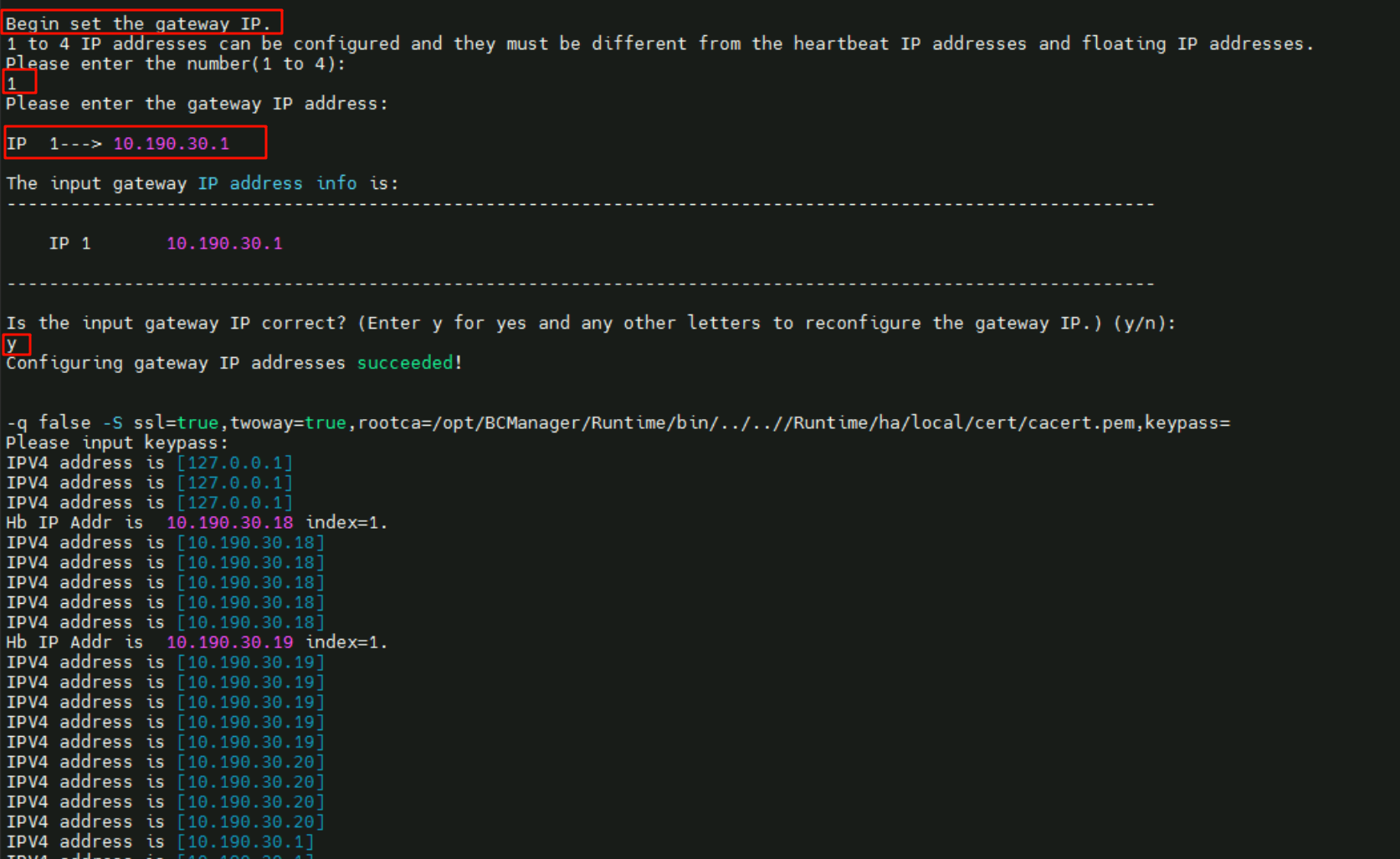
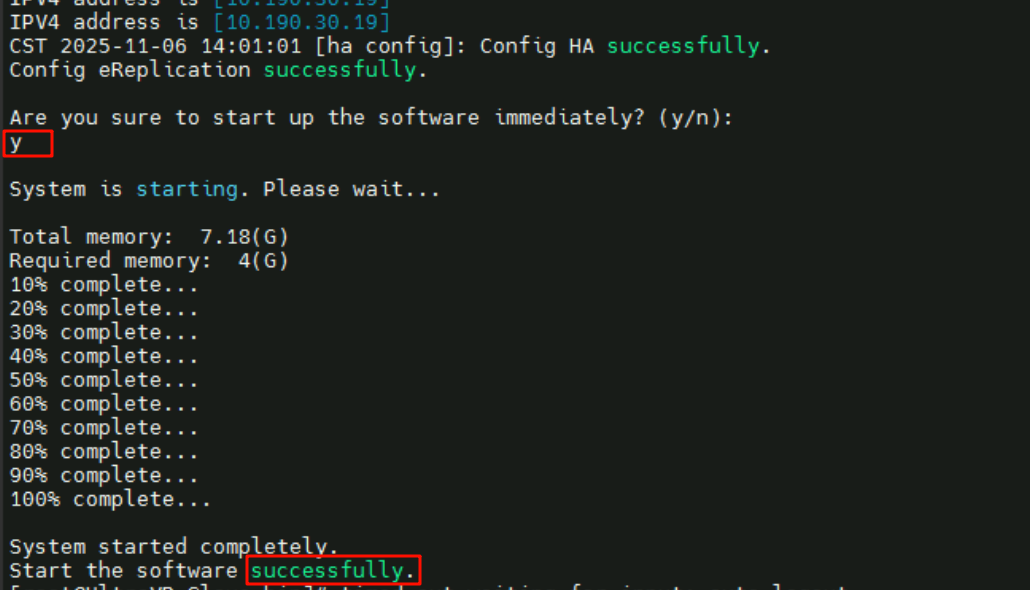
状态验证
UltraVR-Master状态为active,UltraVR-Slave状态为standby
1 | cd /opt/BCManager/Runtime/bin |
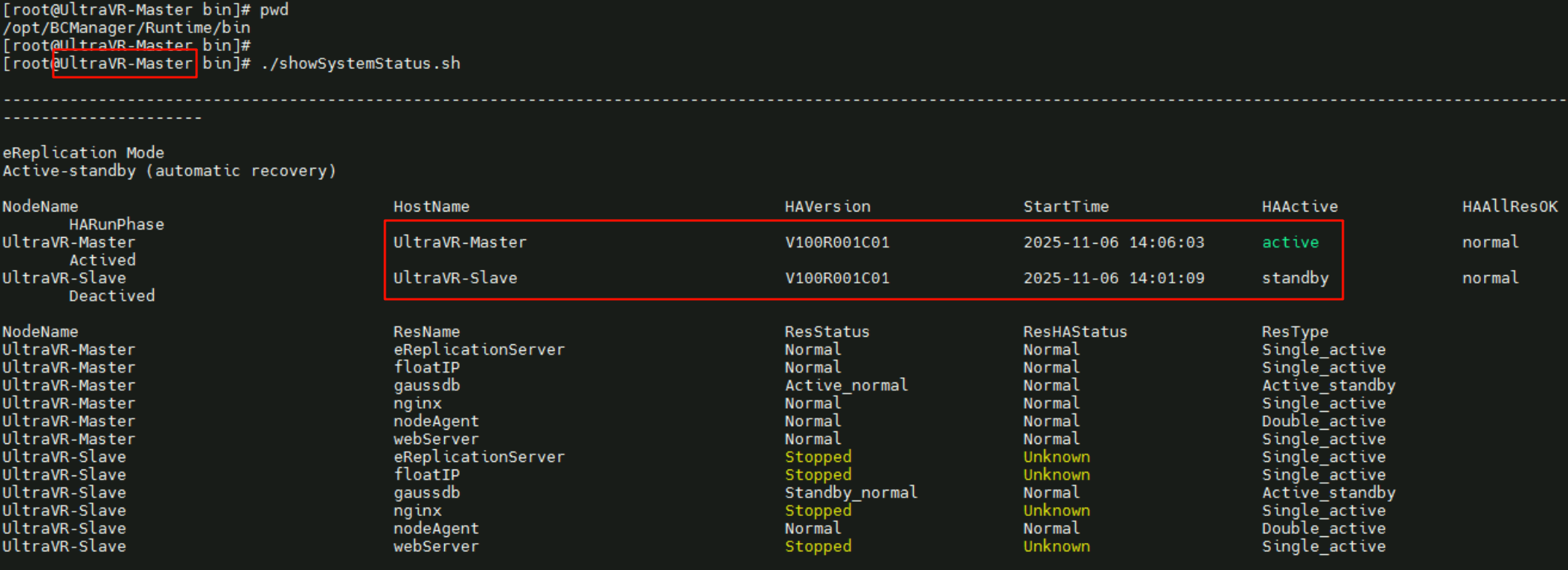
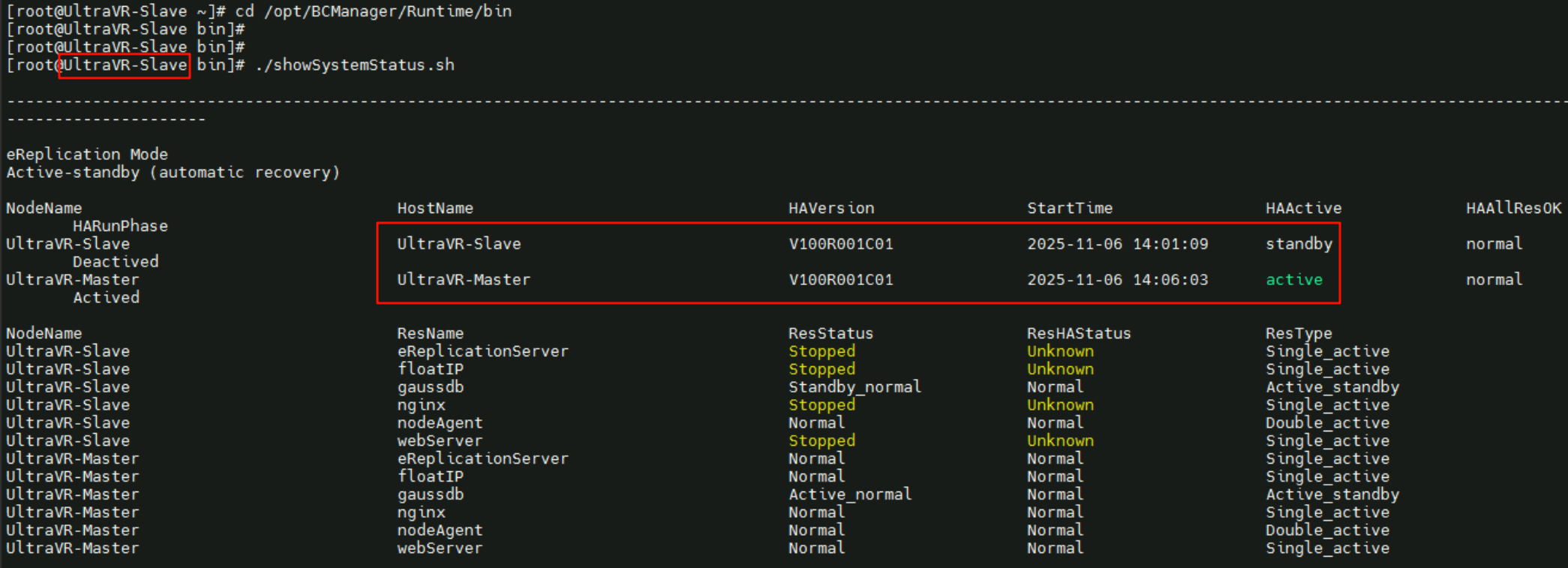
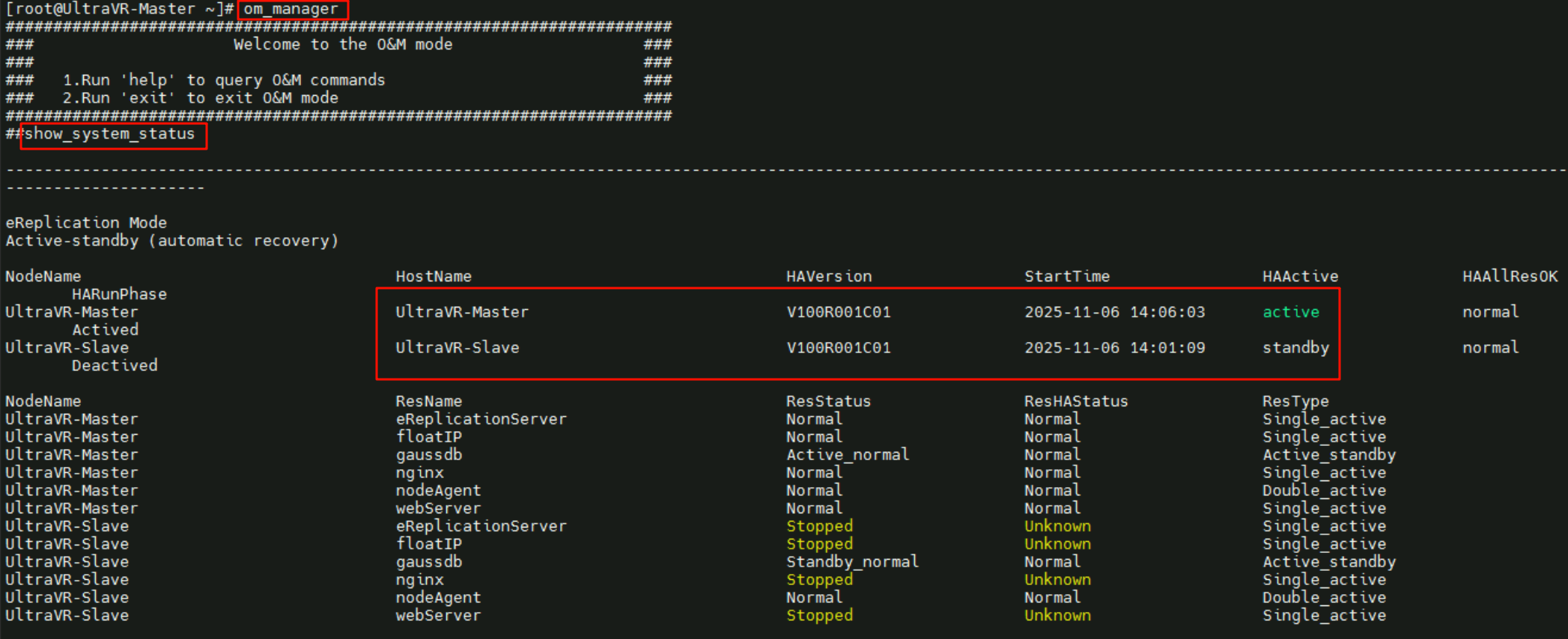
或者使用om_manager命令,通过show_system_status查看主备状态
存储LUN映射和远程复制
存储规划
生产站点存储配置
本实验环境使用租户登录,在真实的环境中只要能创建LUN、创建主机、映射即可,不用管这么多
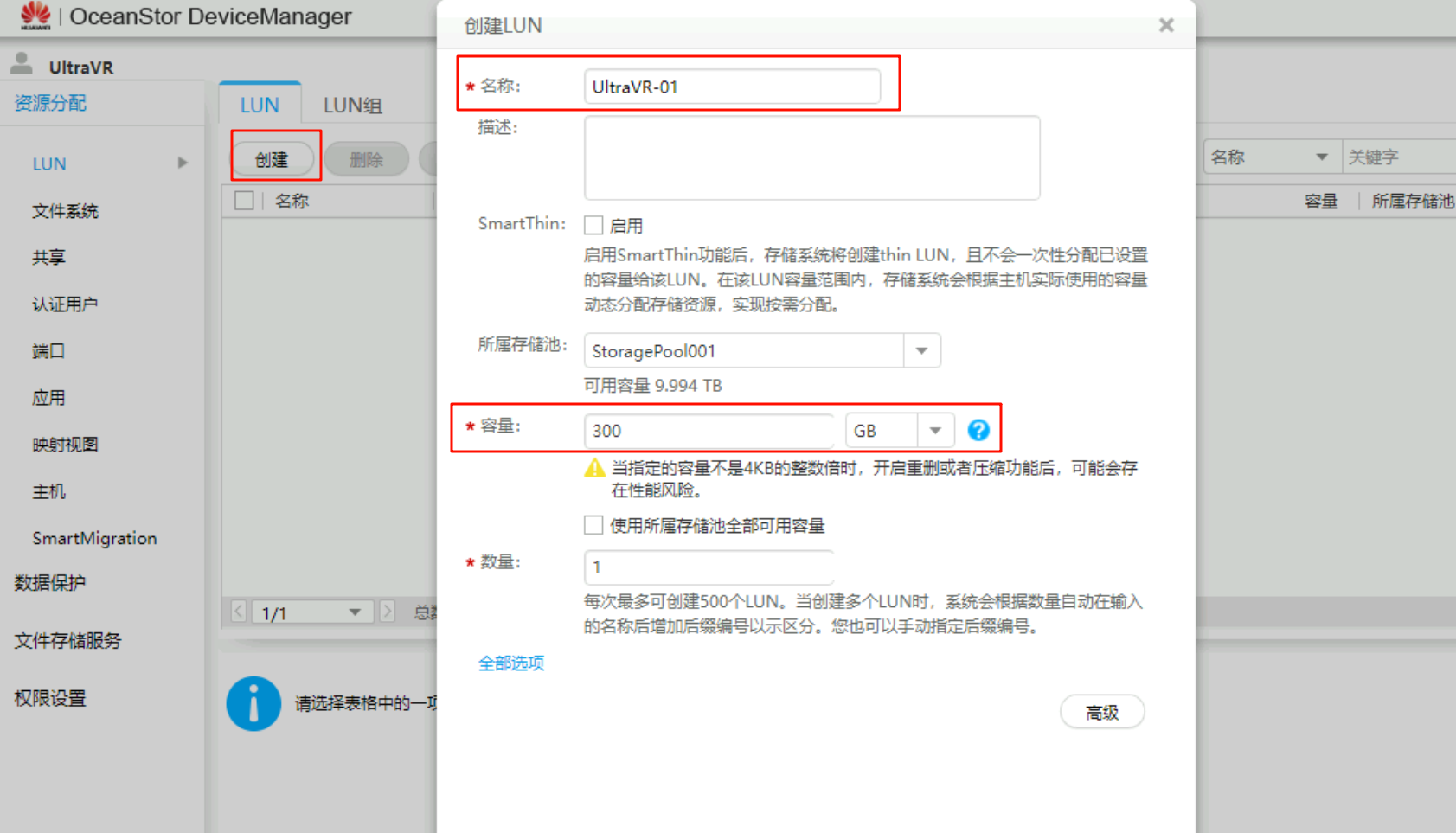
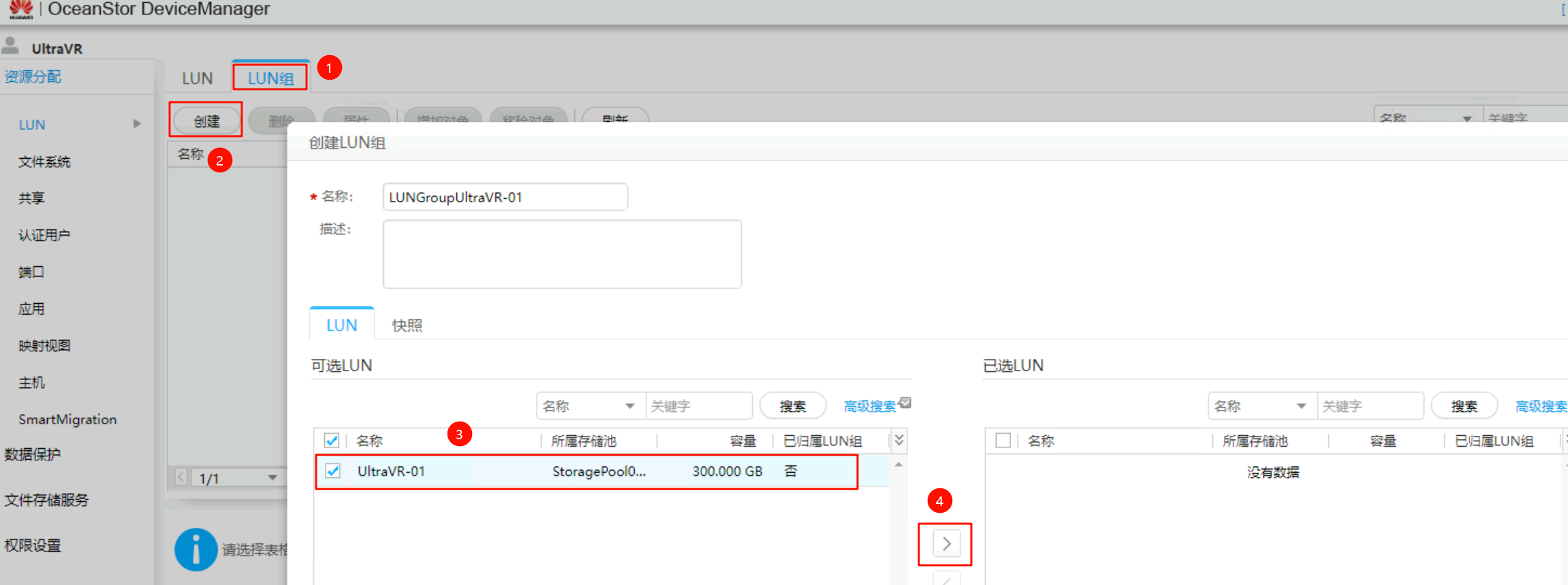
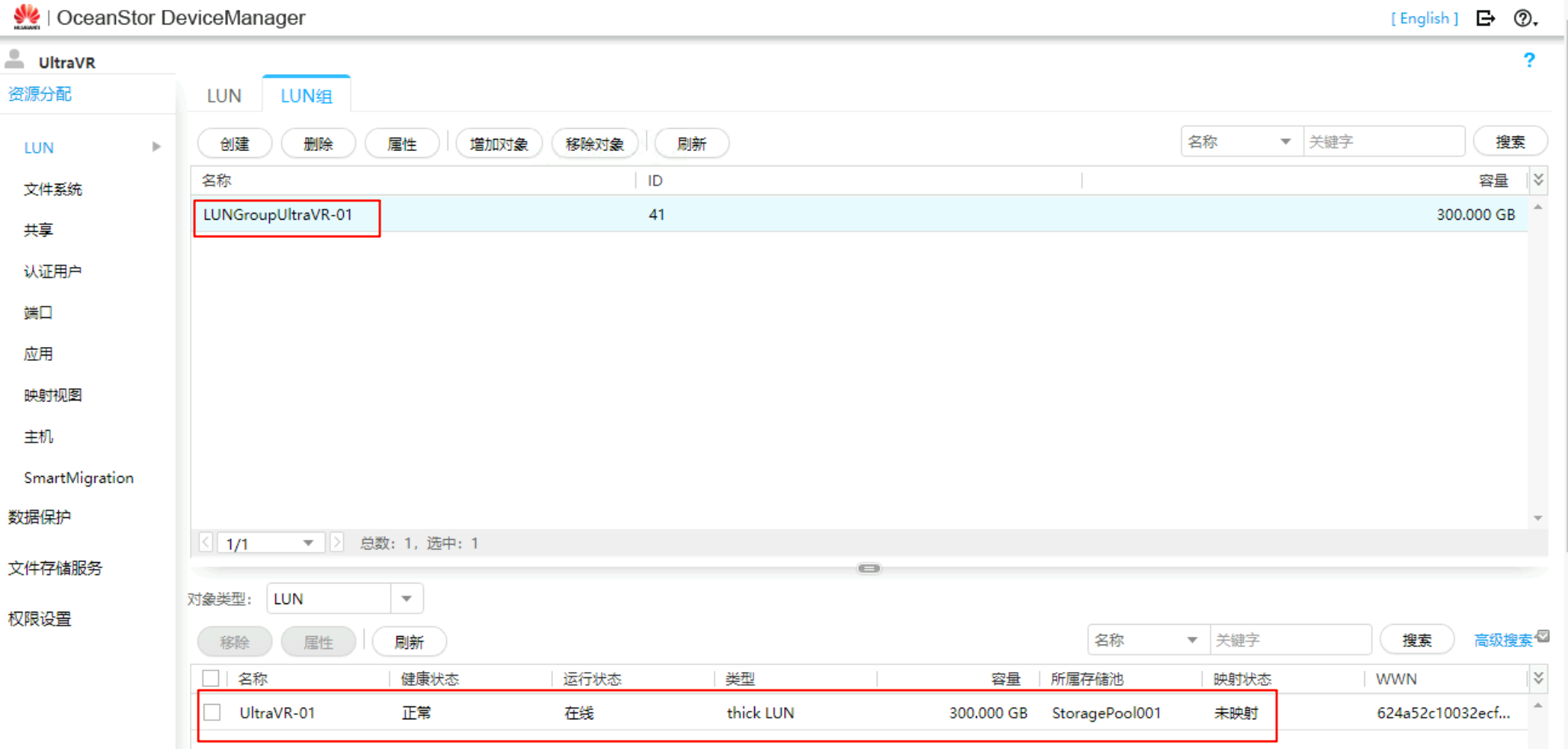
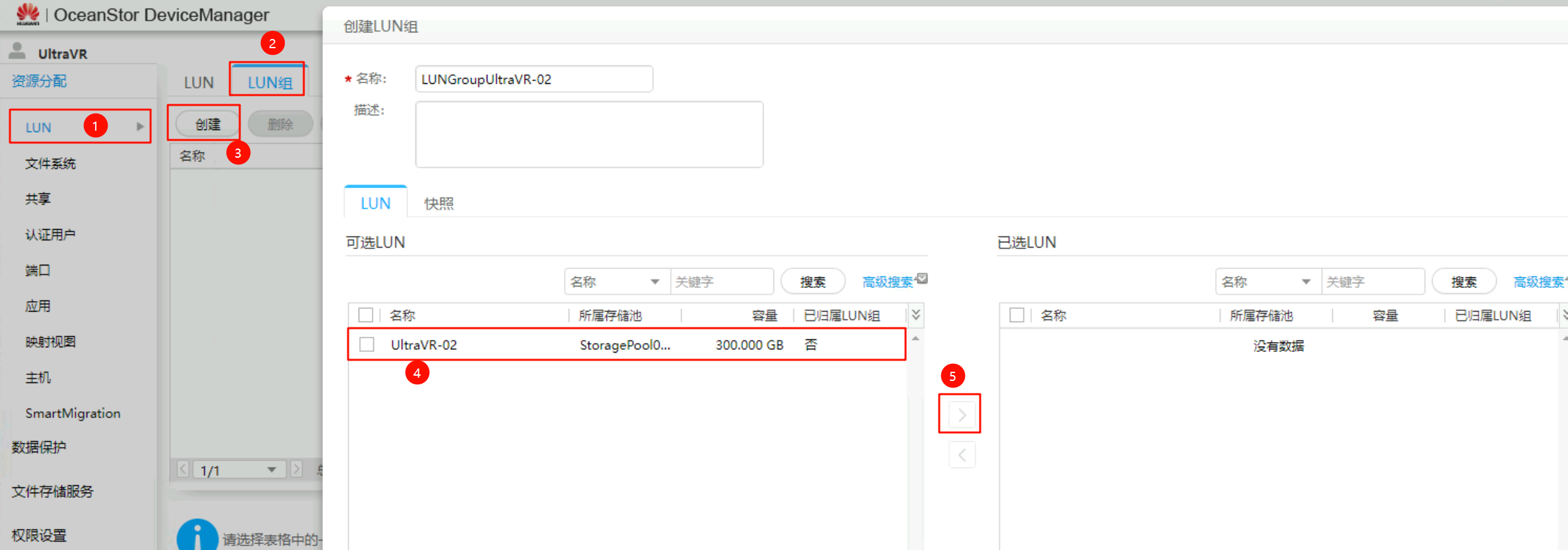
创建LUN与LUN组
创建一个300GB的LUNUltraVR-01并加入到LUN组LUNGroupUltraVR-01中(后续会在该LUN上创建虚拟机,做主备容灾测试实验)
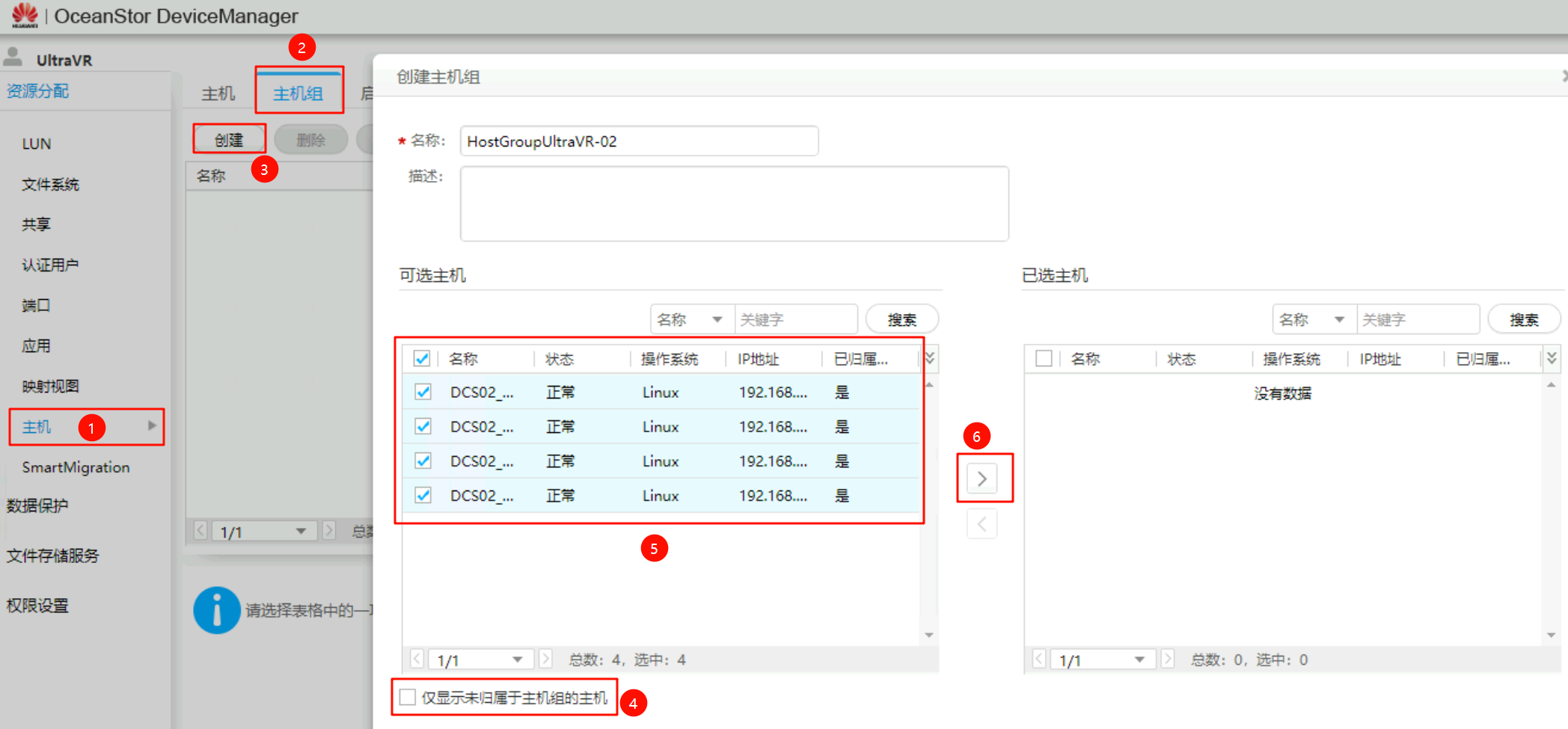
创建主机组
以下的四台主机为FusionCompute上的四个CNA节点,已经提前添加到生产站点的存储设备上,只需要将其加入到对应的主机组即可
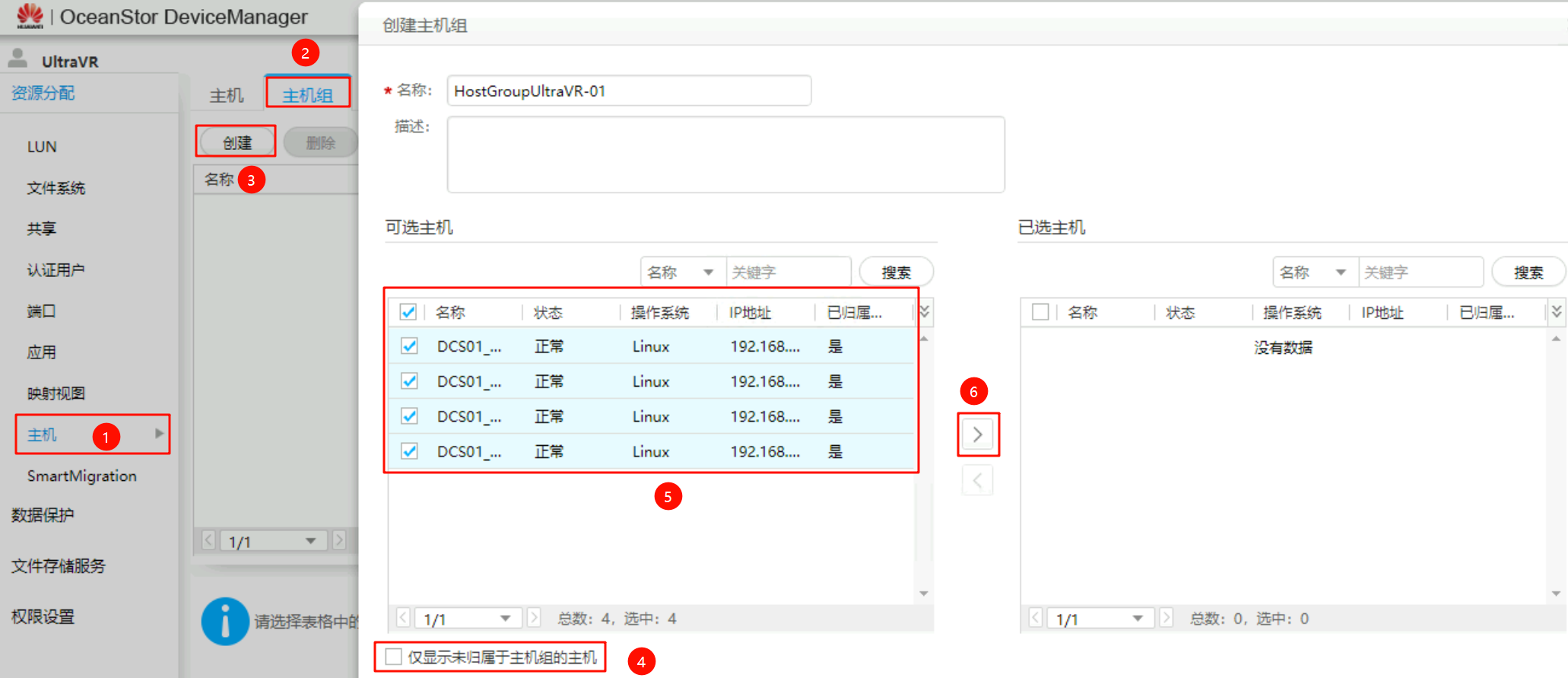
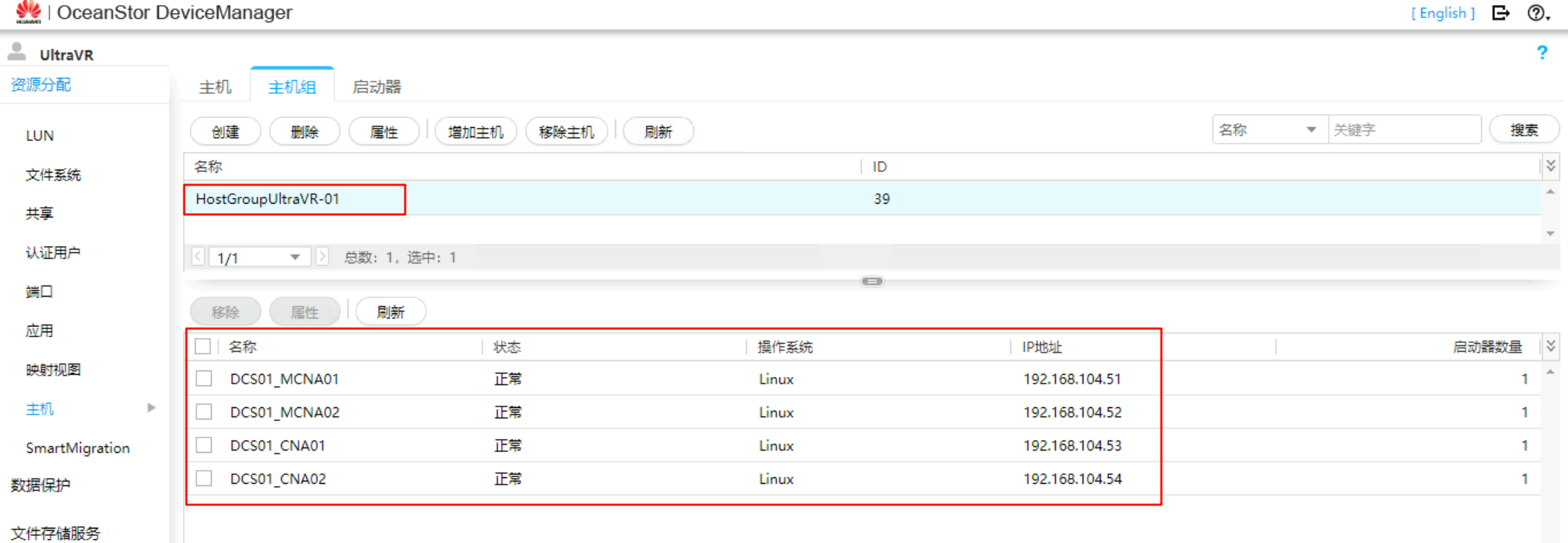
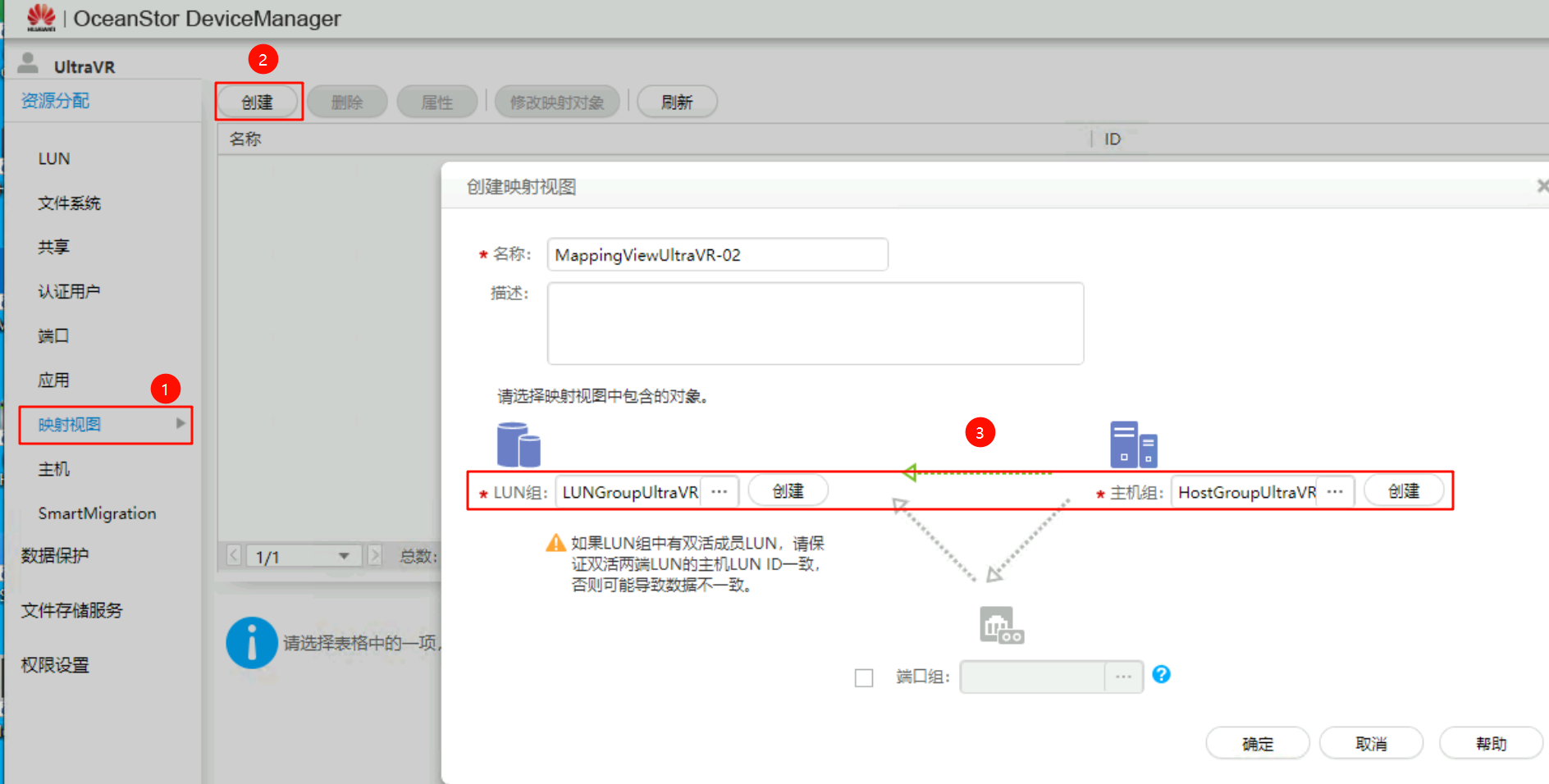
创建映射视图:将上述创建的主机组与LUN组做映射
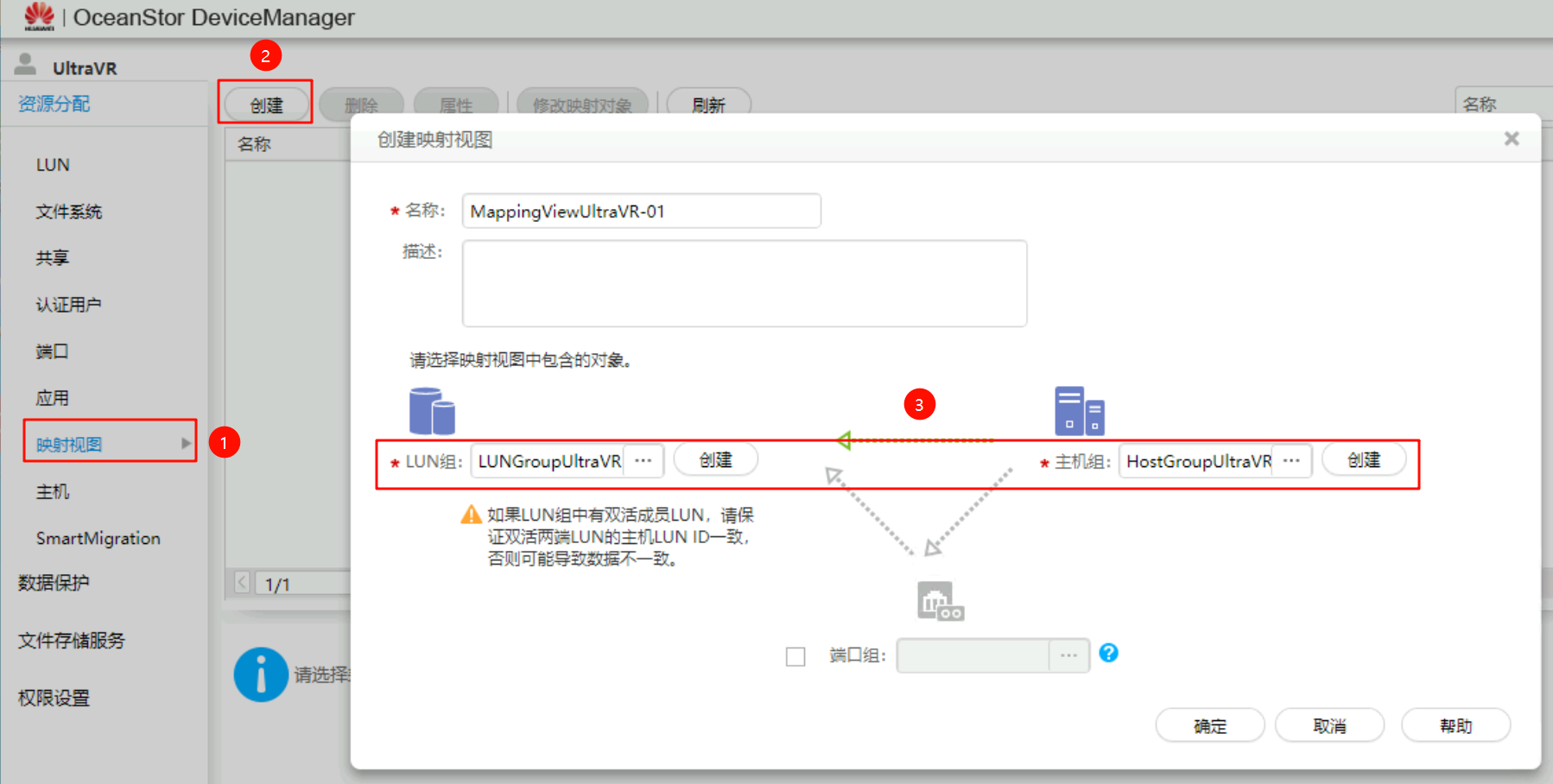
灾备站点存储配置
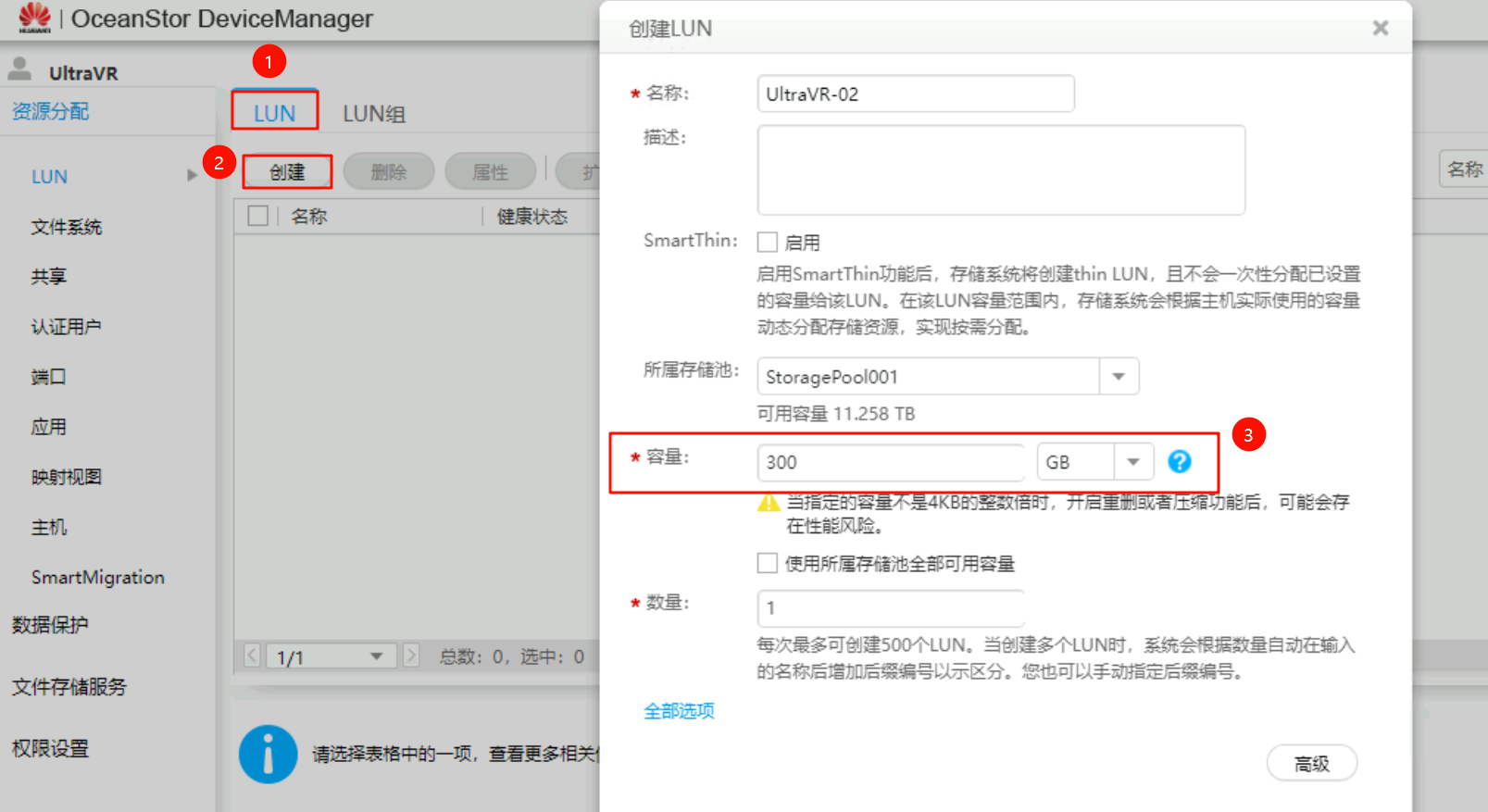
创建LUN与LUN组
创建与生产站点相同容量的LUN,并将其加入到LUN组中
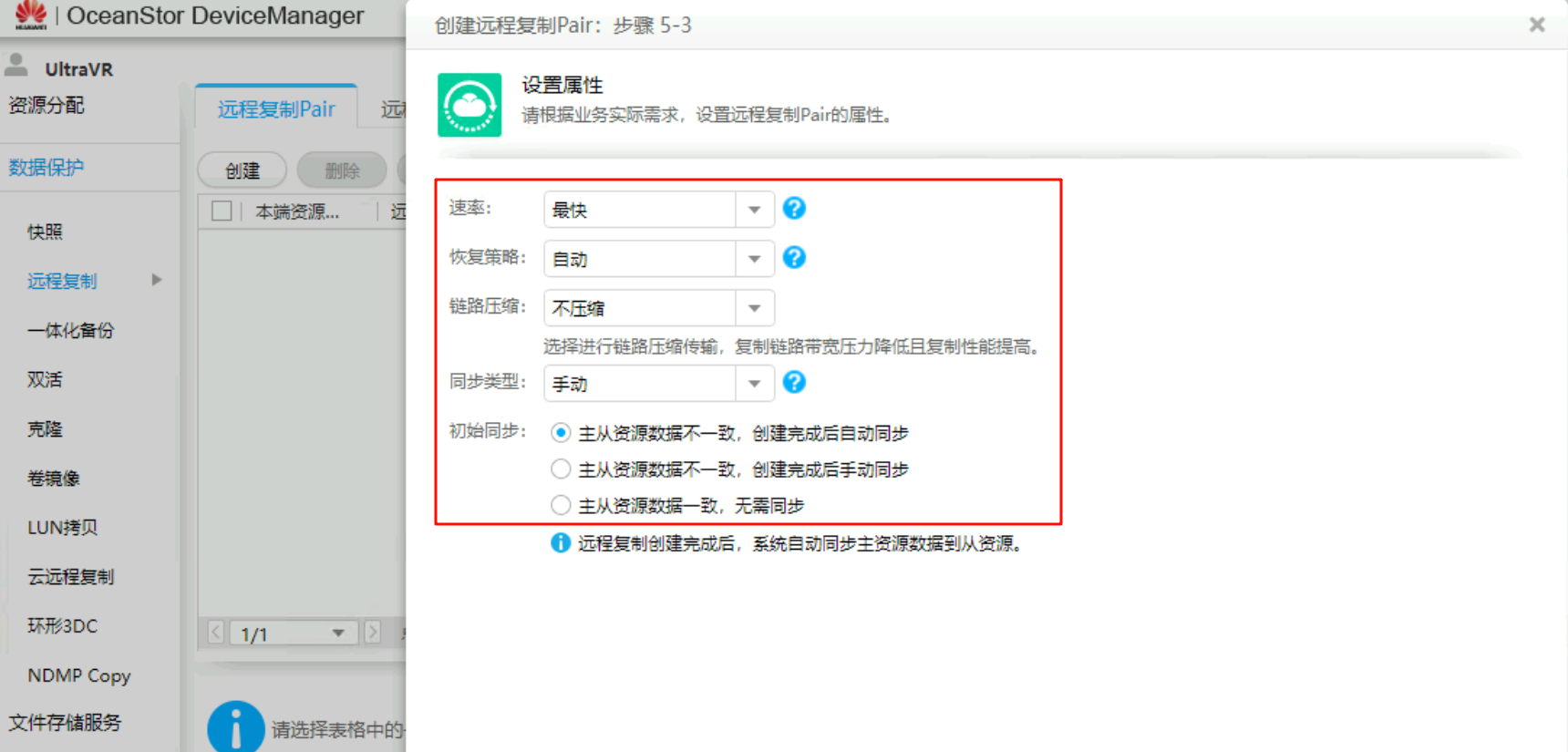
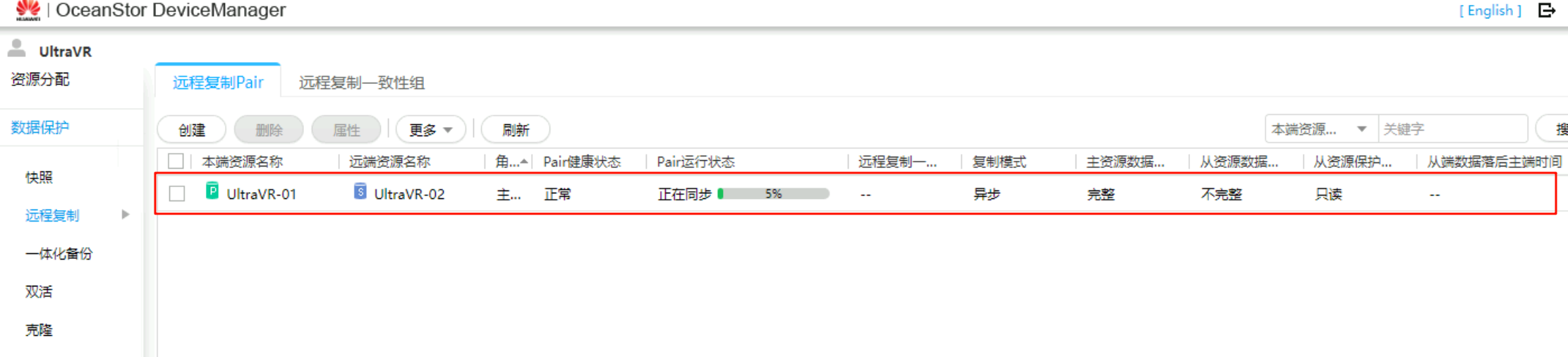
创建远程复制Pair
生产站点
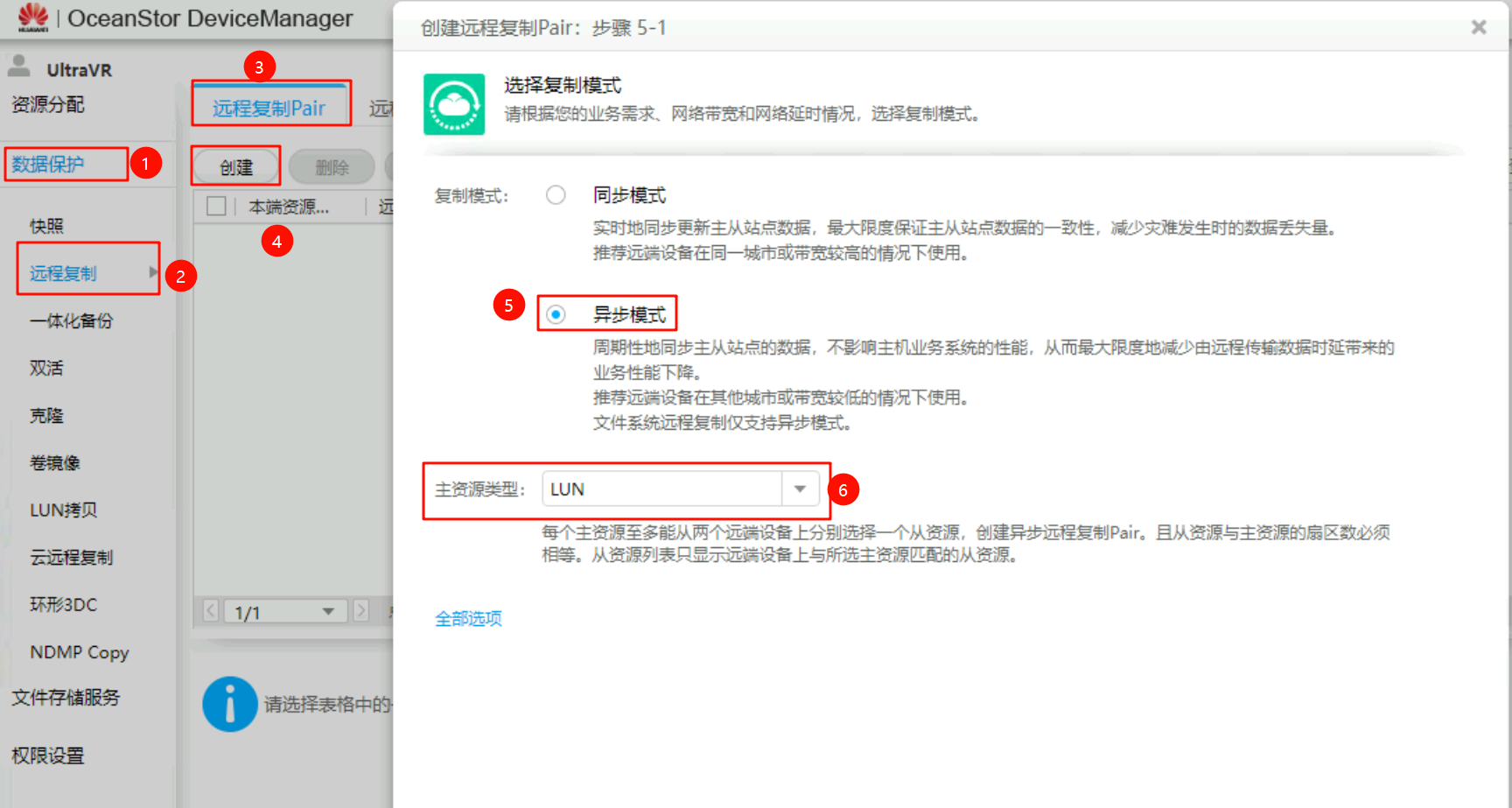
- 在生产站点的存储上创建
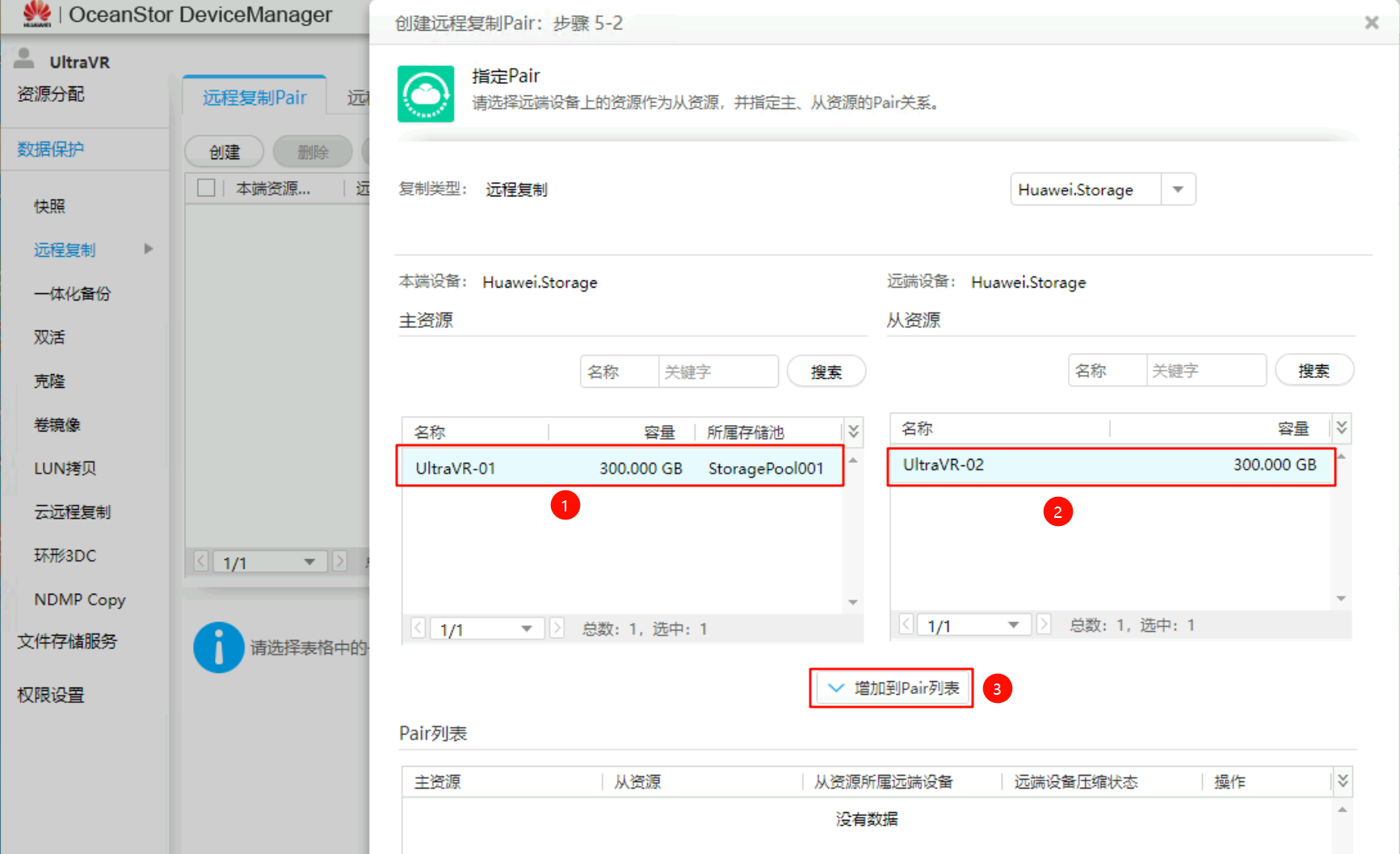
远程复制Pair,复制模式为异步模式、主资源类型为LUN - 选择需要创建远程复制Pair的LUN(生产端和灾备端),并
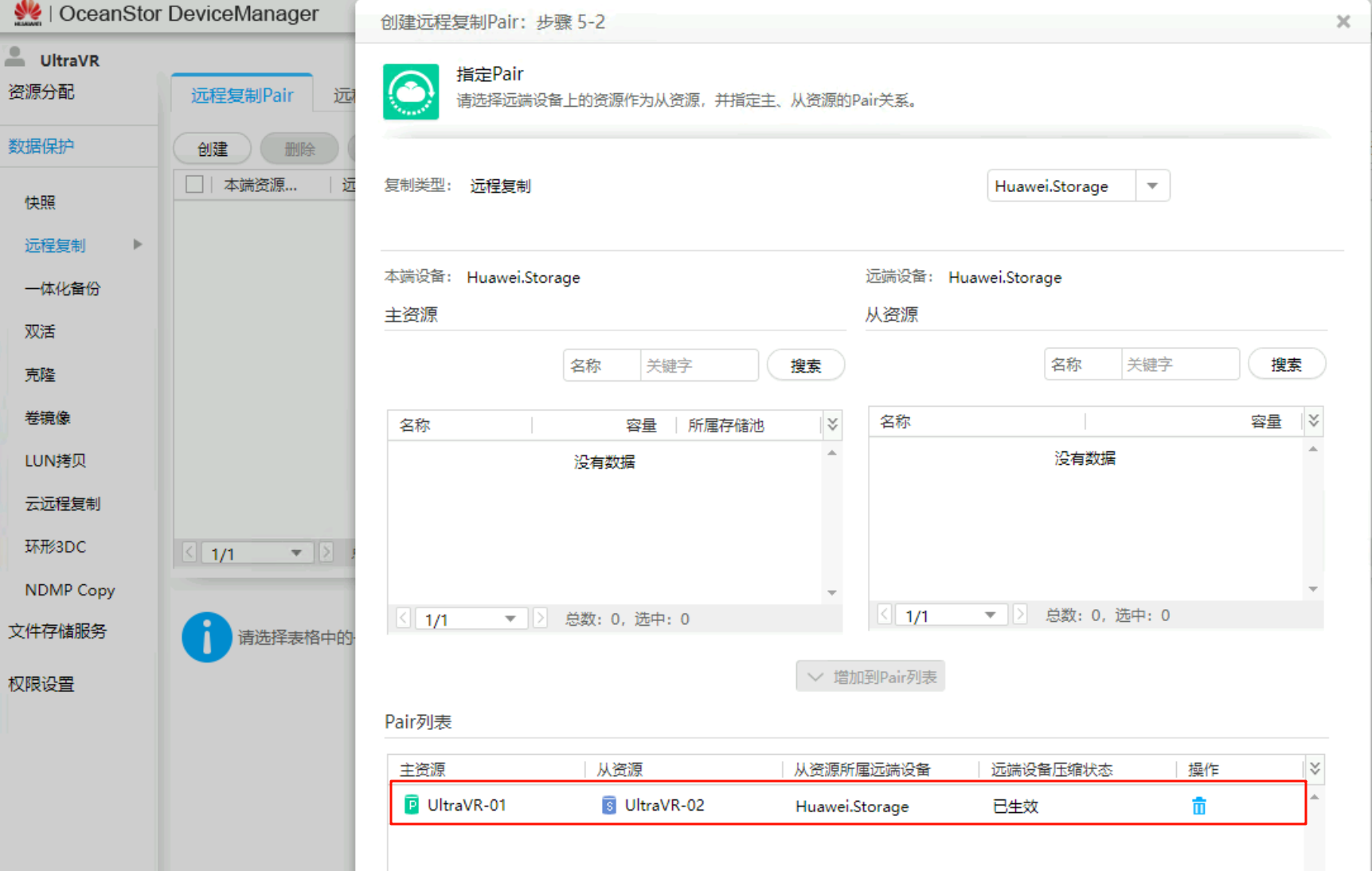
增加到Pair列表
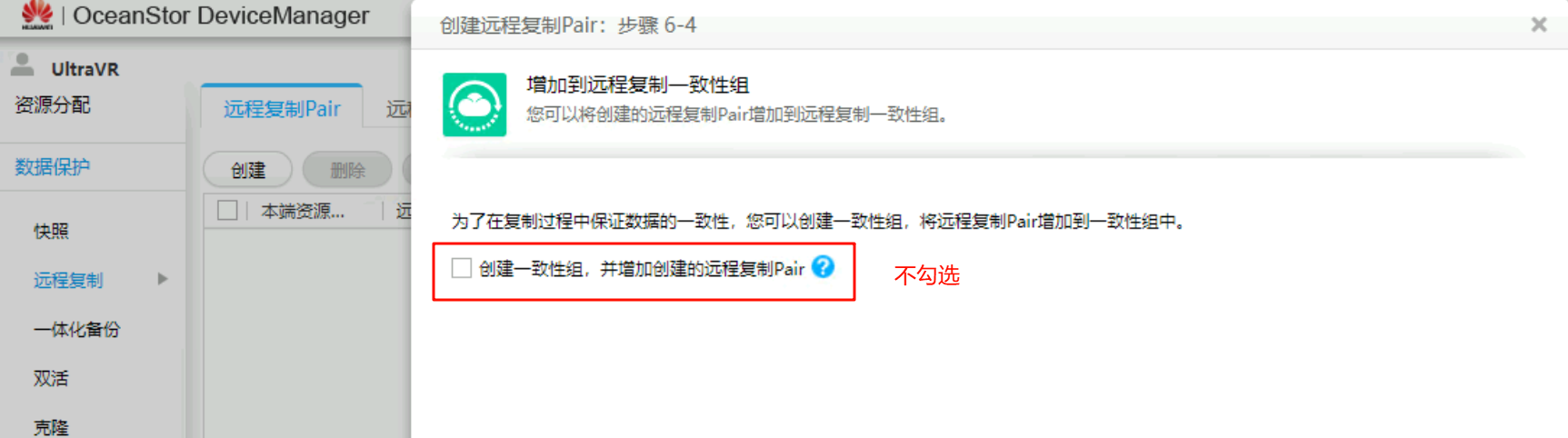
灾备站点
- 在灾备站点同样将LUN加入到LUN组中、将主机加入到主机组中(该主机为灾备端FusionCompute上的CNA节点)、并创建映射视图
创建虚拟机
FC关联存储
生产站点配置
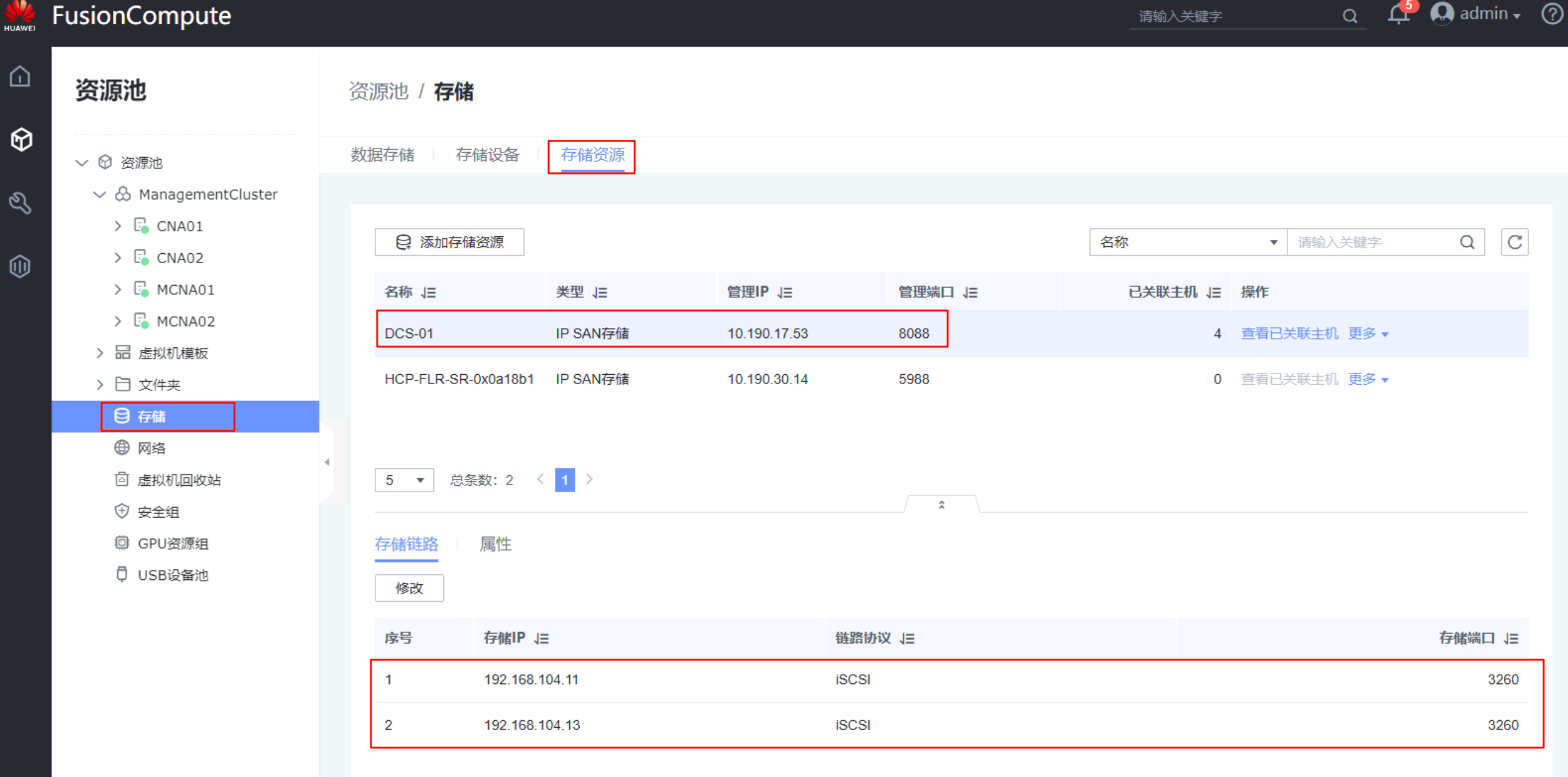
- 在生产站点的FusionCompute上添加存储资源:添加本端的OceanStor(本实验已经提前添加)
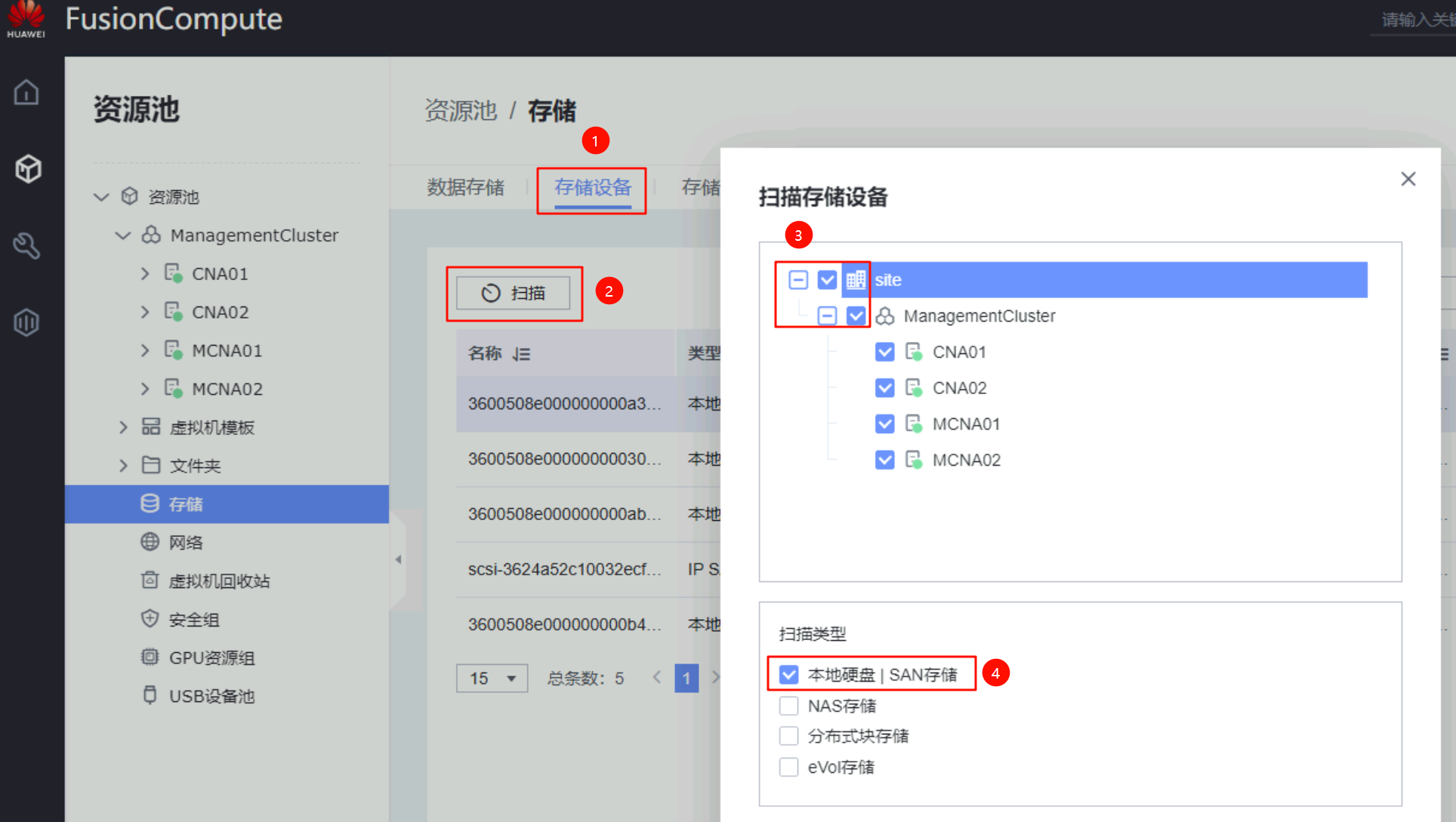
- 在生产站点的FusionCompute上扫描存储设备:勾选本集群所有CNA、扫描SAN存储
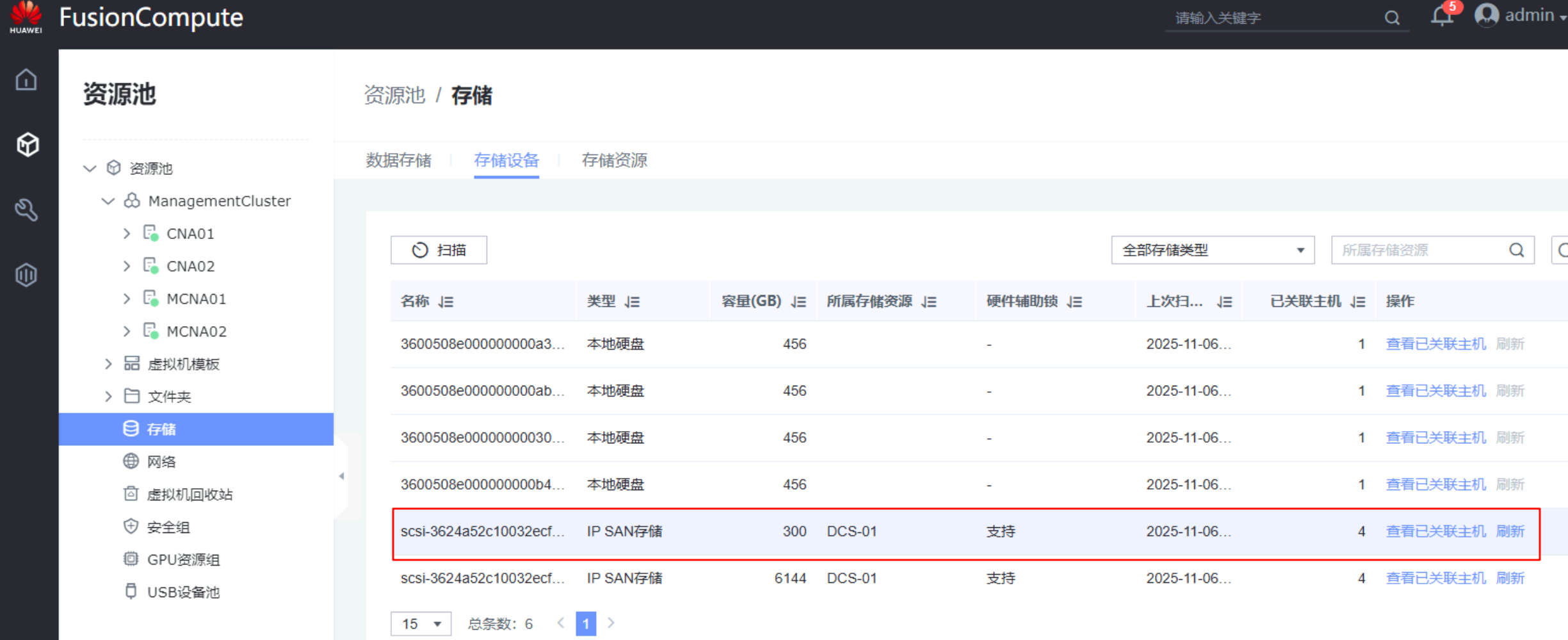
- 在生产站点的FusionCompute上添加数据存储:存储设备为刚才扫描到的、格式化该存储设备、并关联本站点
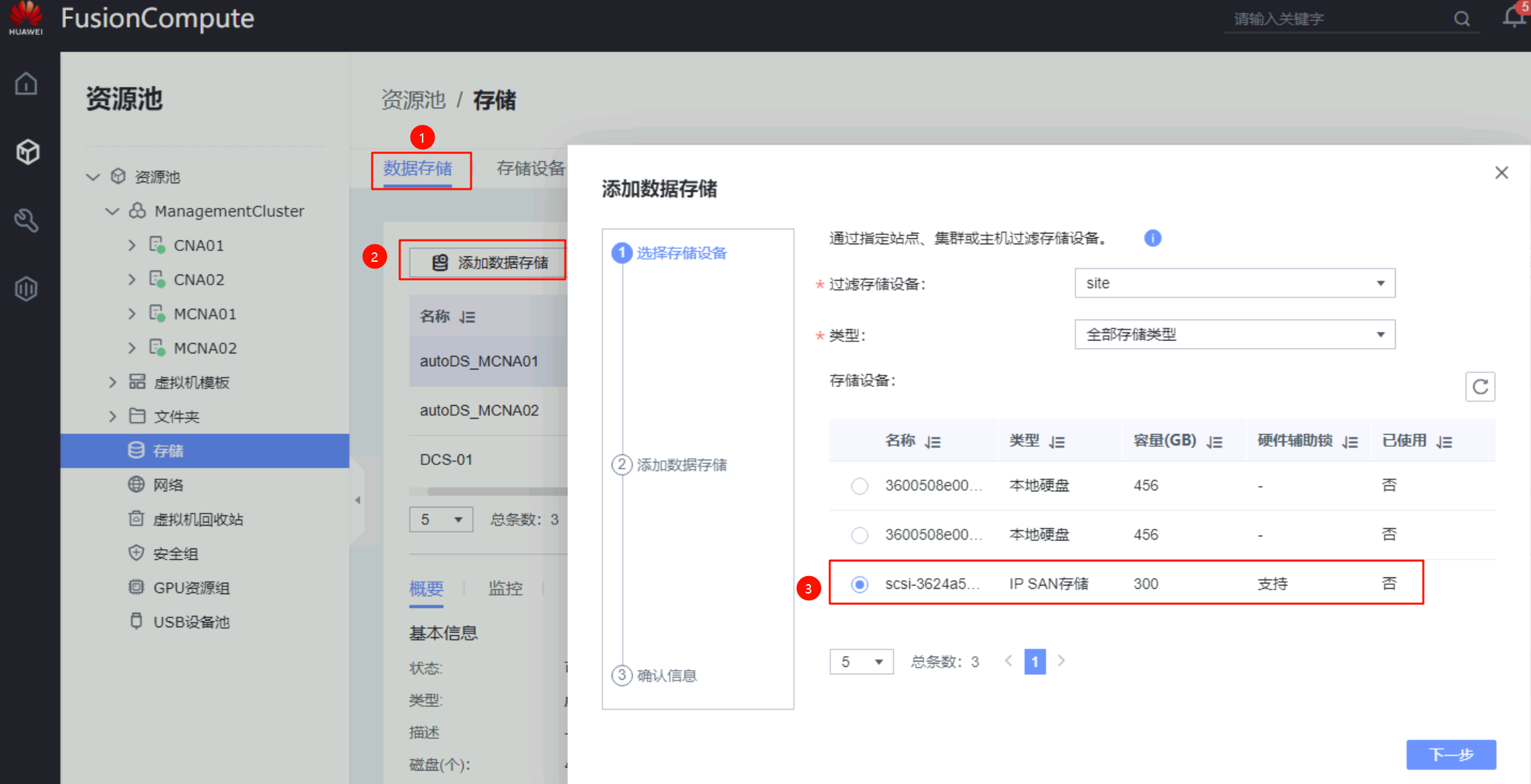
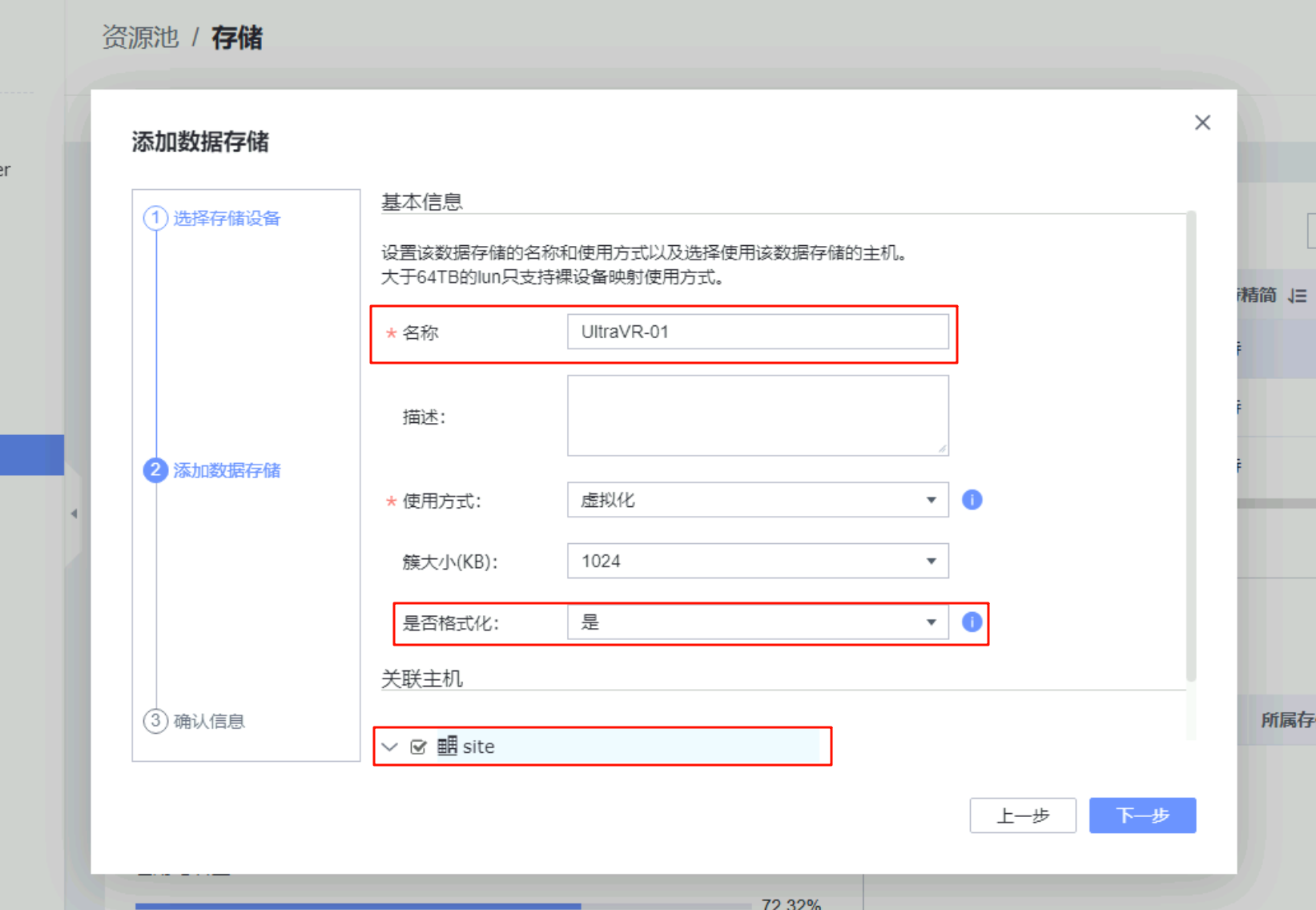
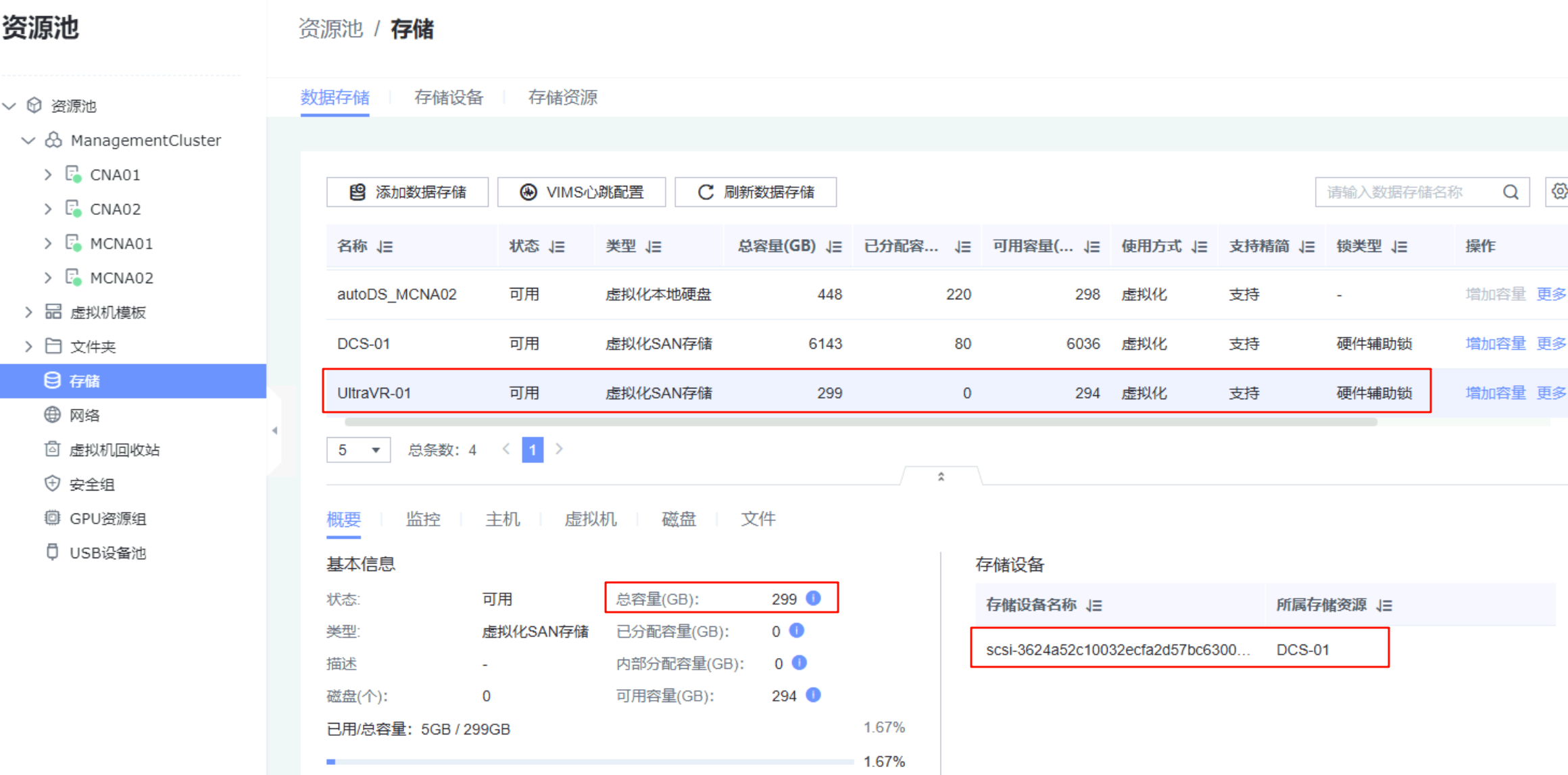
灾备站点配置
灾备站点的FusionCompute只需要将灾备站点的OceanStor添加到存储资源即可,不需要创建存储设备等操作
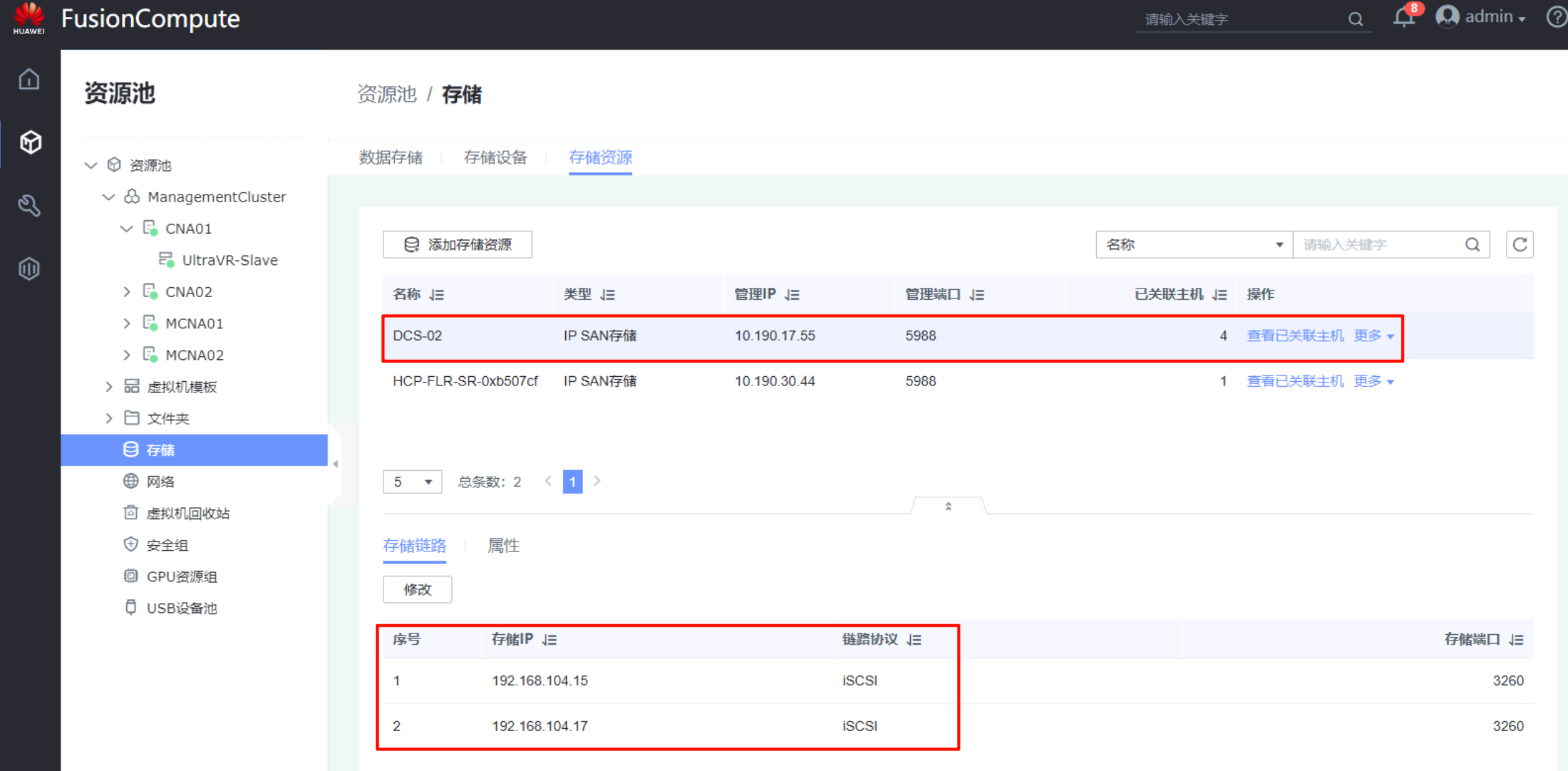
创建测试虚拟机
在生产站点上创建一台虚拟机,虚拟机的磁盘必须选择刚才创建的数据存储上,其他在测试上无所谓怎么配置
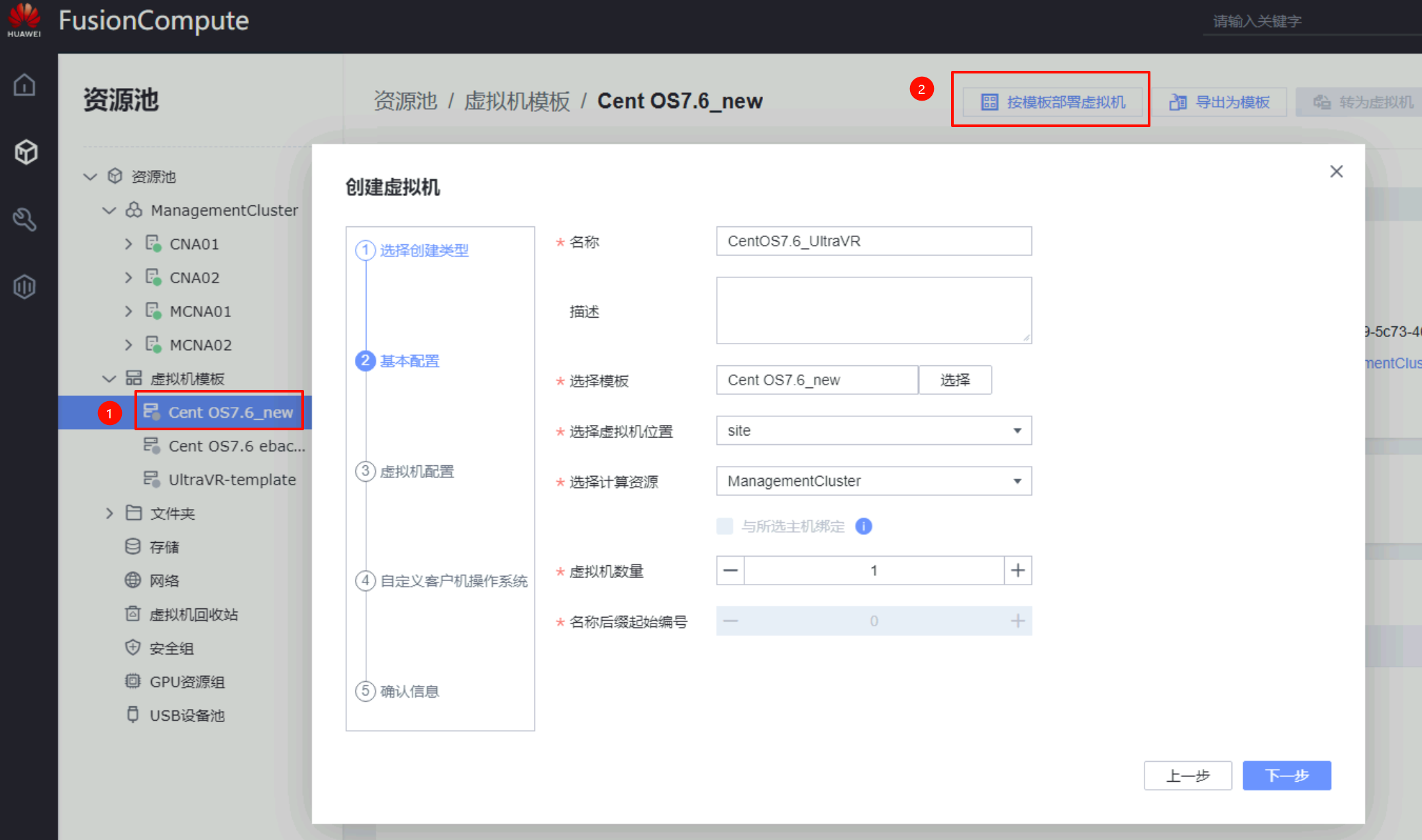
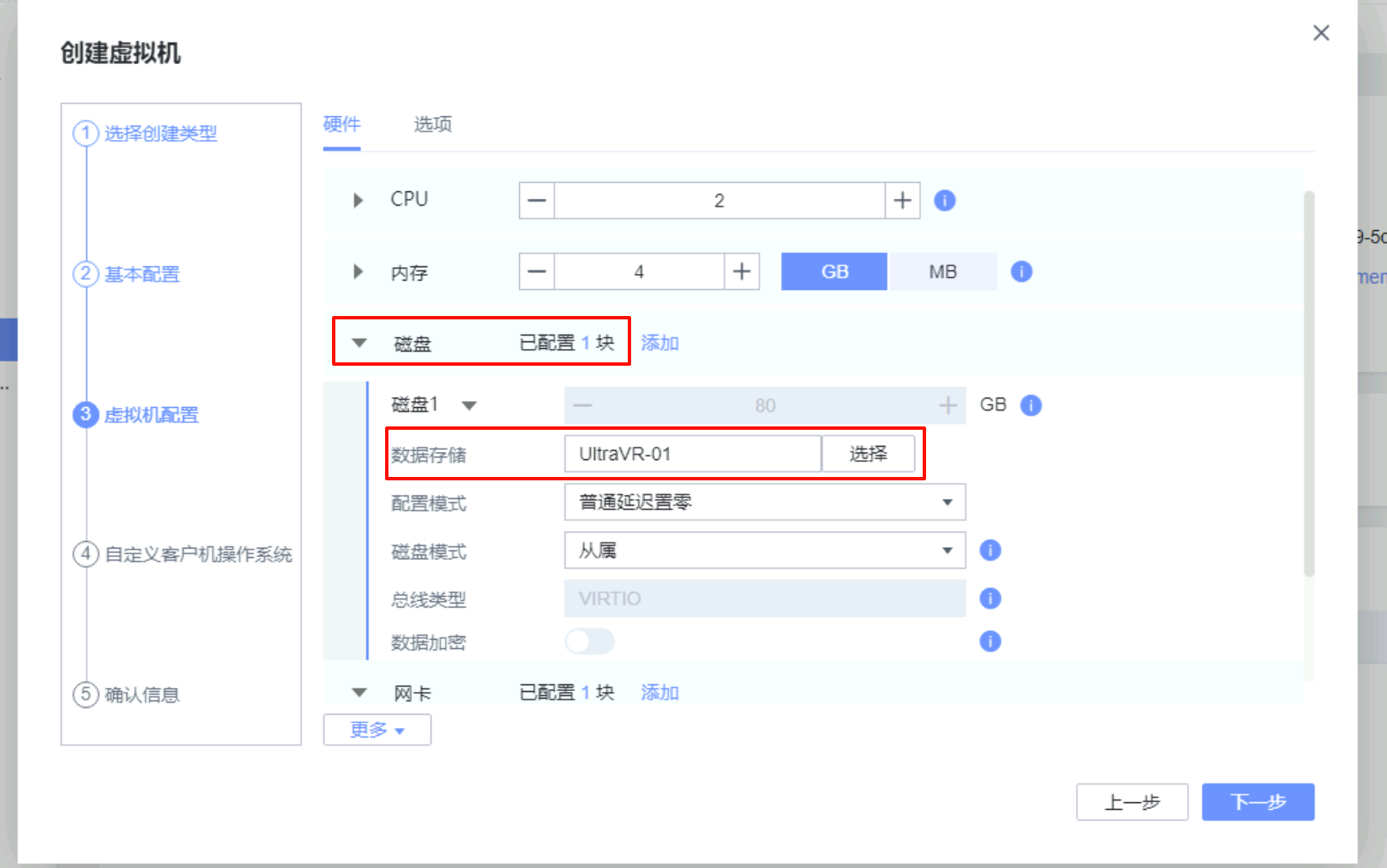
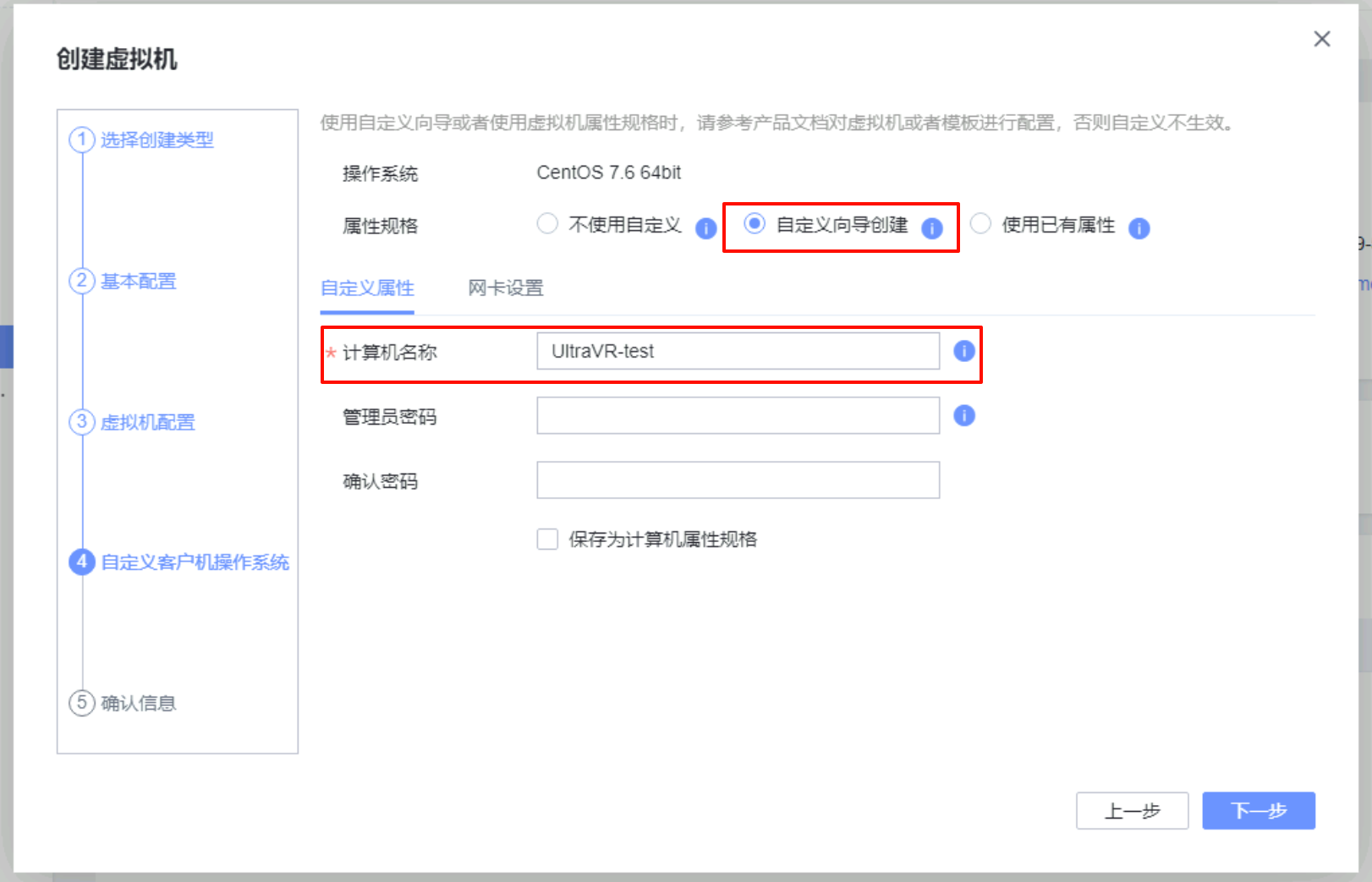
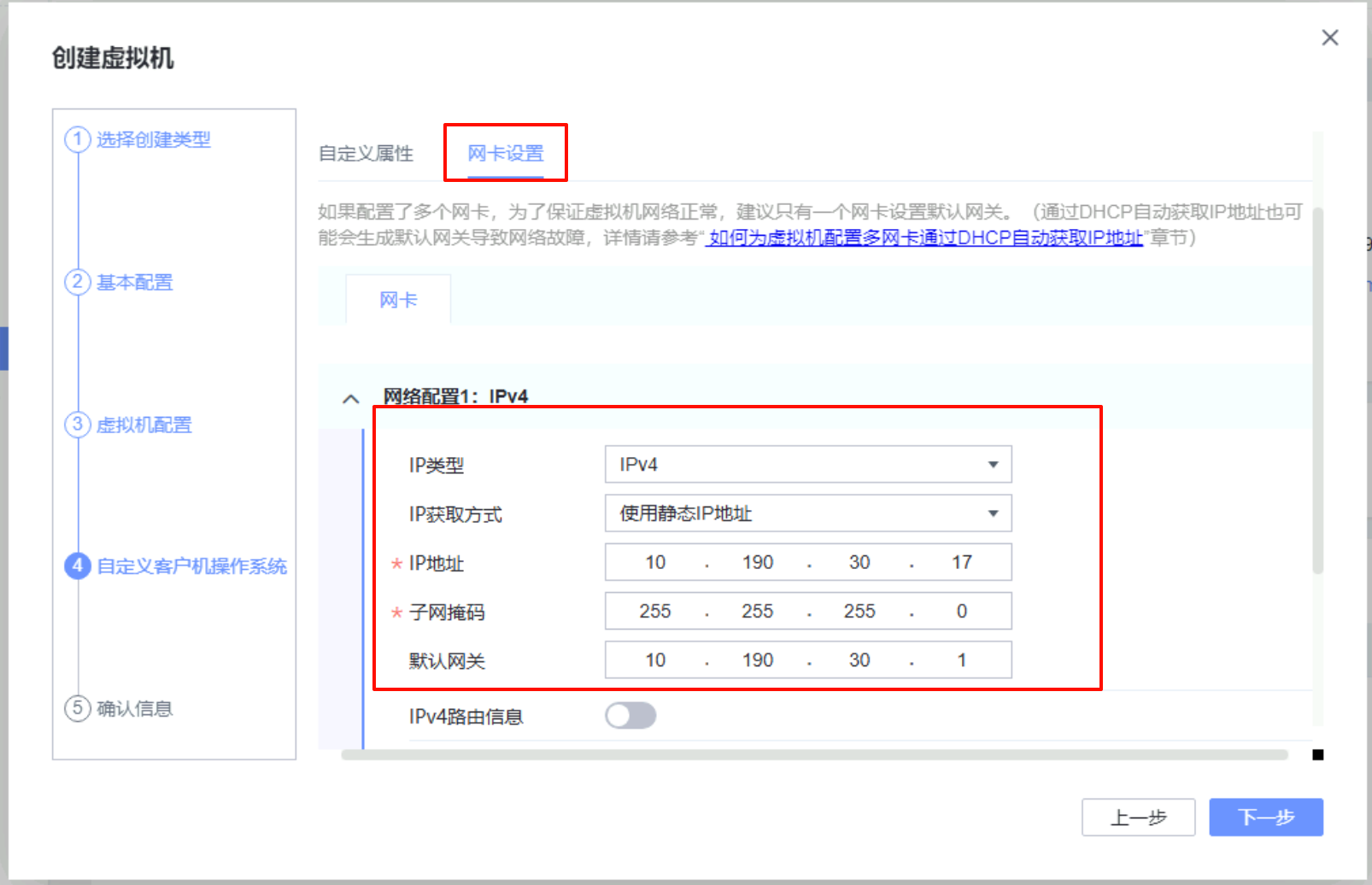
UltraVR容灾配置
通过https://UltraVR浮动IP地址:9443登录到UltraVR后台,默认账号admin、密码Admin@123
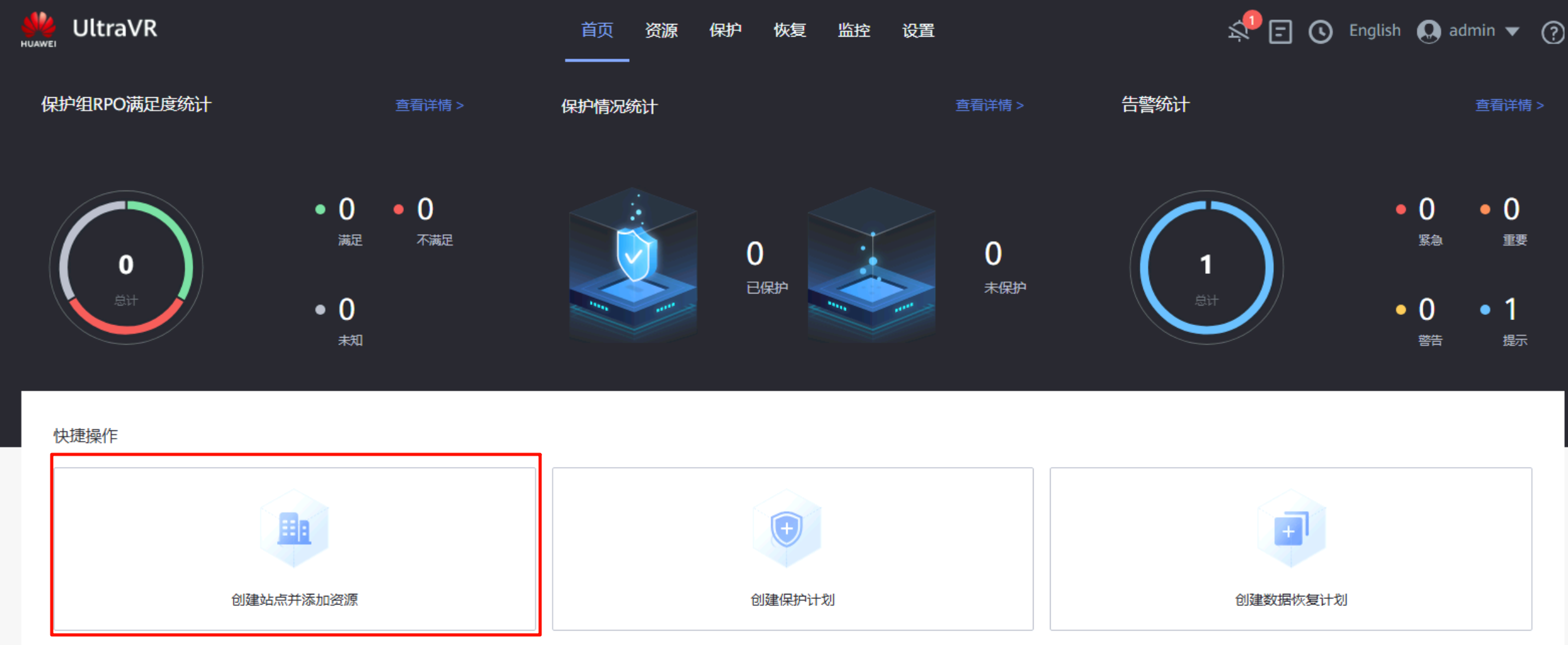
对接资源
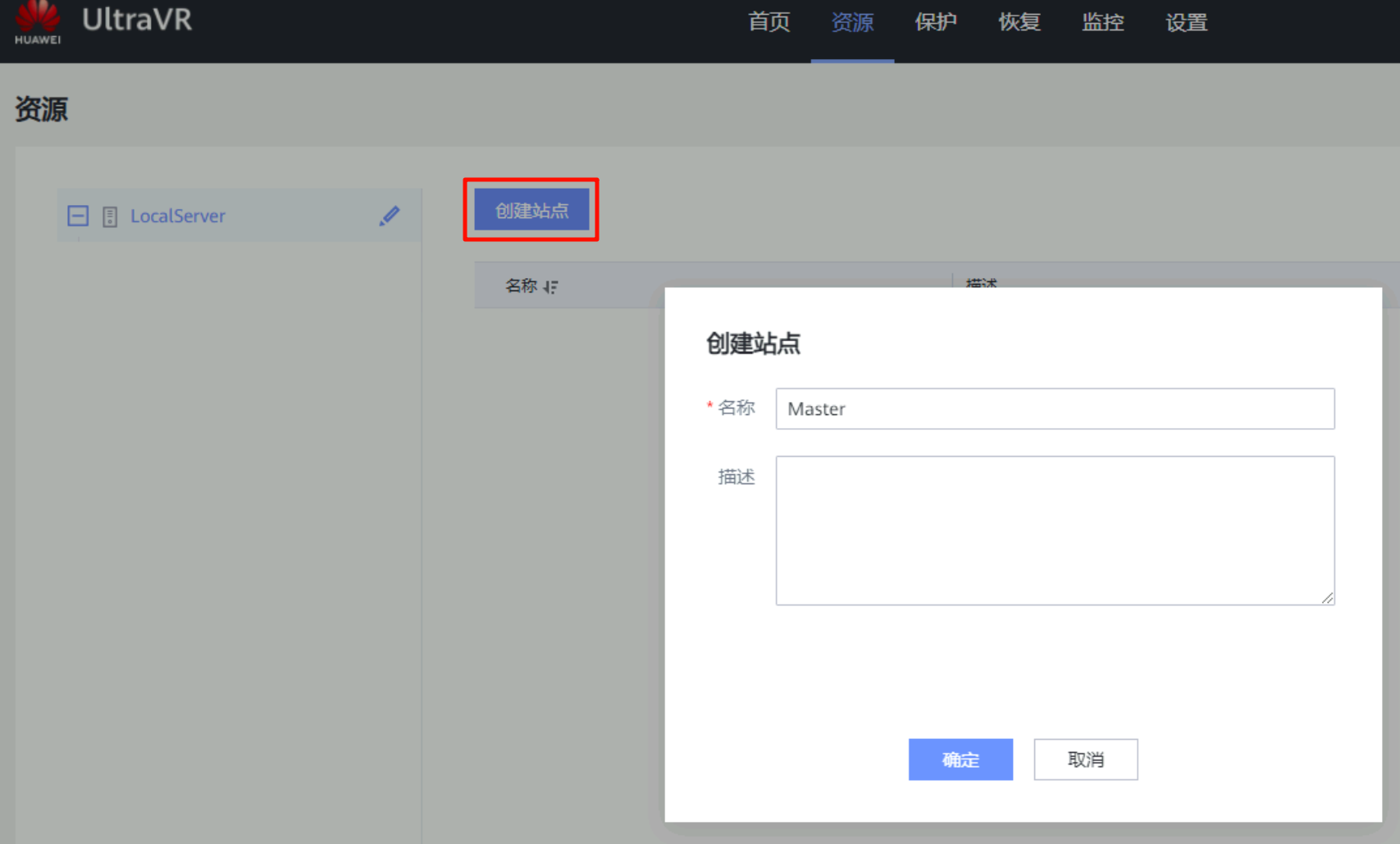
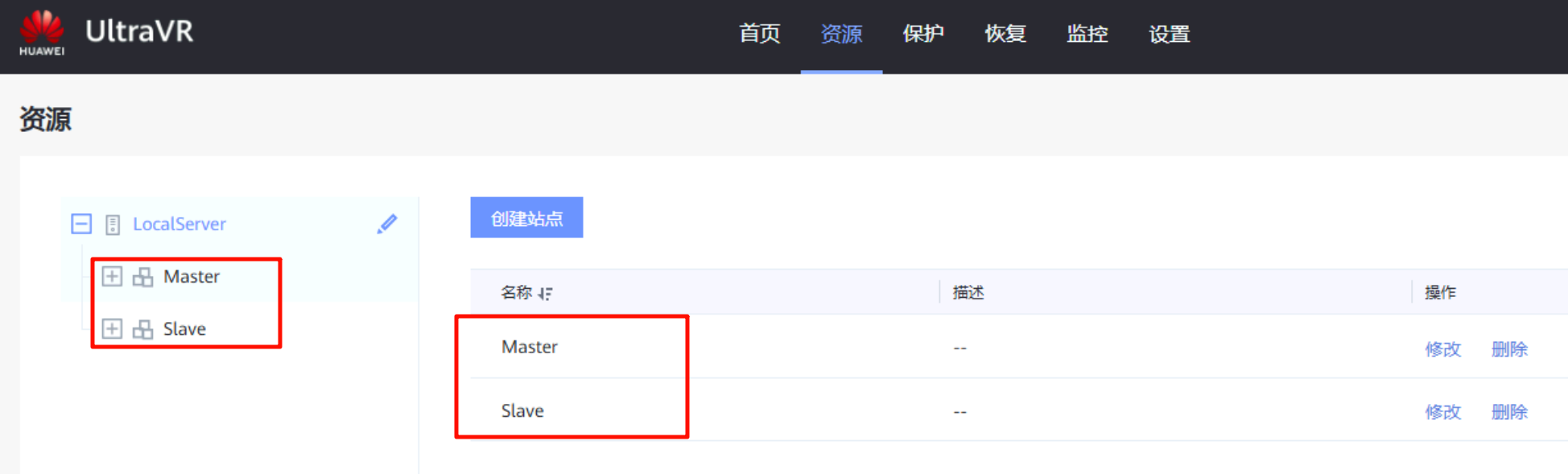
创建站点
创建生产站点Master和灾备站点Slave:两个站点都要对接各自的FusionCompute和OceanStor
对接存储资源:该IP地址为存储设备的登录地址,用户名密码均已提前创建(本地用户,管理员,全选登录方式,密码永不过期)
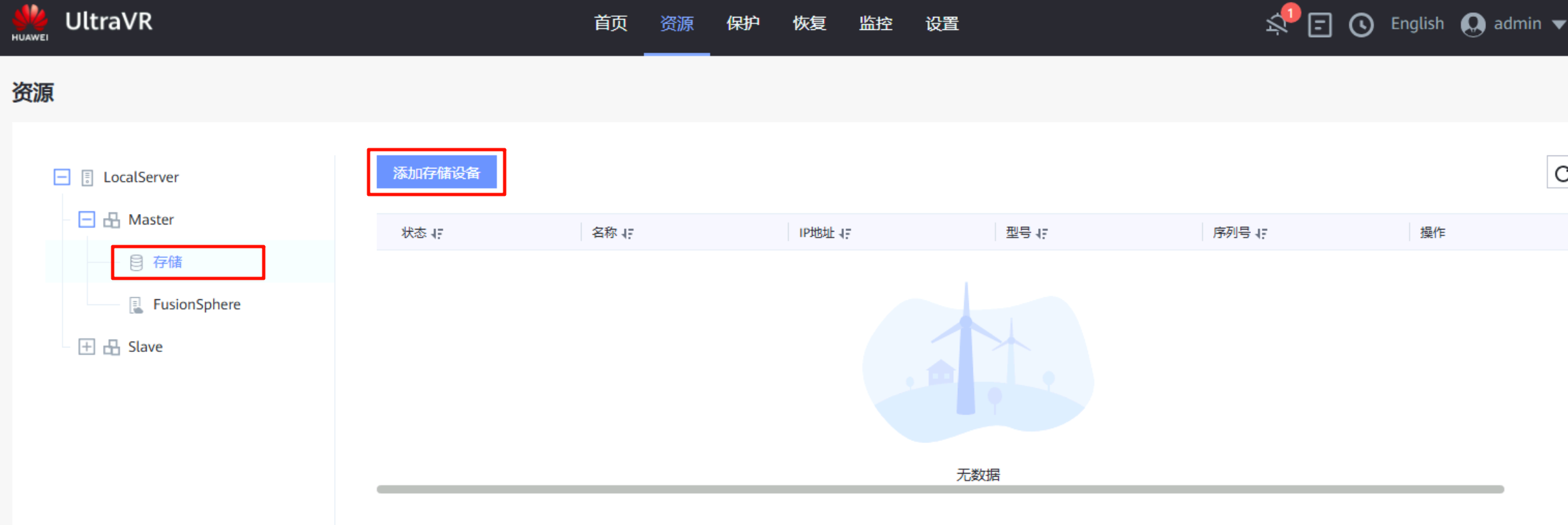
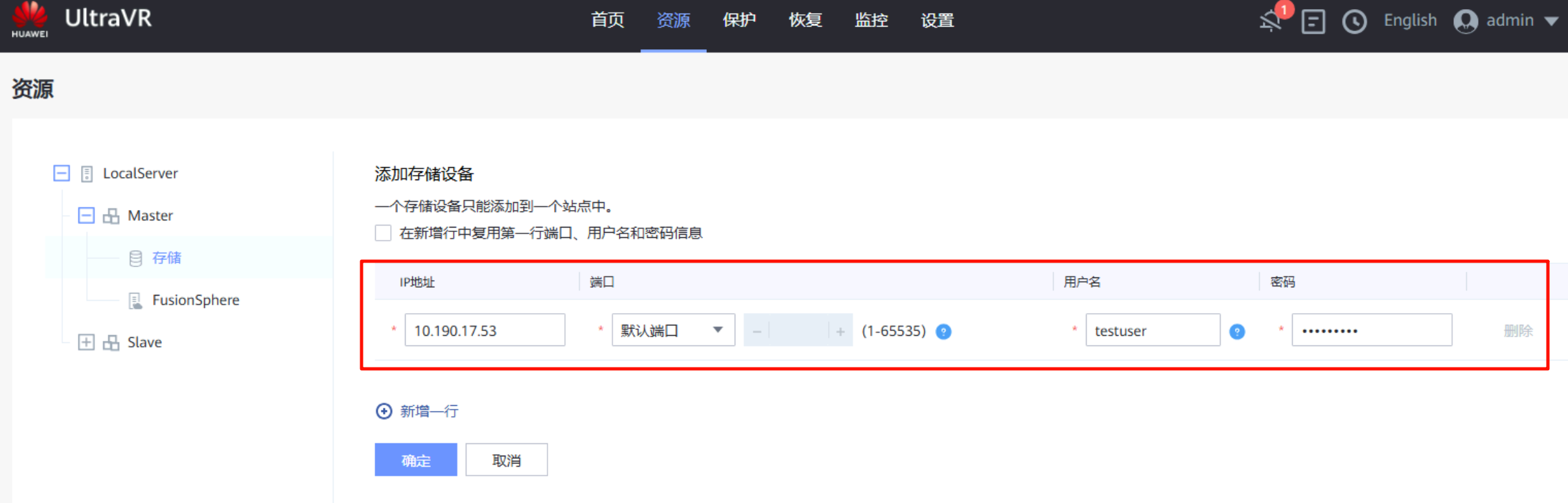
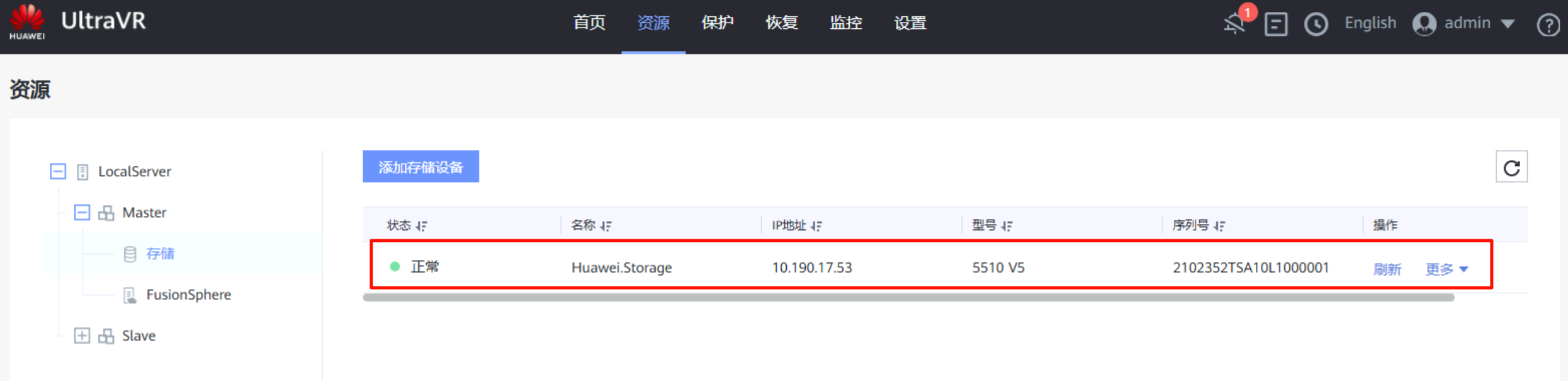
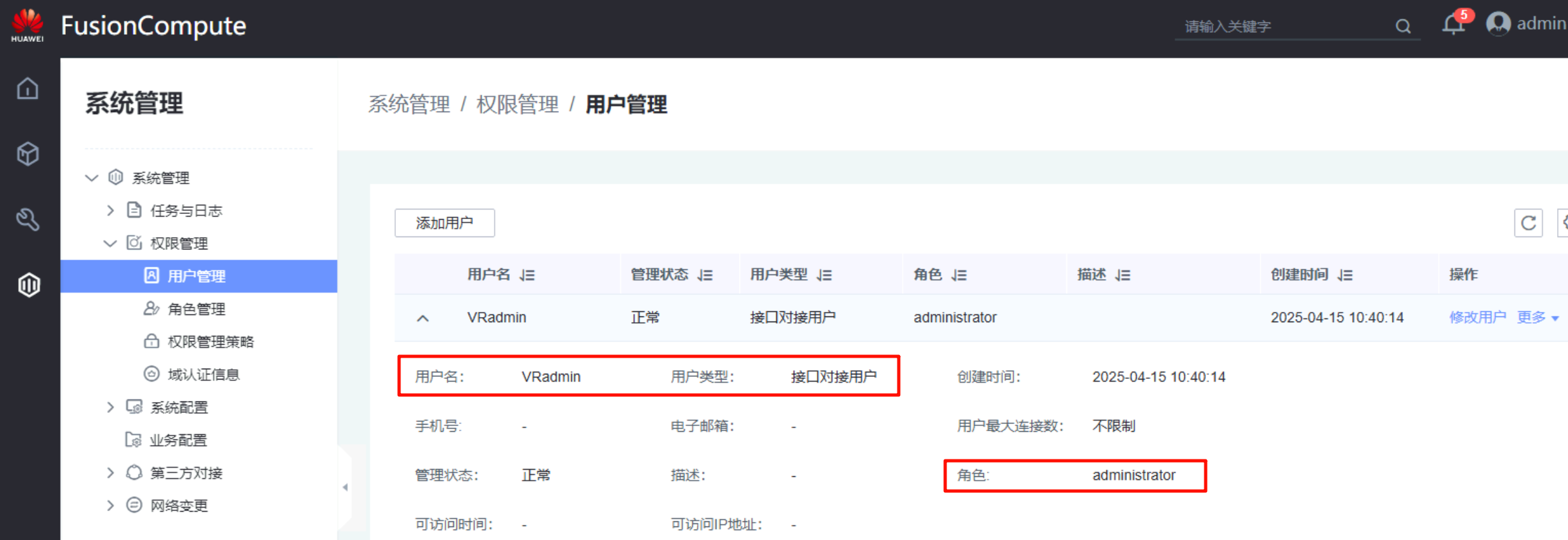
对接FusionConmpute平台:该IP为FC平台的登录地址,端口为7443(不是8443),用户名密码均已提前创建(接口对接用户、角色administrator)
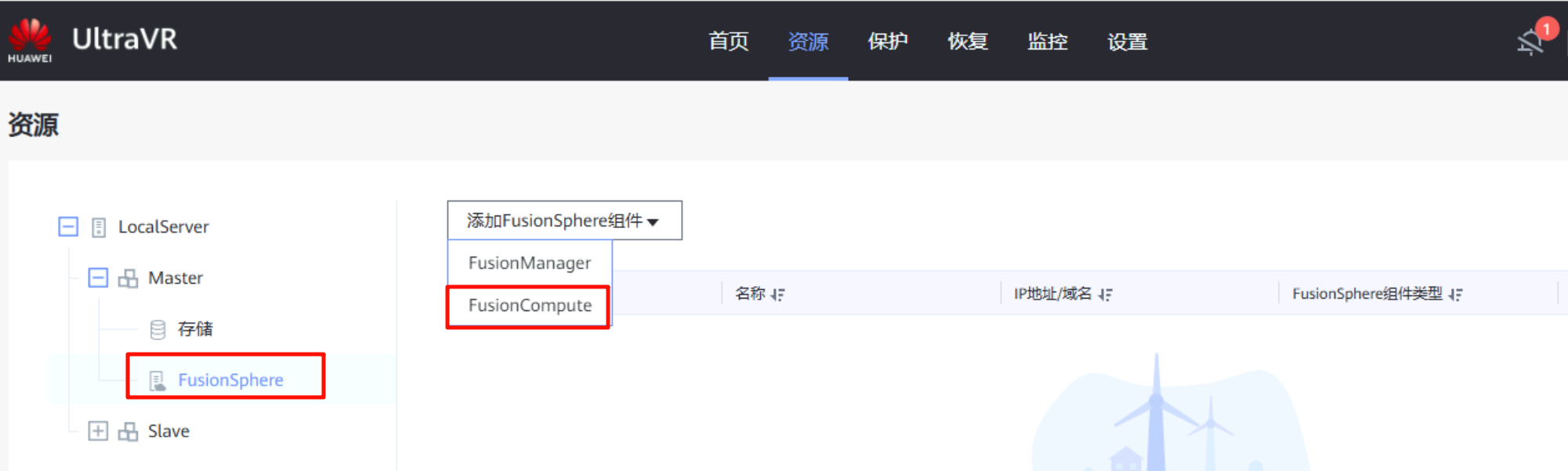
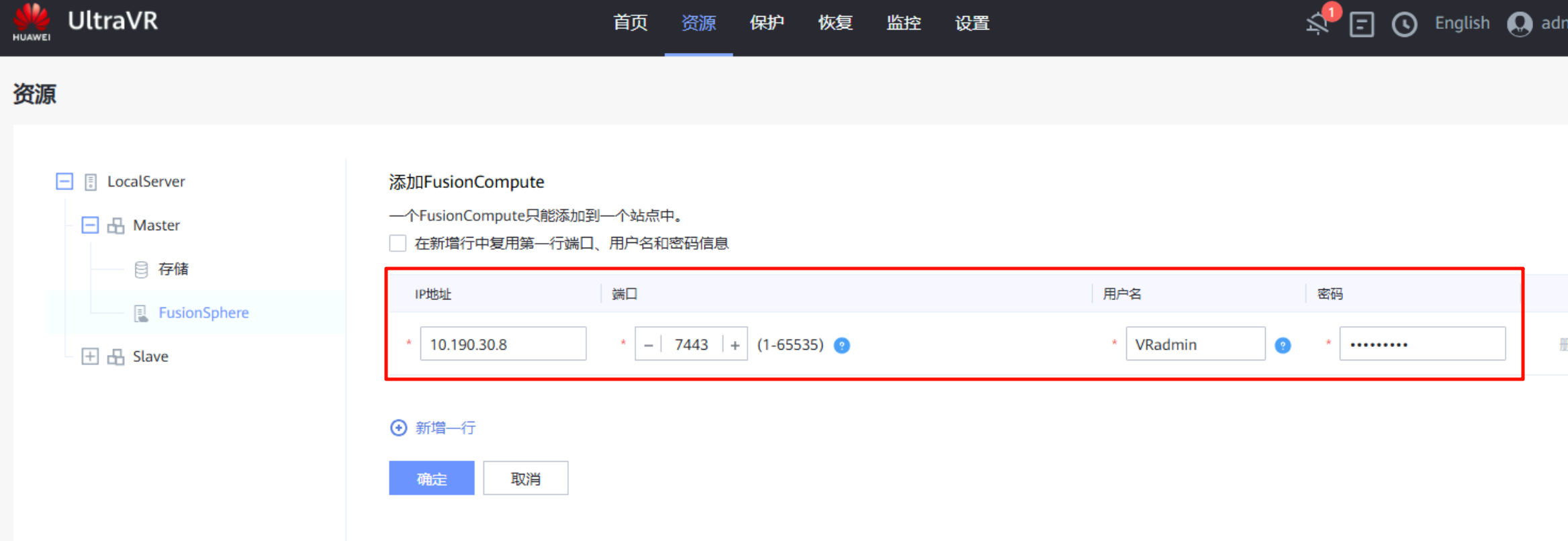
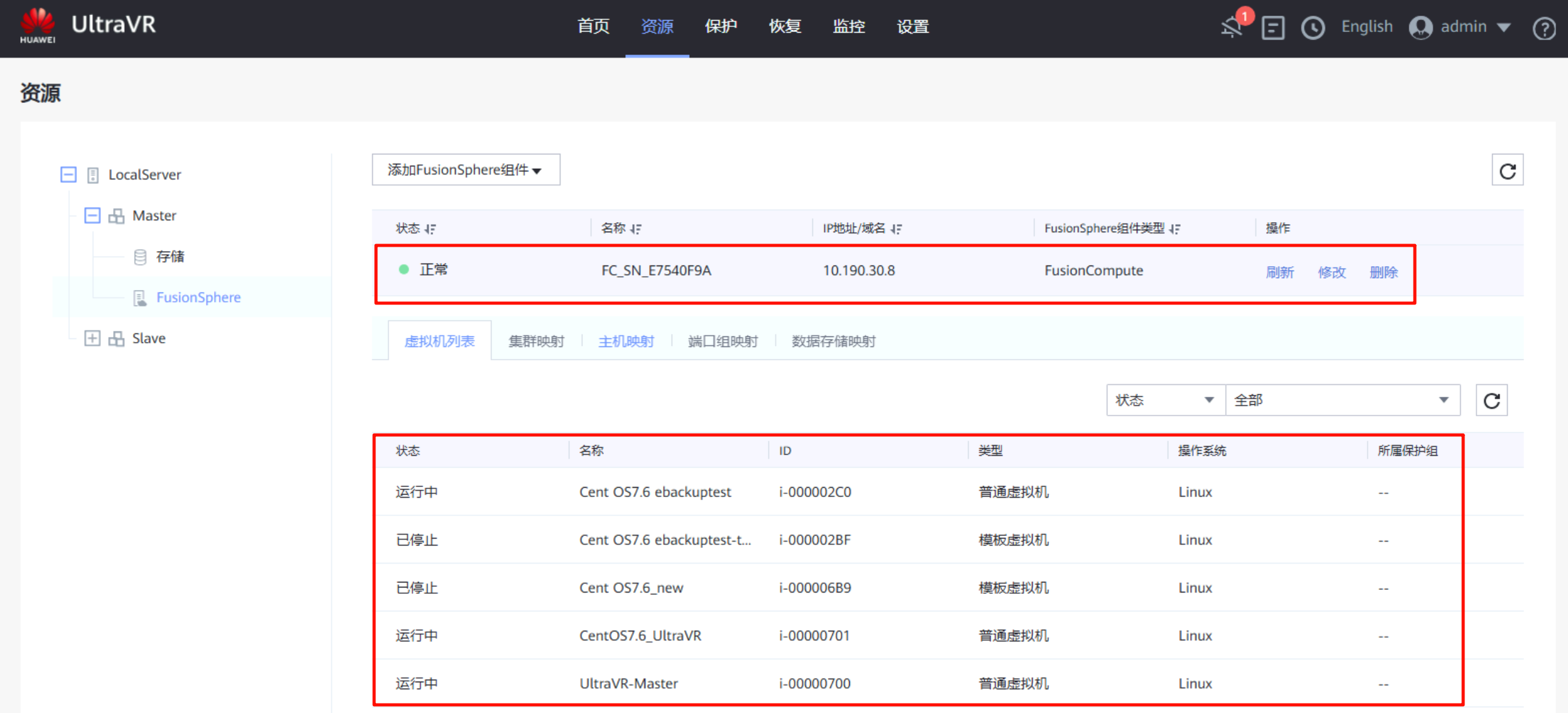
灾备站点:与生产站点一样,对接到灾备站点的FusionCompute和OceanStor
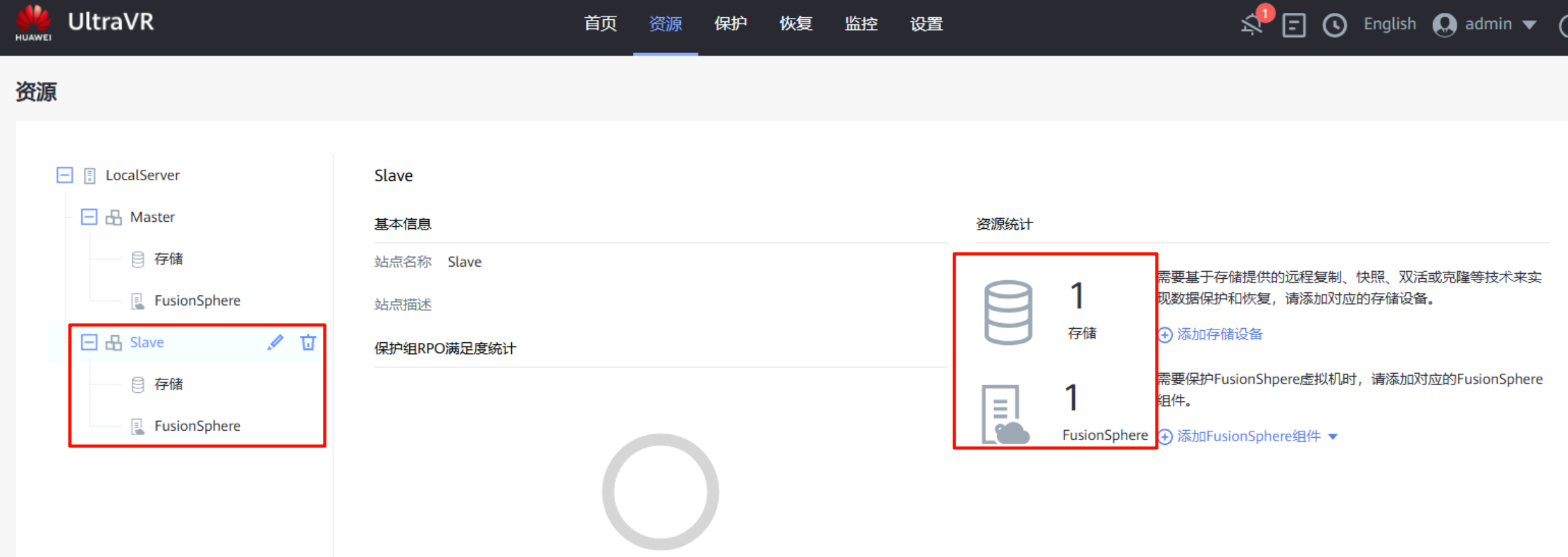
资源映射
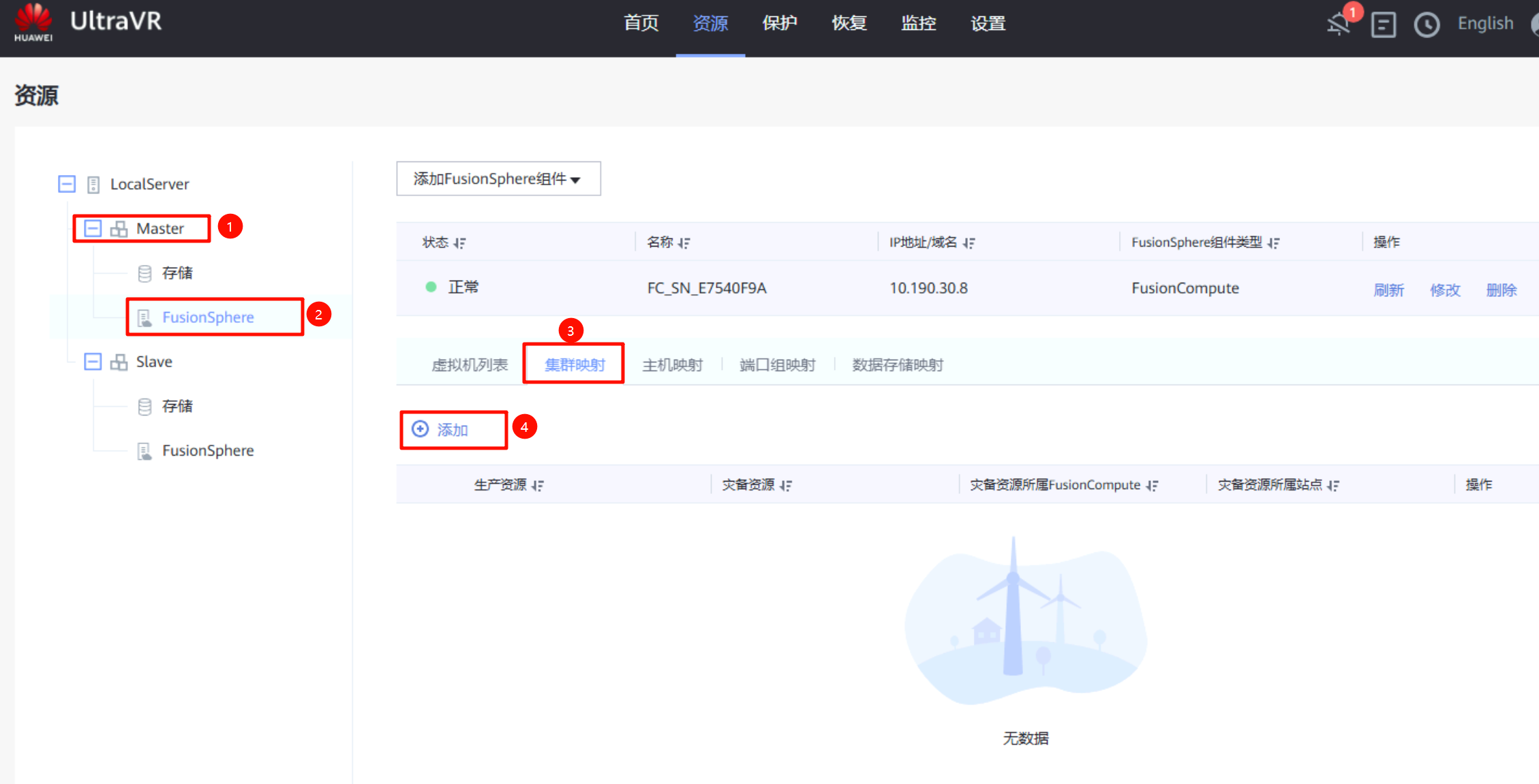
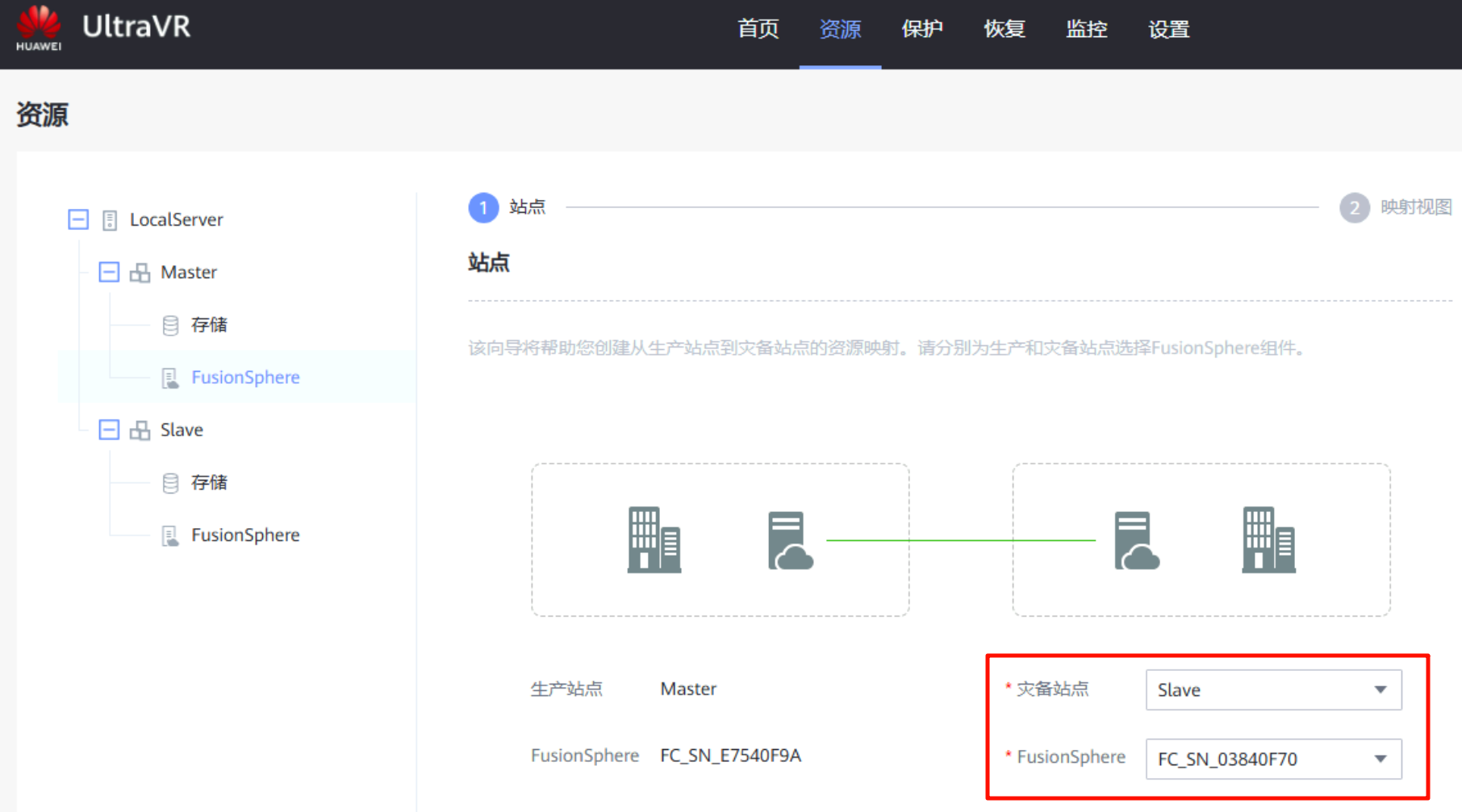
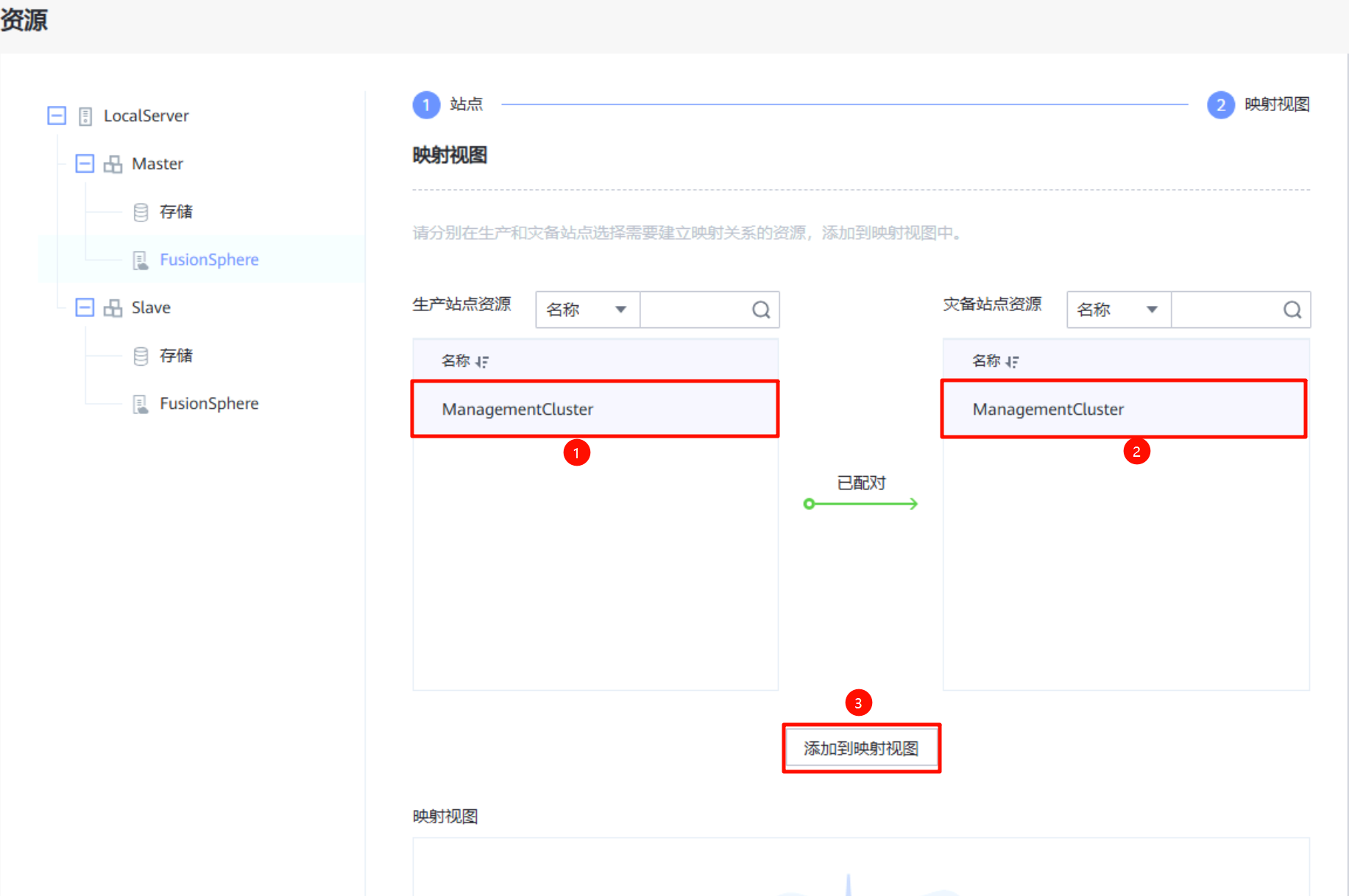
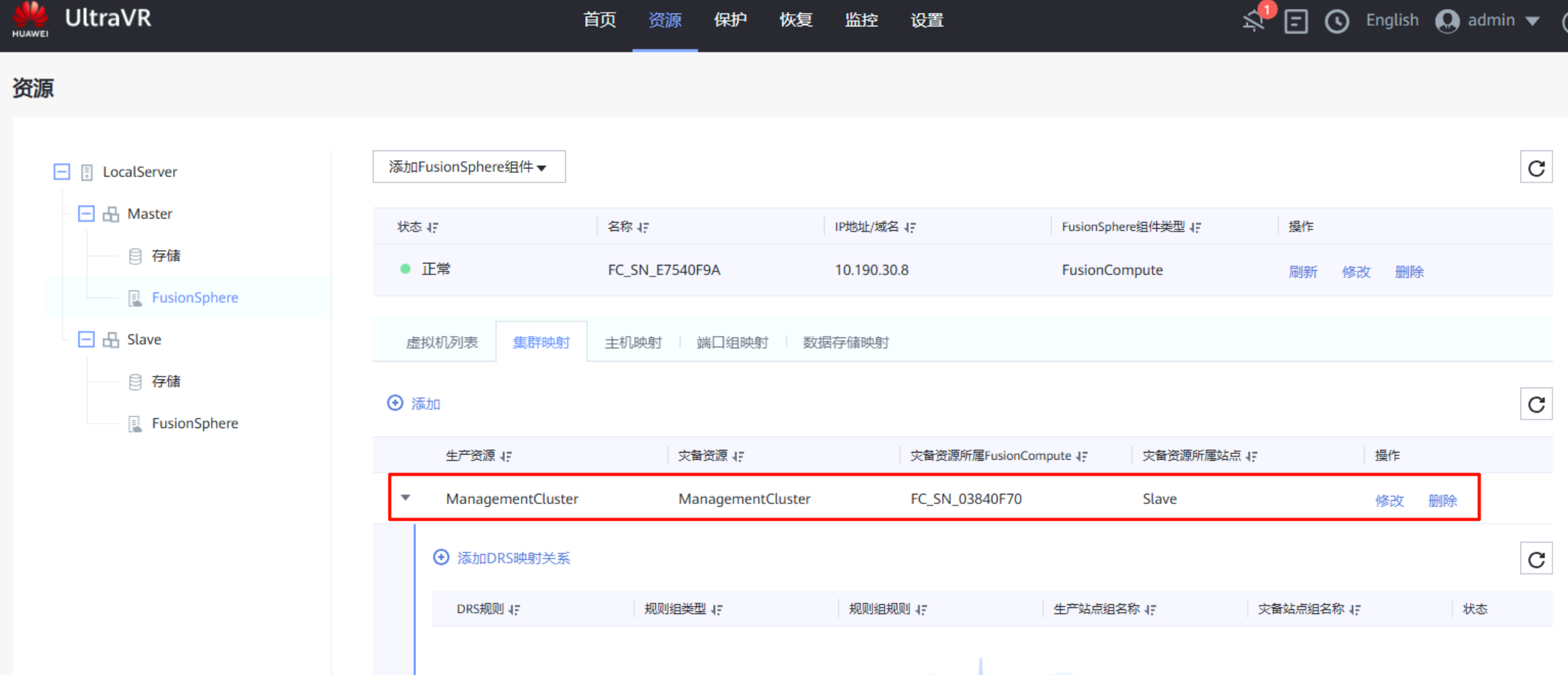
集群映射:在生产站点的FusionSphere上进行集群映射,将生产站点的集群与灾备站点的集群做映射
端口组映射:在生产站点的FusionSphere上进行端口组映射,将生产站点的端口组与灾备站点的端口组做映射(只需要映射做容灾的虚拟机所用到的端口组即可)
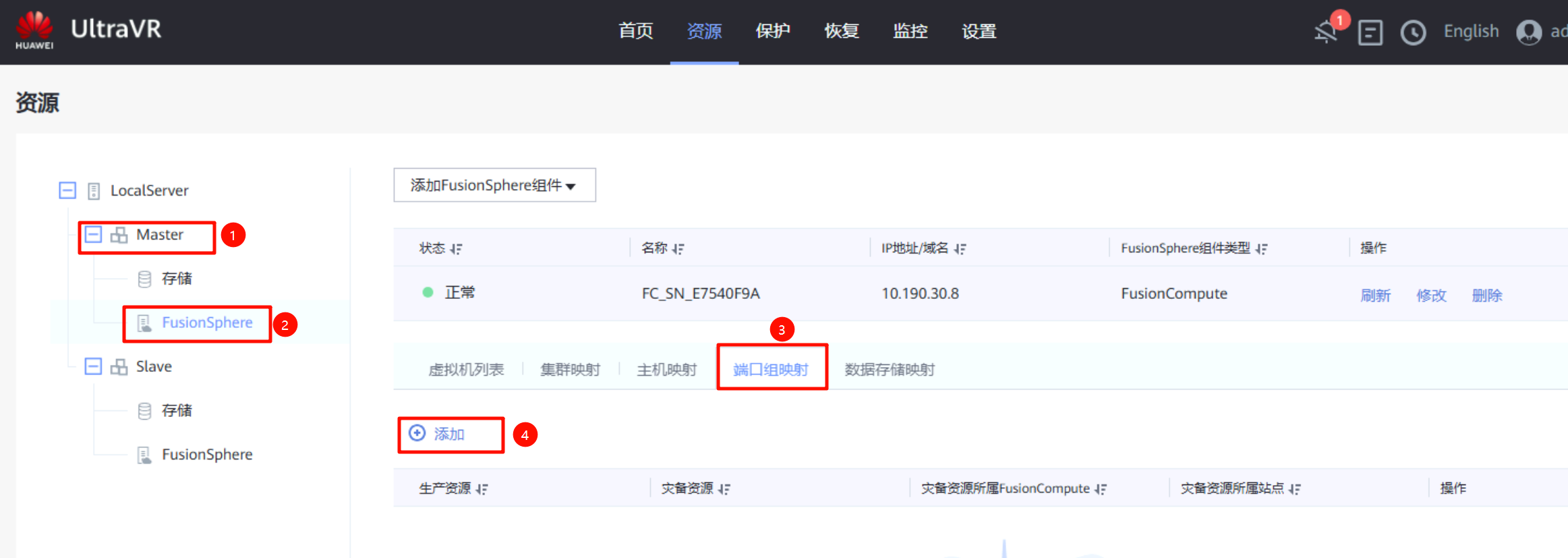
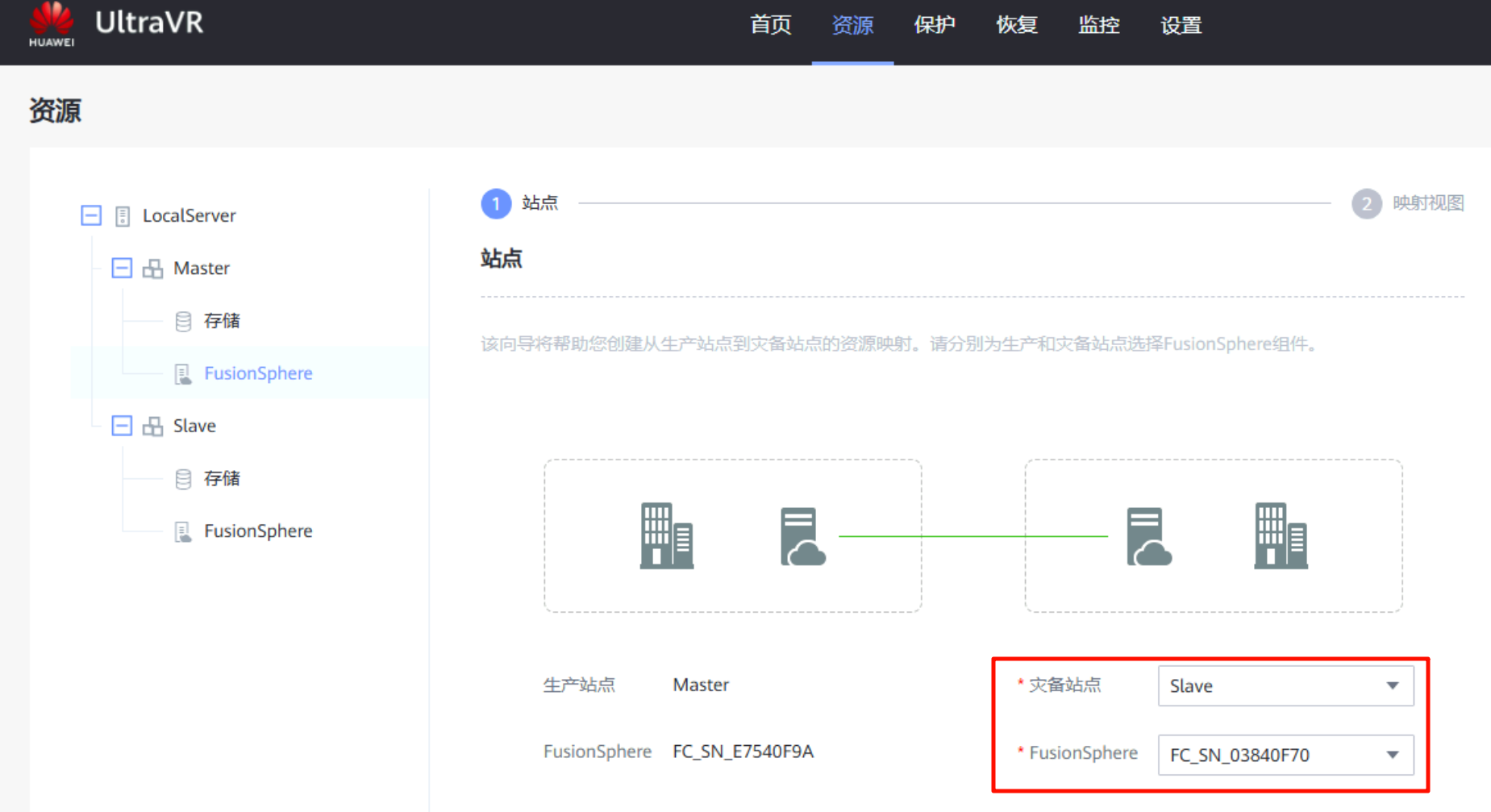
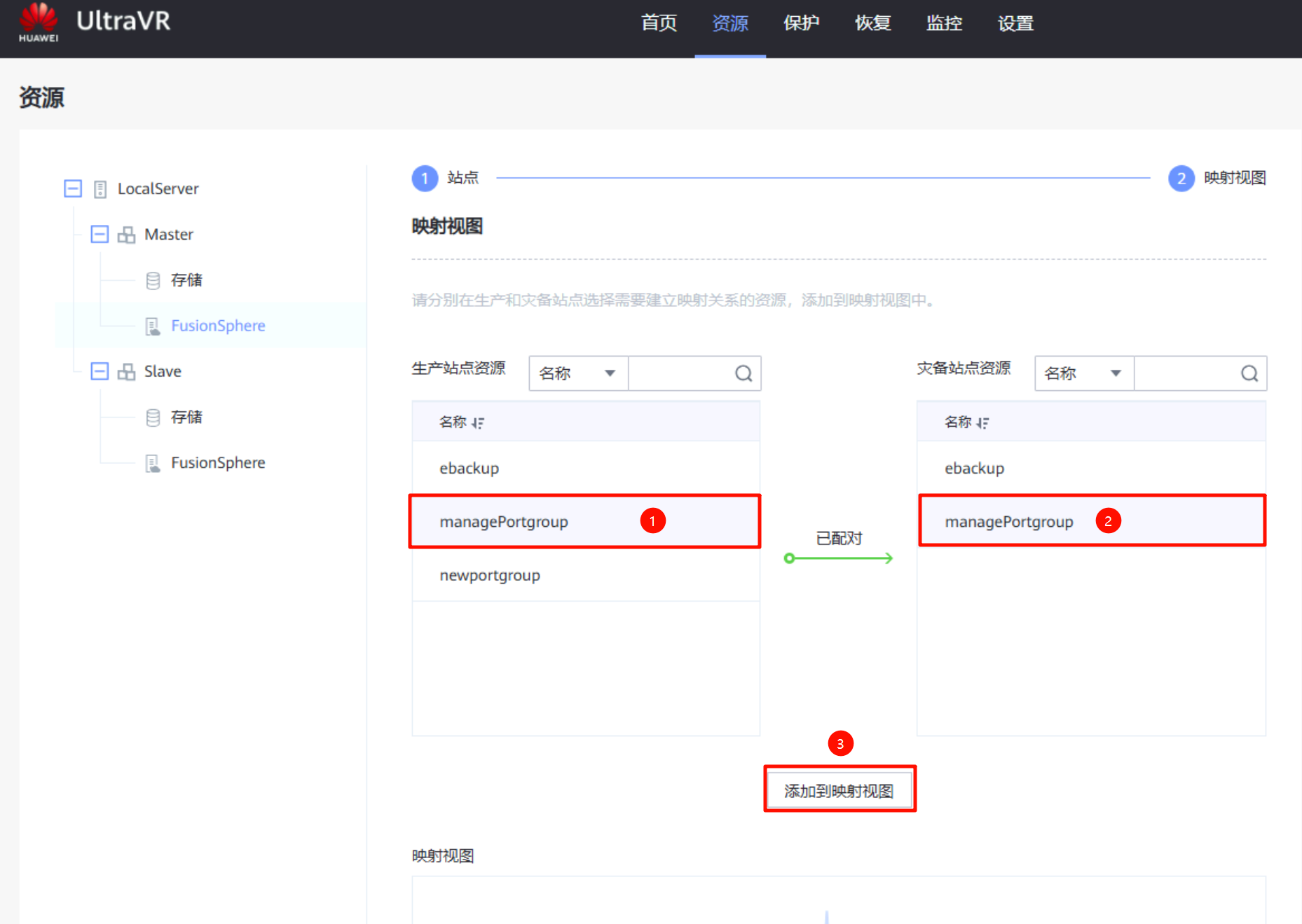
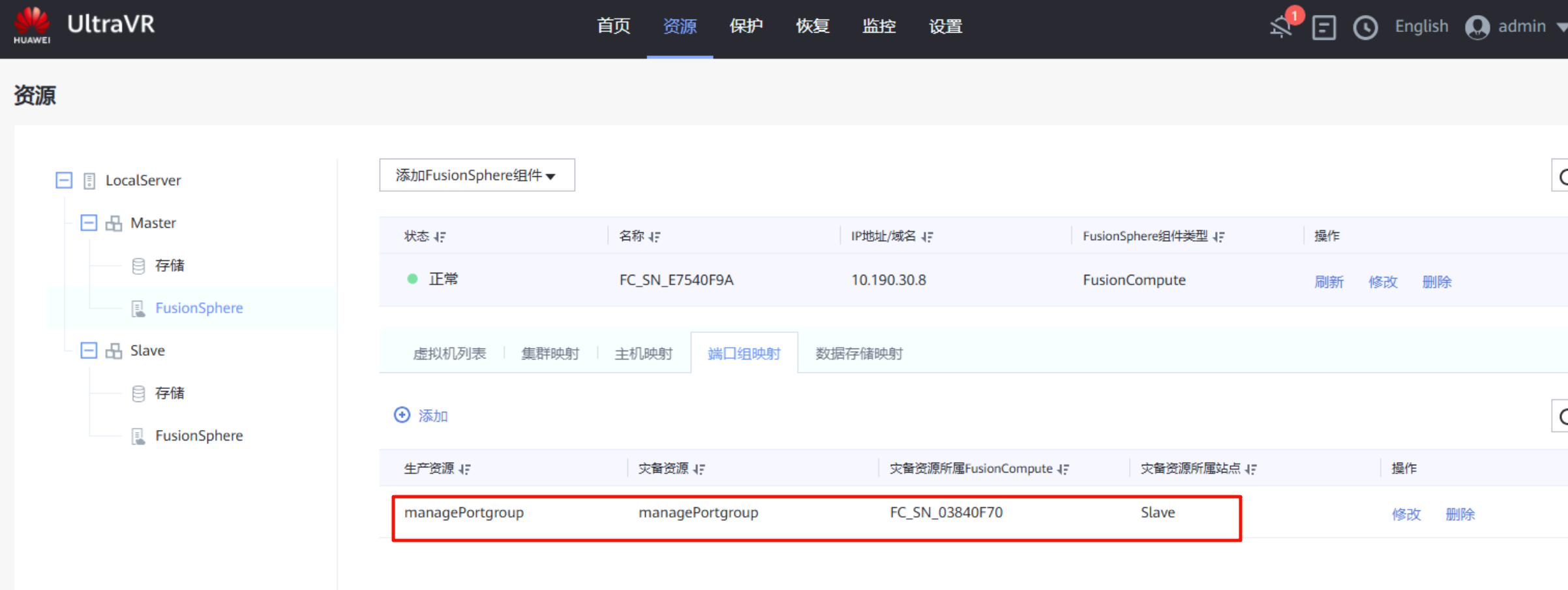
创建保护
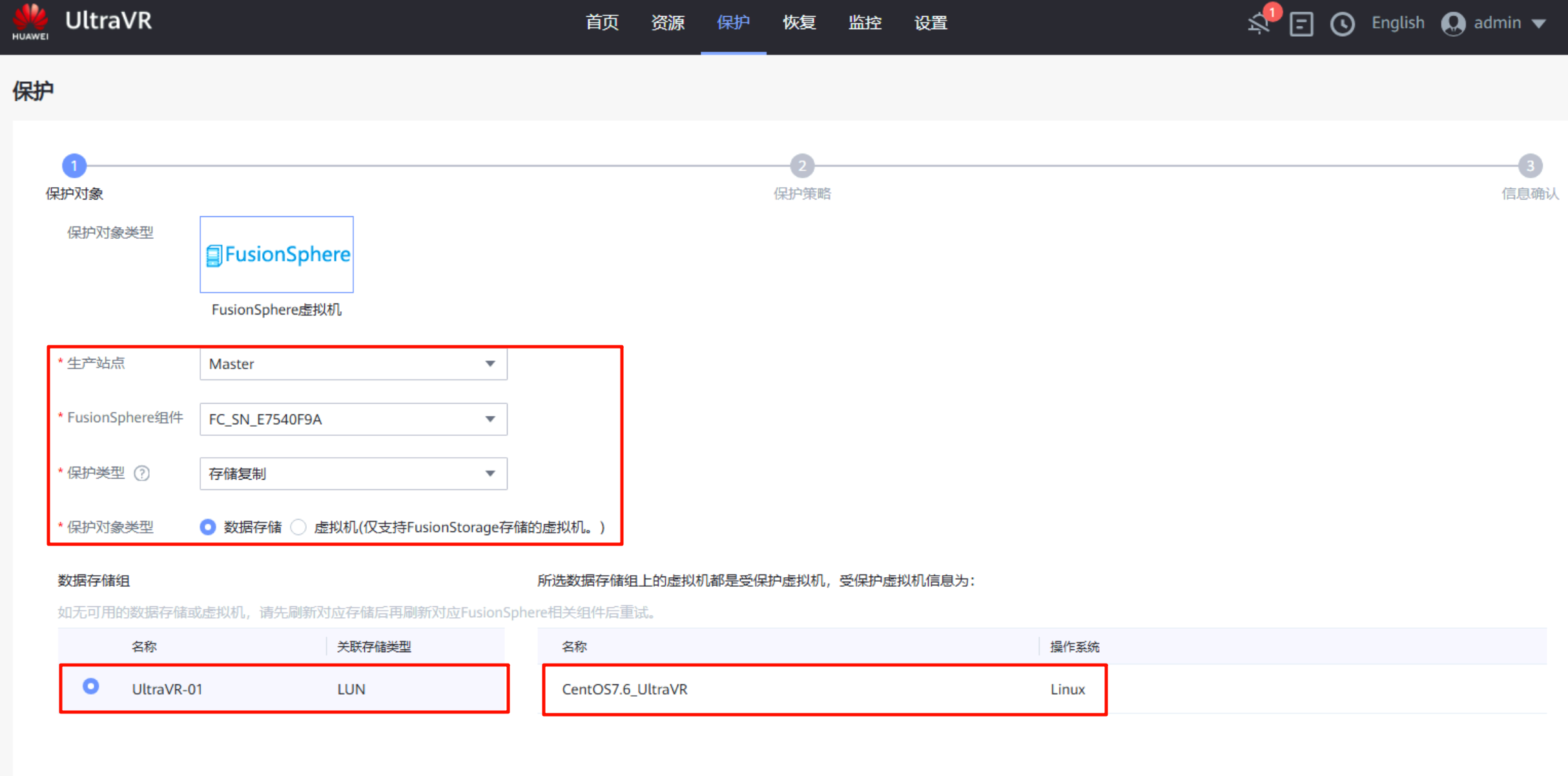
- 保护对象类型为
FusionSphere、生产站点选择Master站点、保护类型为存储复制、保护对象类型为数据存储、数据存储组为刚才所创建的LUN(安装在该LUN上的所有虚拟机都是受保护虚拟机)
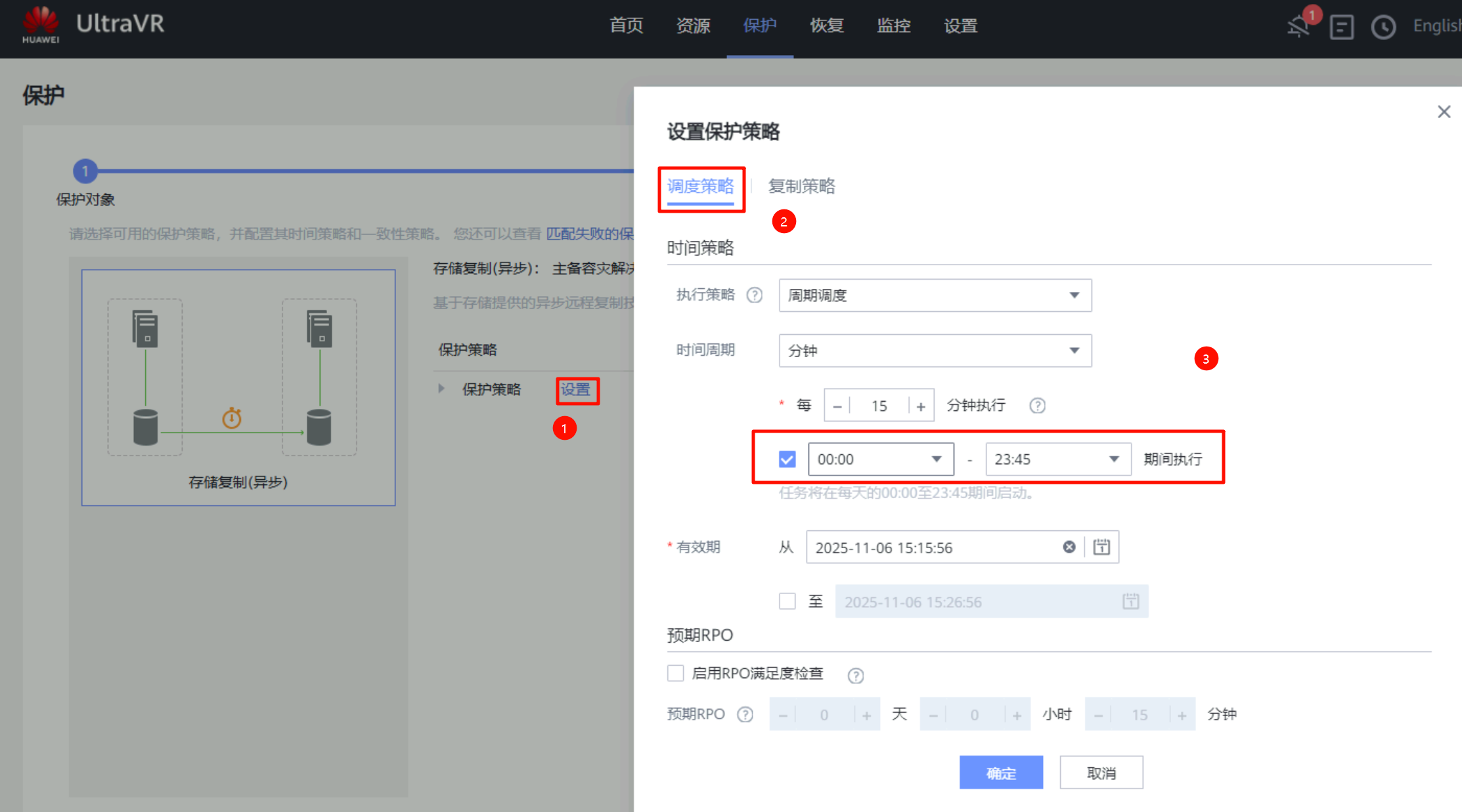
- 保护策略为自定义,该策略用于控制生产端与灾备端数据同步的触发时间,具体时间根据PRO恢复点目标要求进行设置
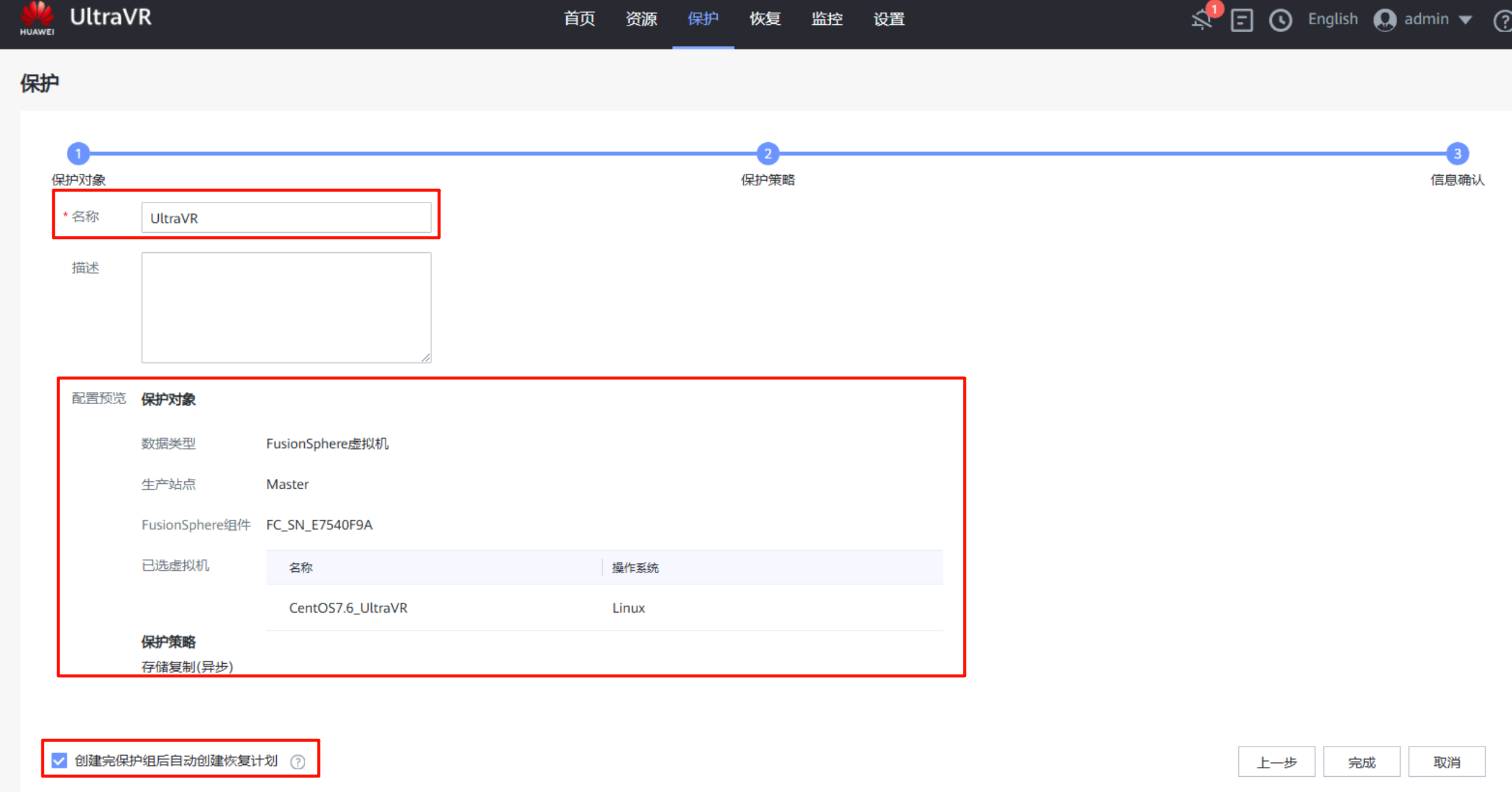
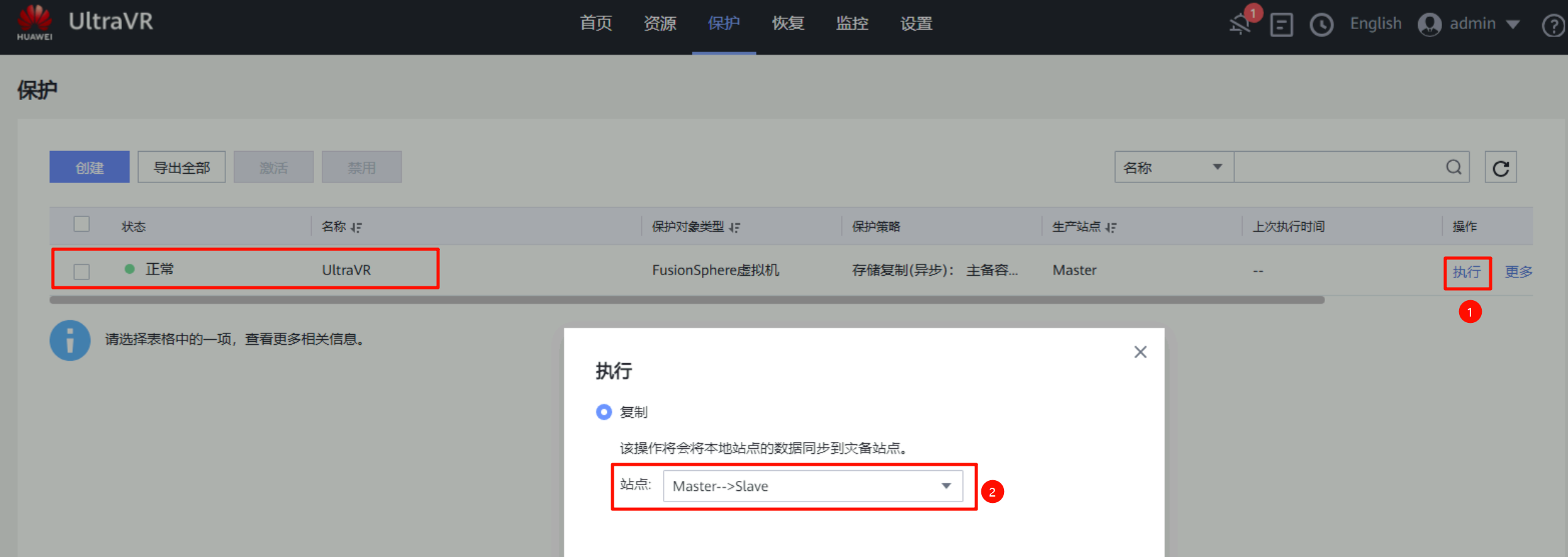
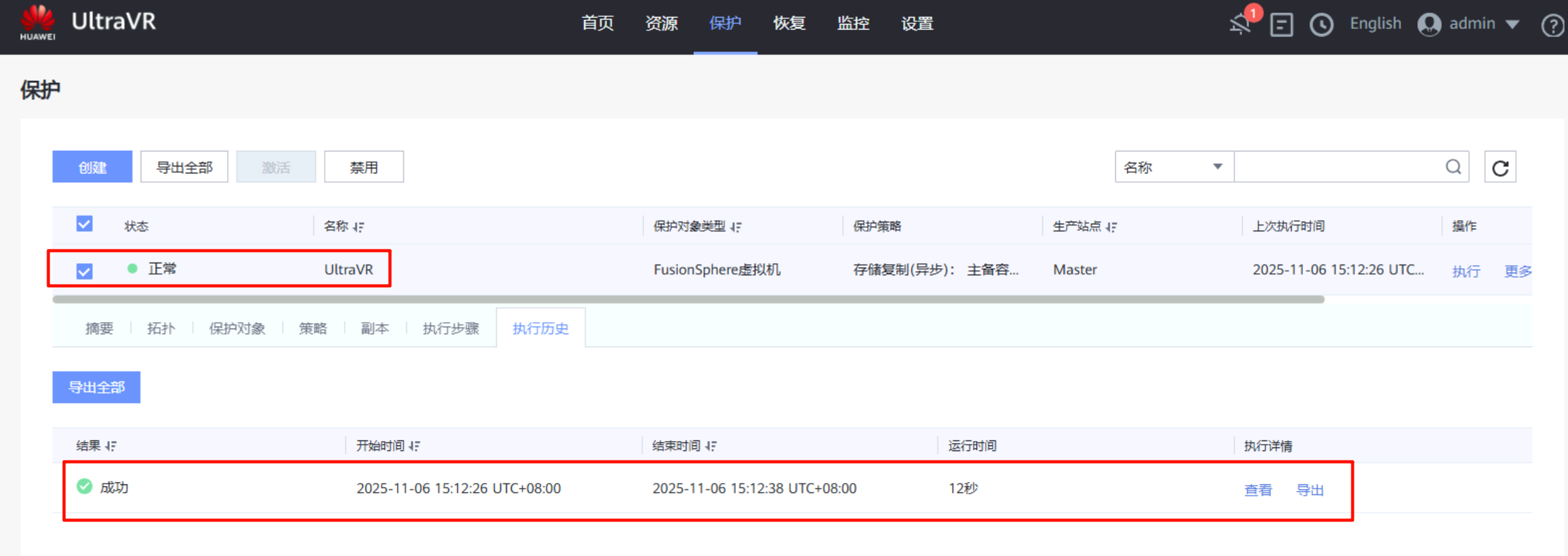
手动执行一次保护,UltraVR会将生产站点的数据同步到灾备站点
UltraVR容灾恢复
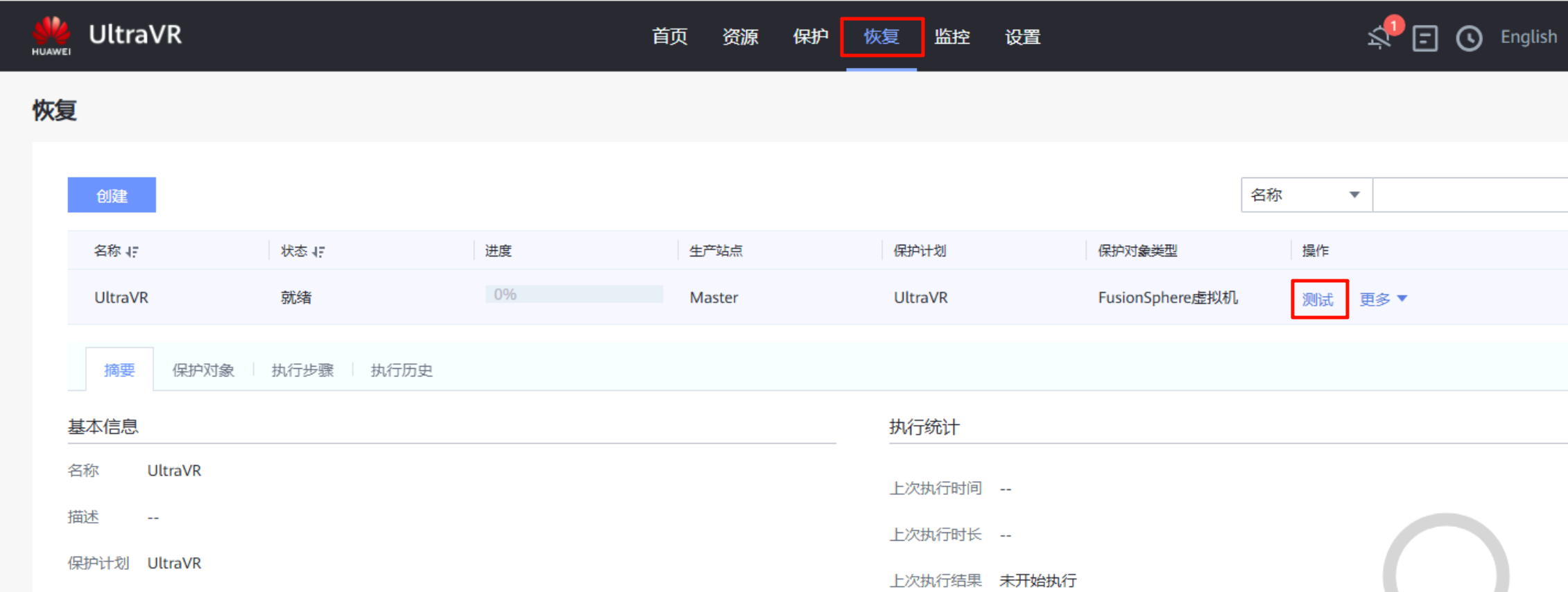
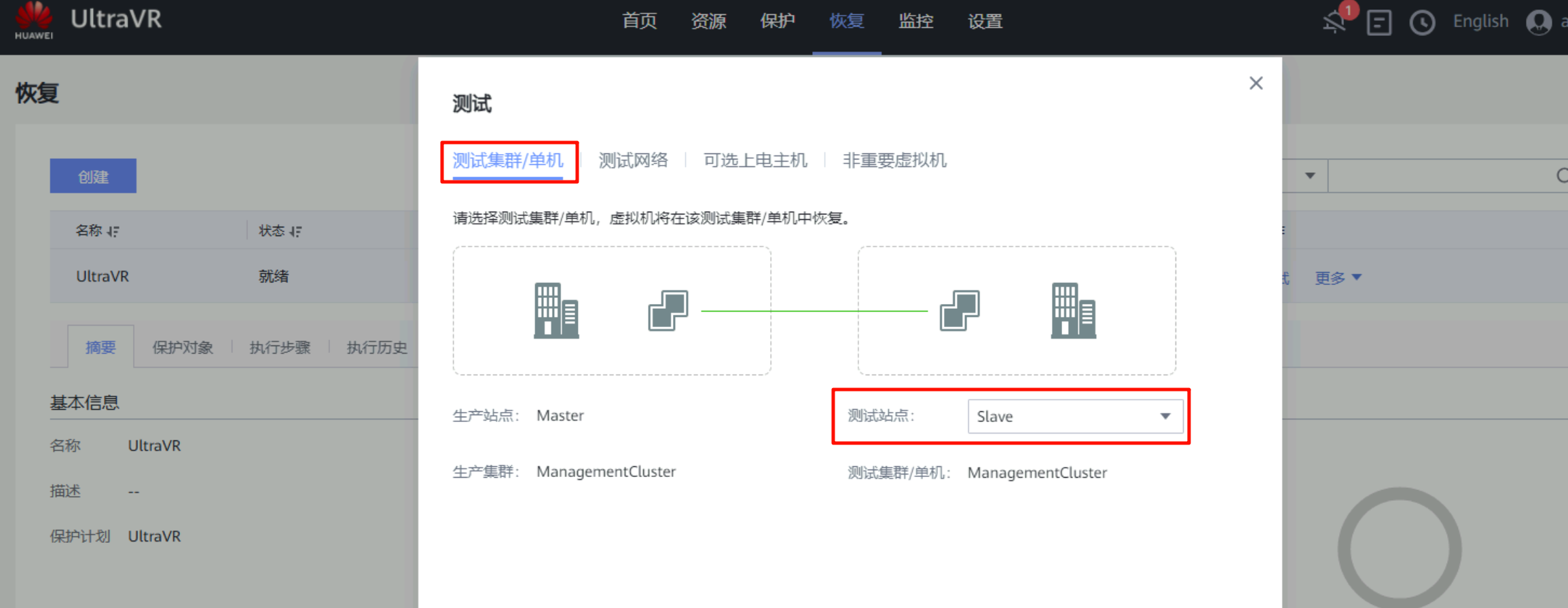
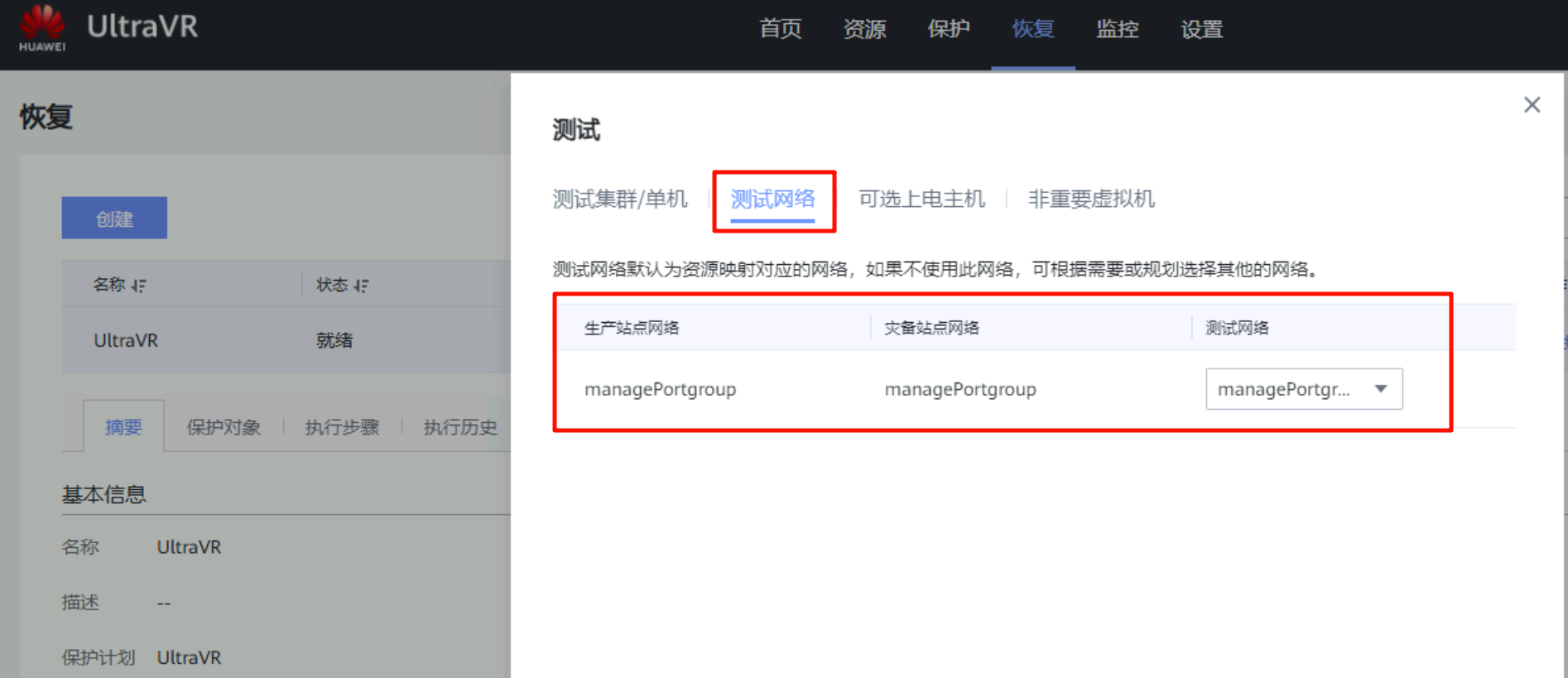
恢复测试
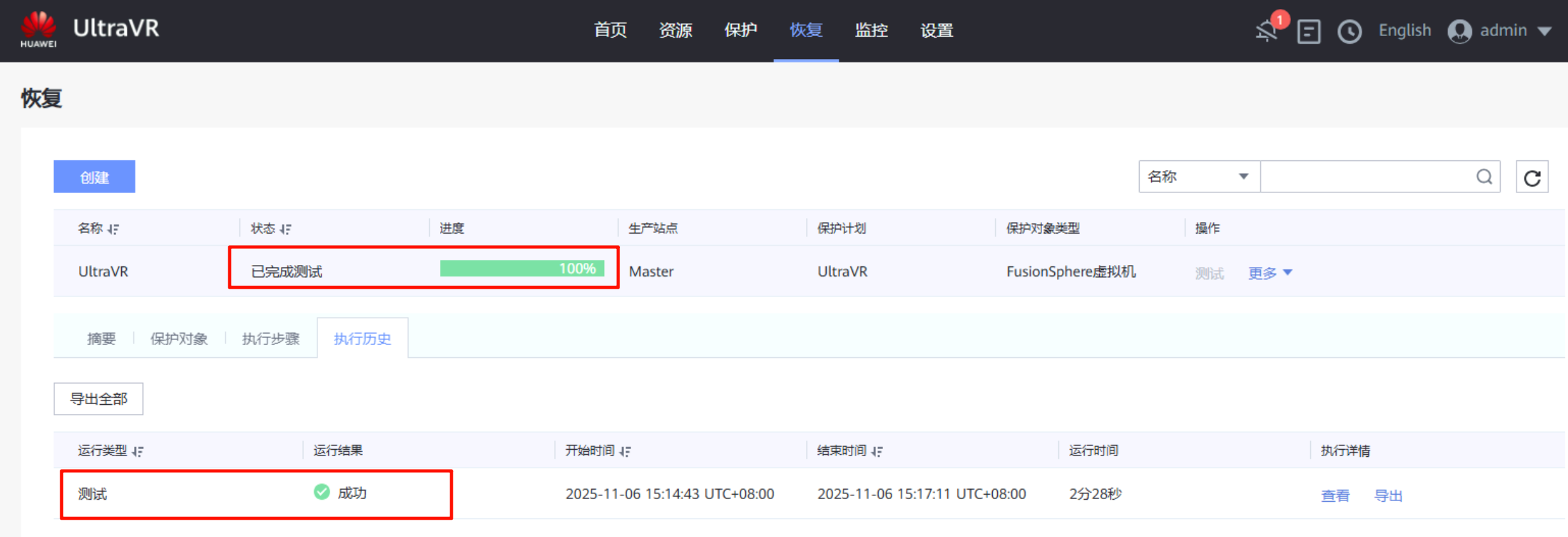
- 该测试是用于容灾演练,可以在不影响生产业务的前提下,验证恢复计划的可行性、RTO目标达成度及灾备数据有效性等
- 测试成功后会在灾备站点的FusionCompute生成一个与生产站点一样的虚拟机
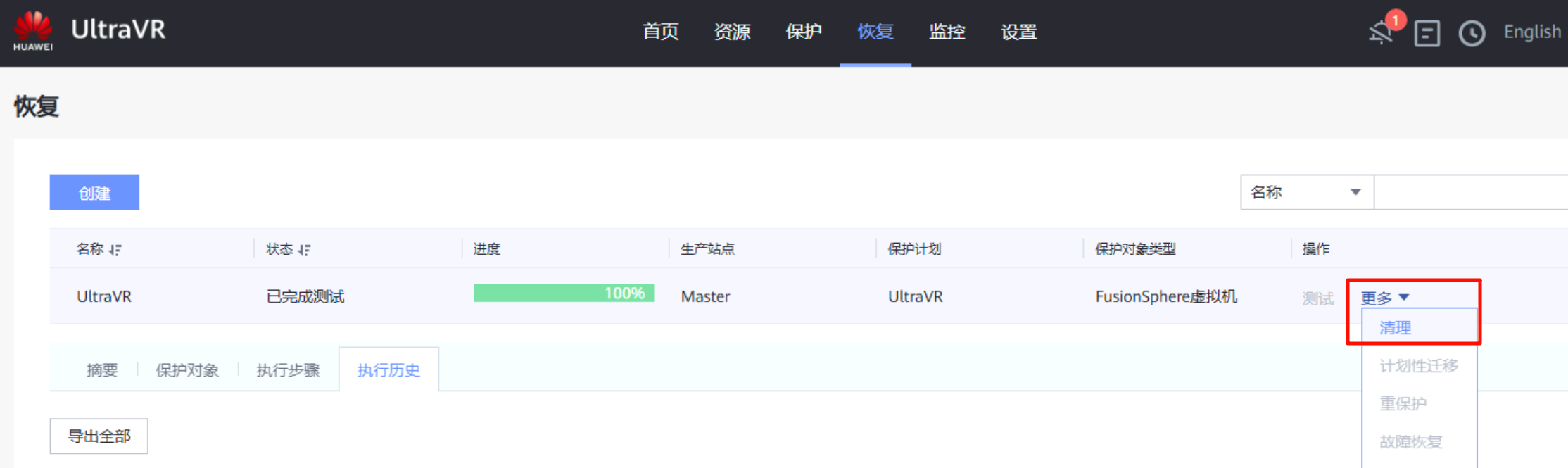
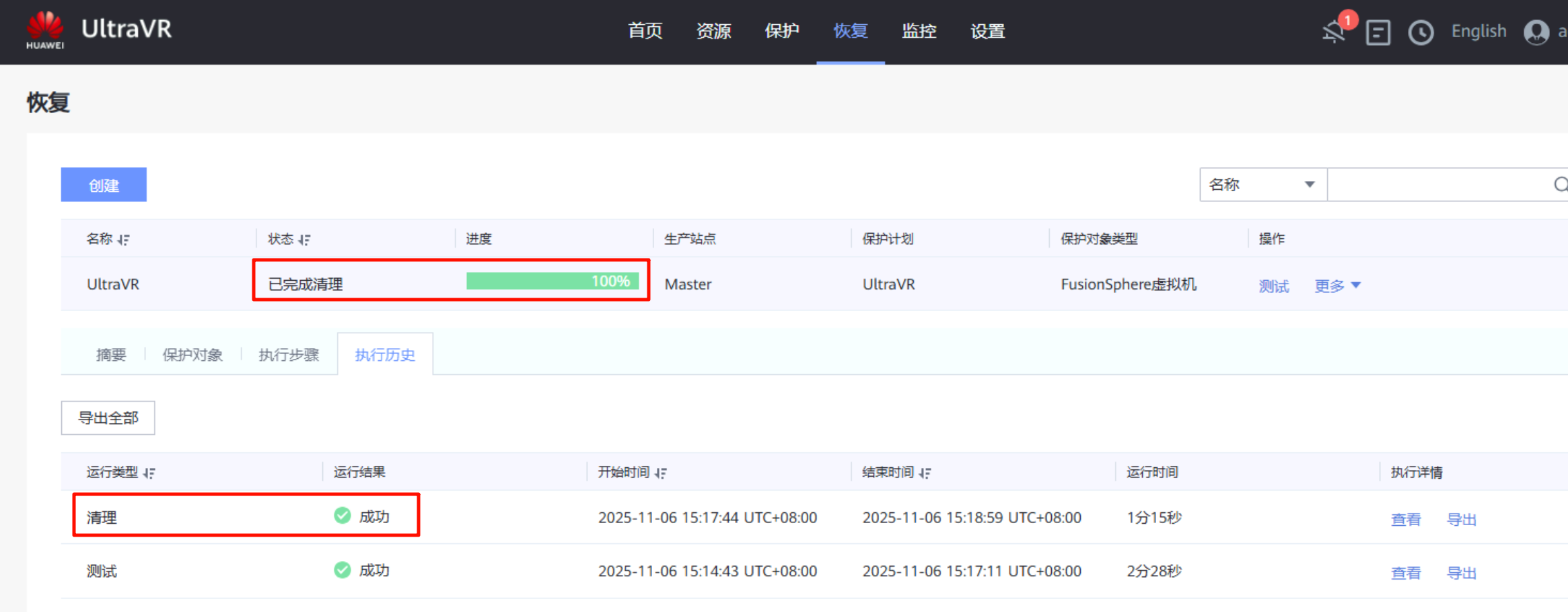
- 支持在不影响生产业务的情况下清理灾备站点的演练数据,还原至容灾演练前资源状态(会删除刚才在灾备站点生成的虚拟机信息)
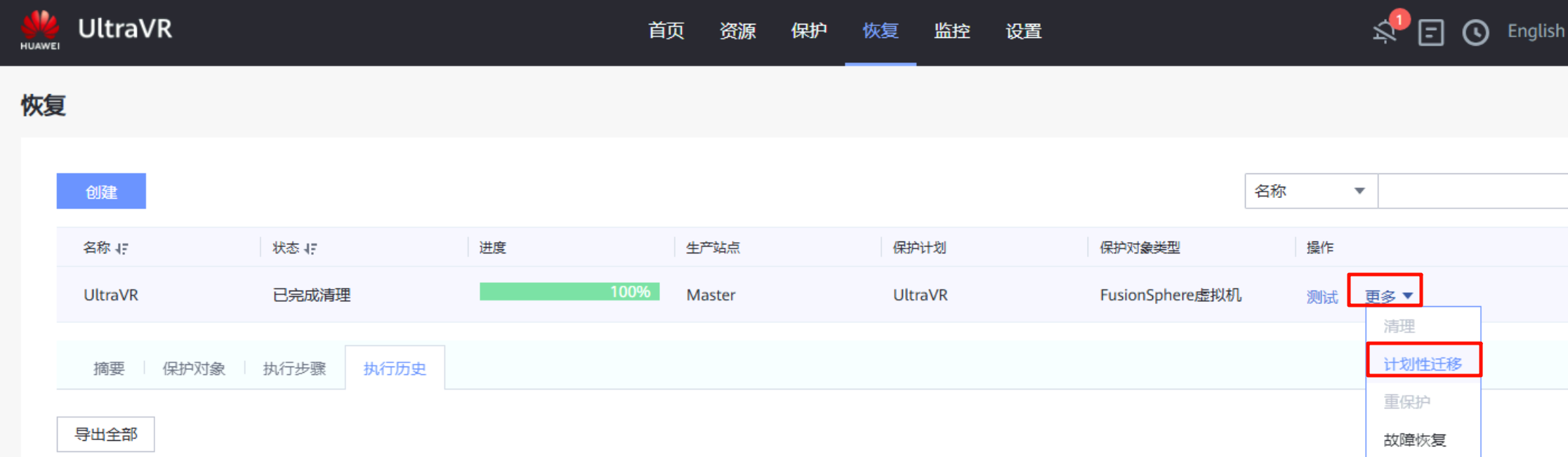
计划性迁移
当生产站点发生计划内风险(如停电、日常运维等)的情况下,可对指定的恢复计划执行计划性迁移,整个过程自动化,不需人工干预,自动完成灾备端业务接管
将生产站点Master的指定虚拟机迁移到灾备站点Slave中
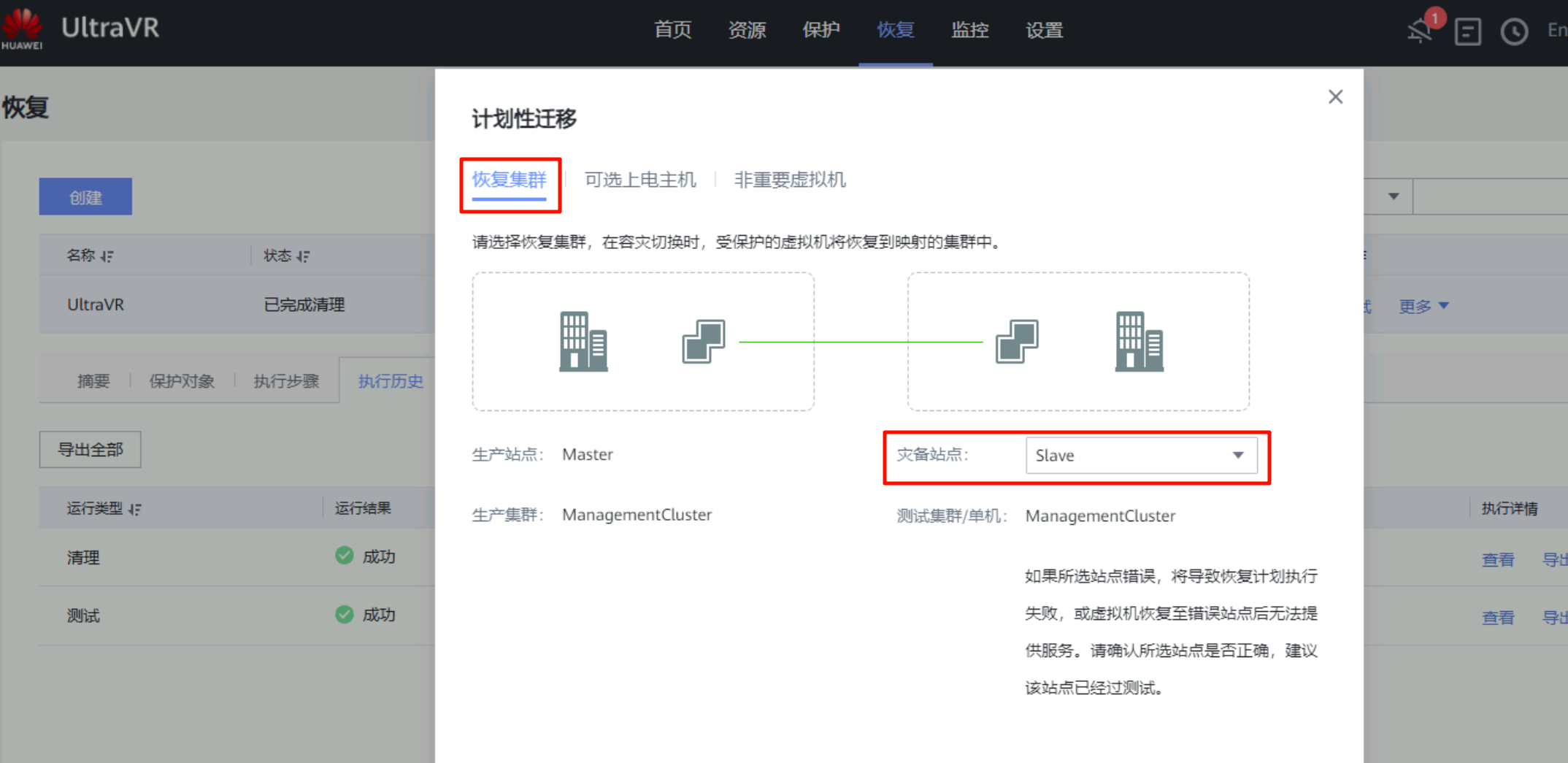
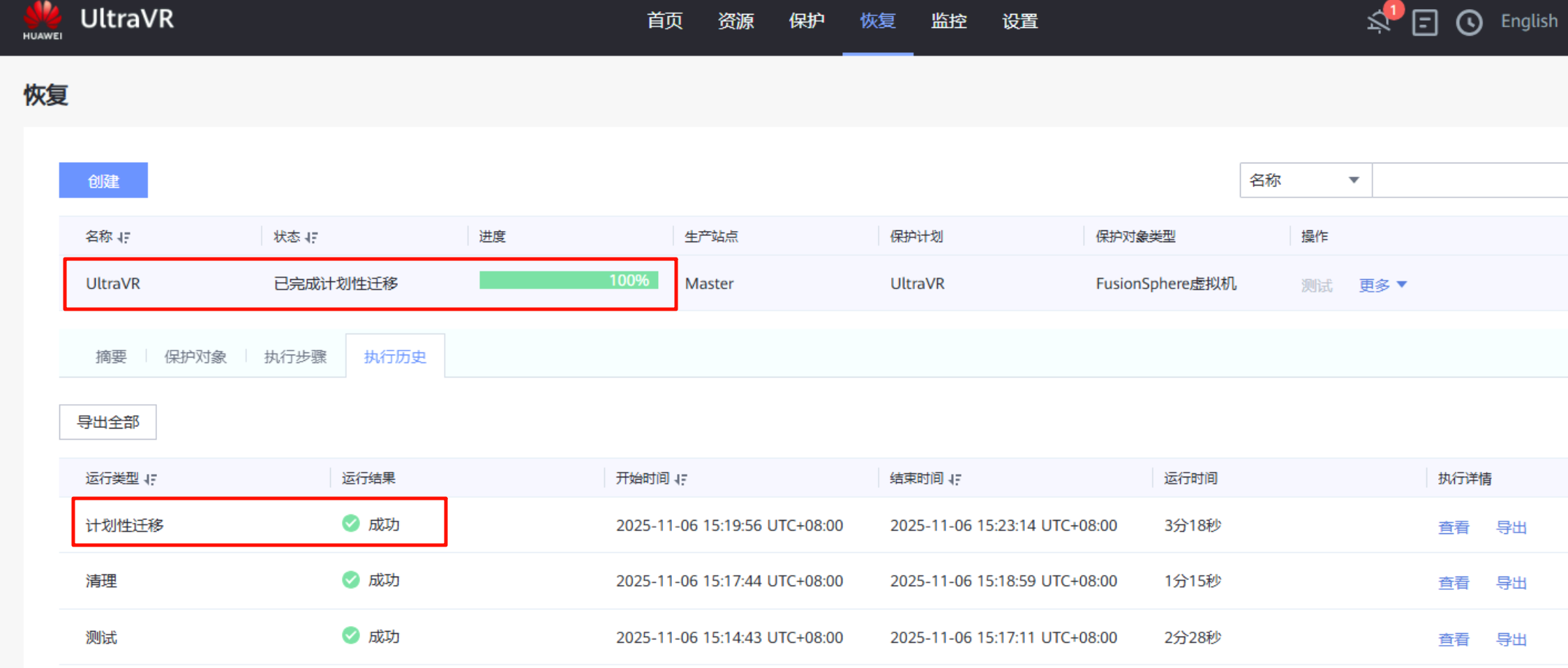
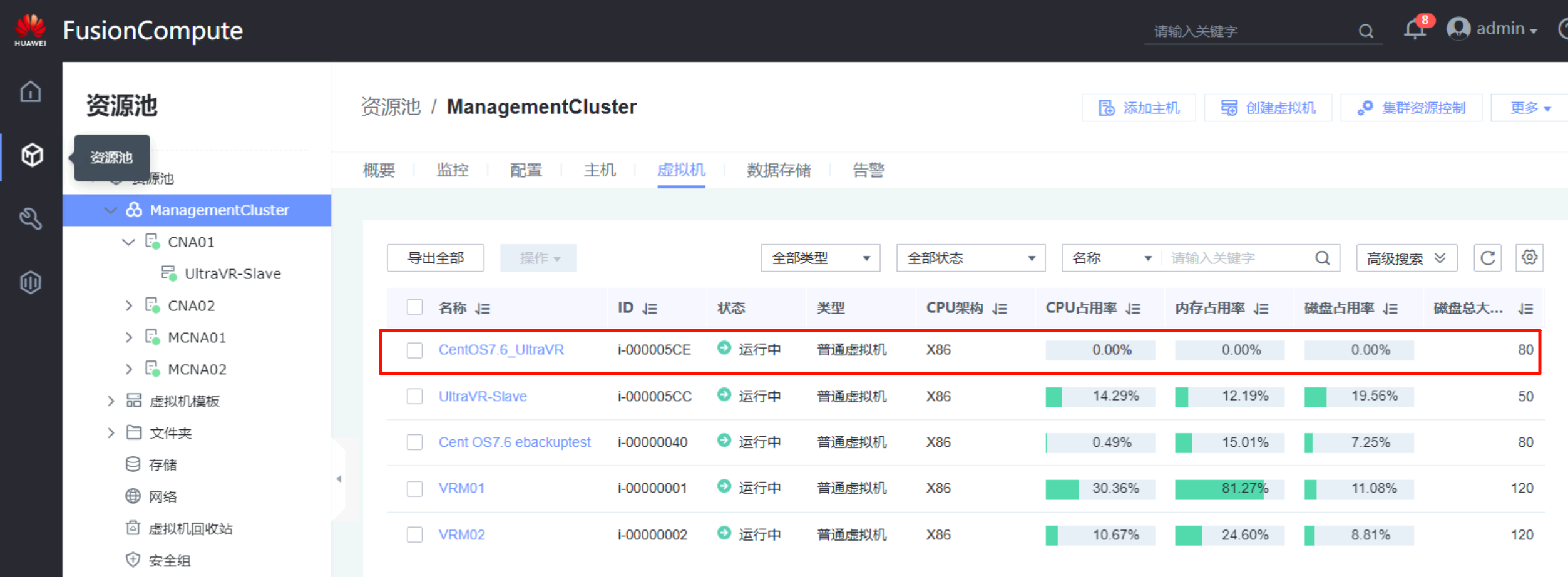
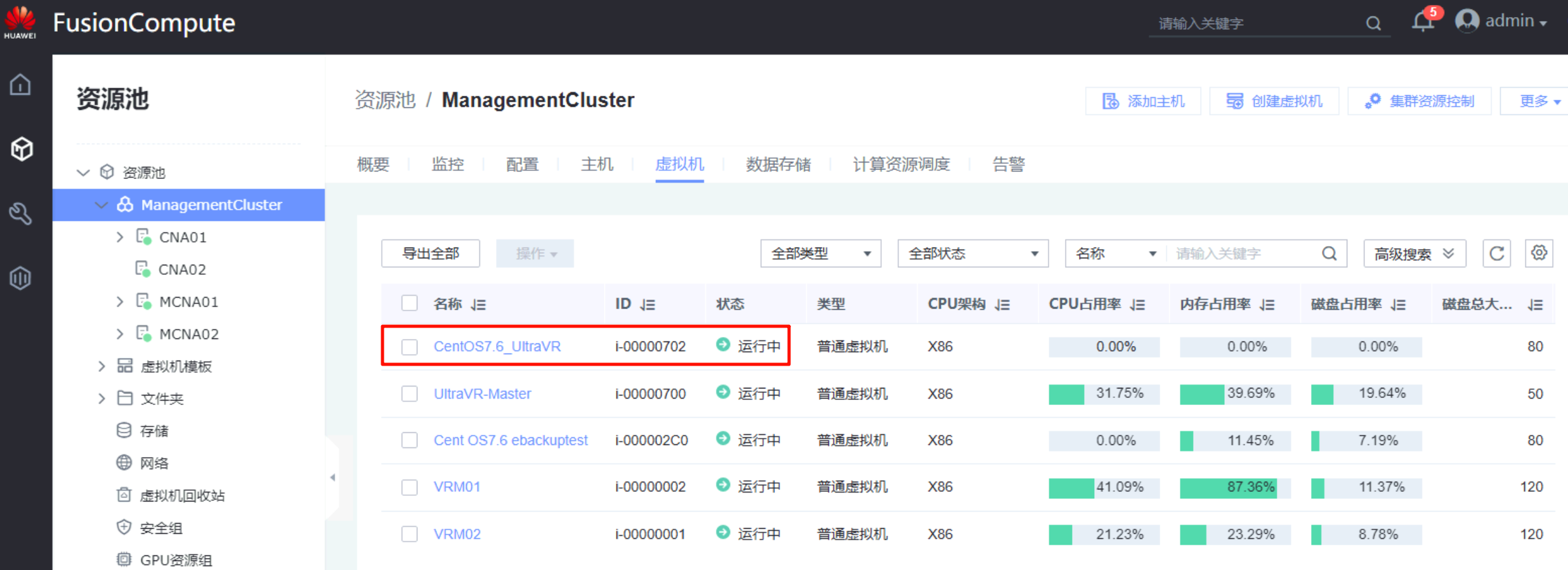
- 迁移完成后,生产站点Master的测试虚拟机
Centos7.6_UltraVR被成功迁移到灾备站点Slave中,表示计划性迁移完成
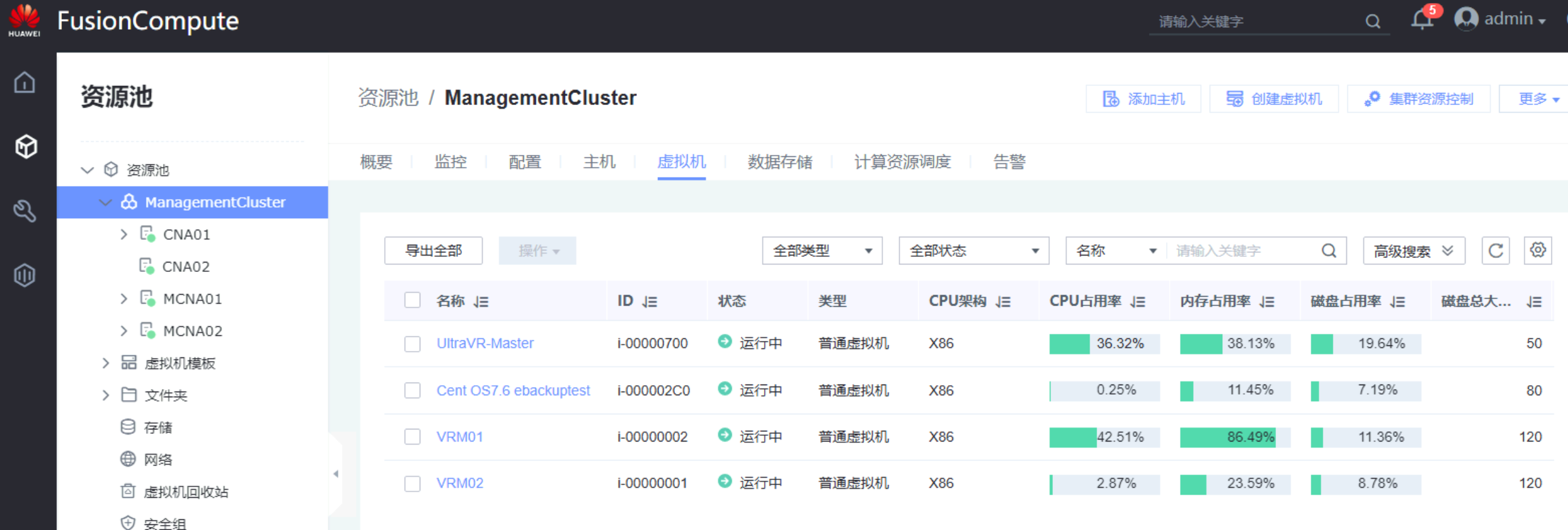
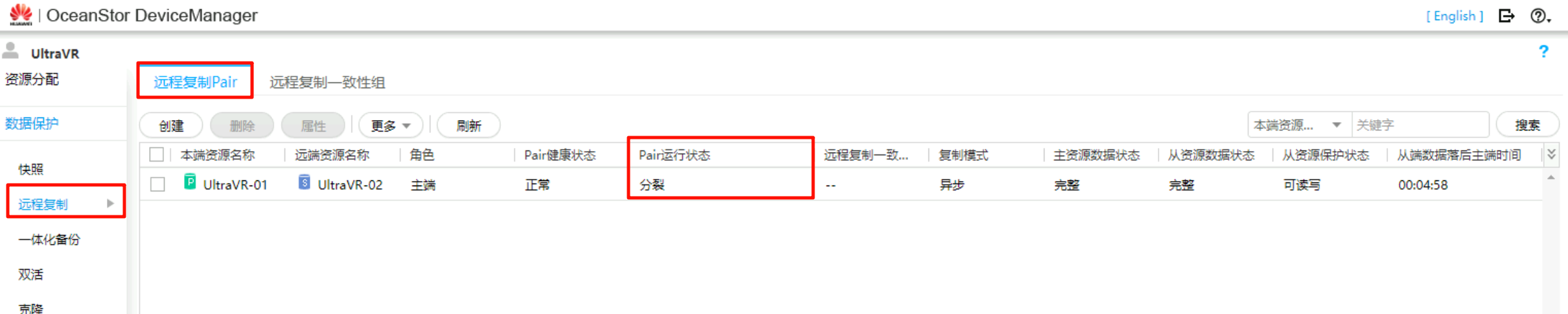
- 迁移完成后,在生产站点Master的存储设备上可看到远程复制Pair的状态为
分裂,从资源保护状态变为可读写
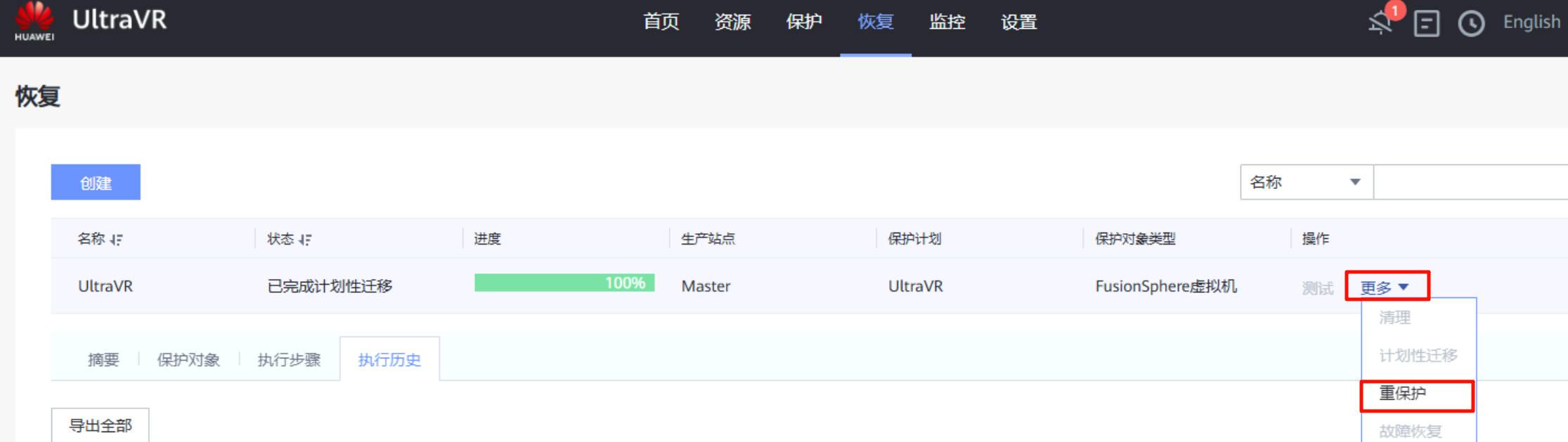
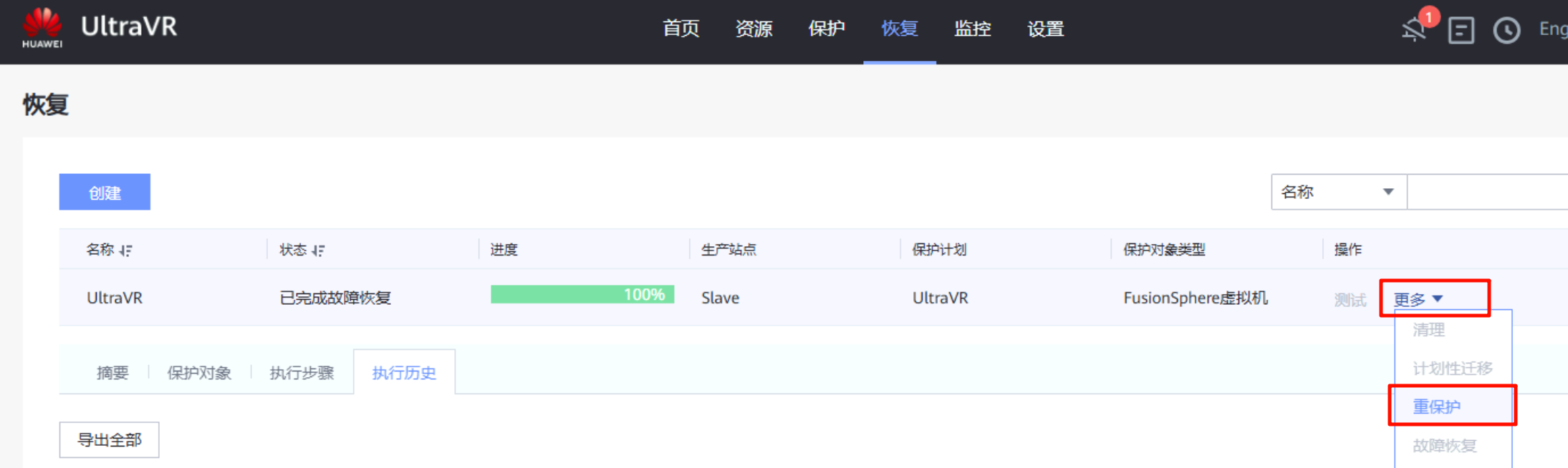
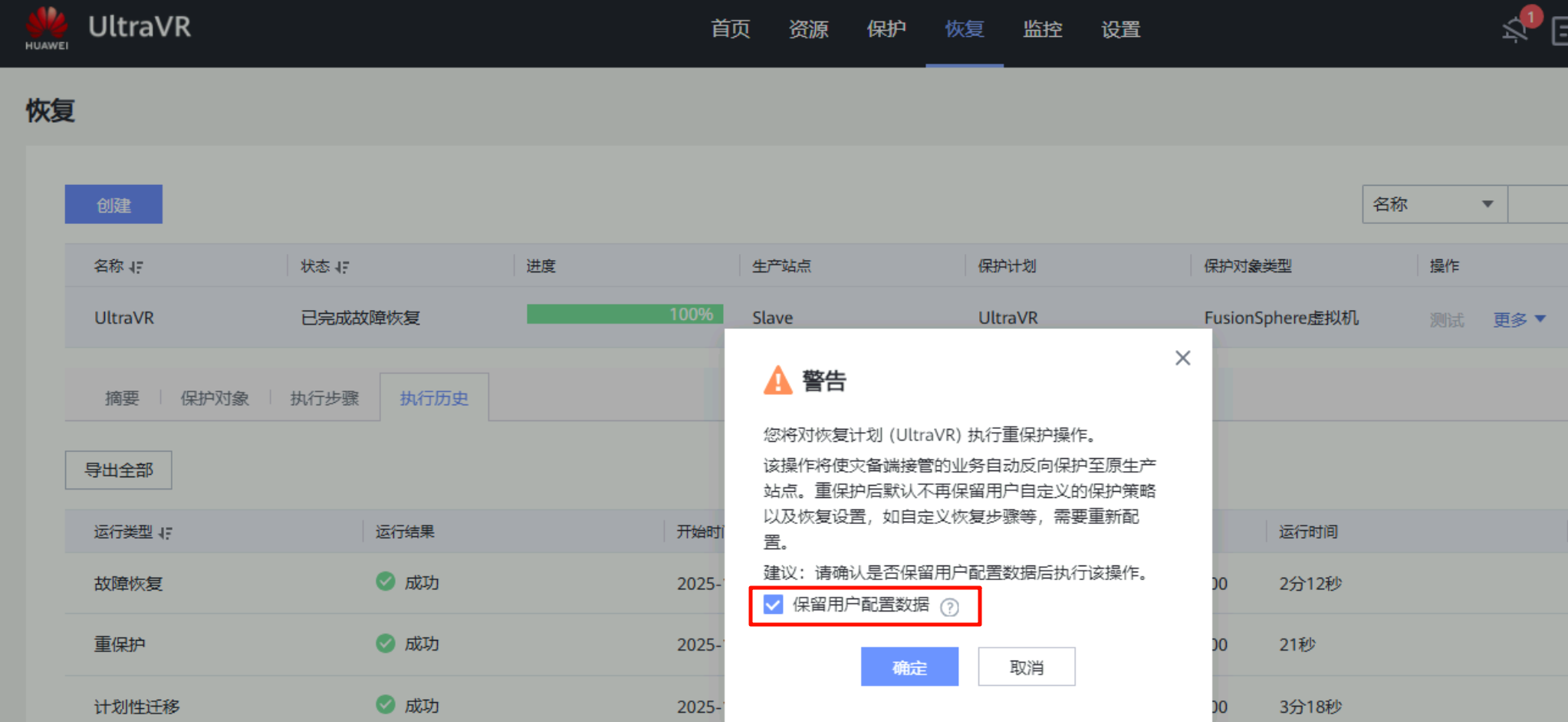
重保护
- 在进行故障切换的同时,数据同步停止;在故障切换完成后,保护组仍处于停止保护状态,需要执行重保护才能开始数据同步(灾备站点Slave数据同步到生产站点Master,防止生产站点故障恢复后,出现故障时数据丢失的情况)
- 在迁移完成后进行重保护,重保护完成后
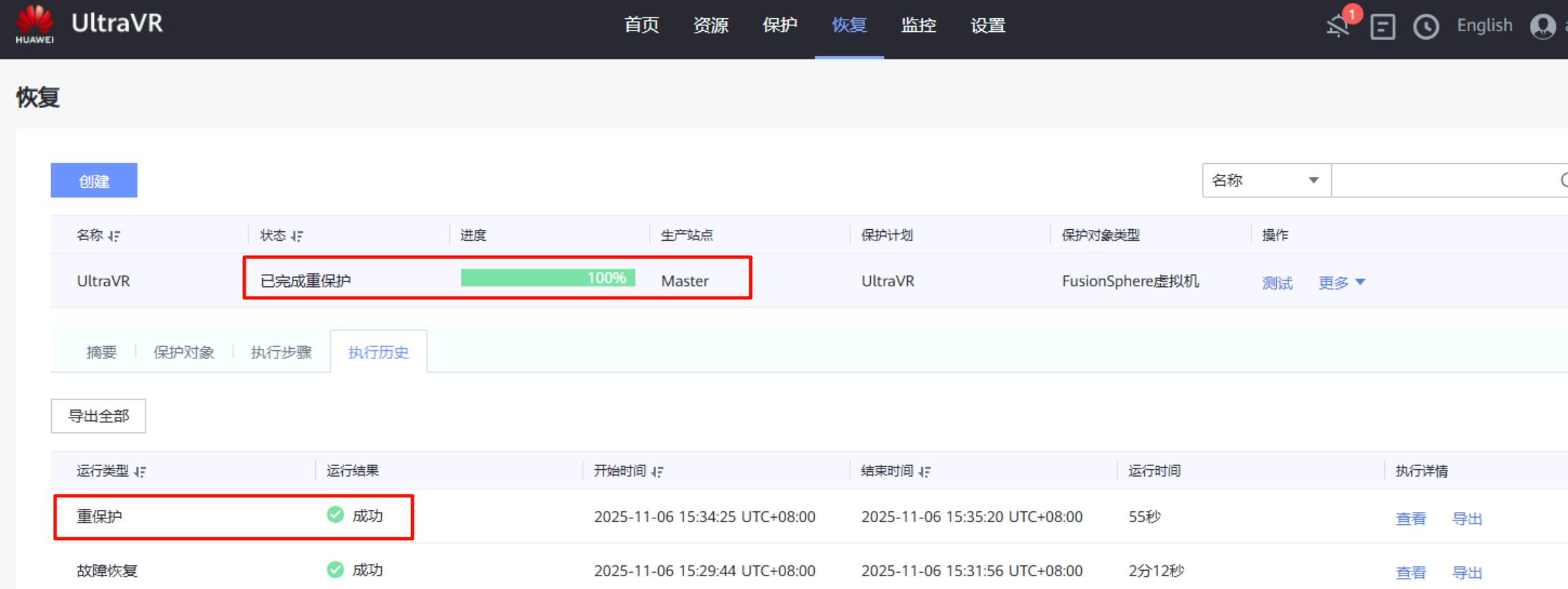
生产站点 Master变为"灾备站点"
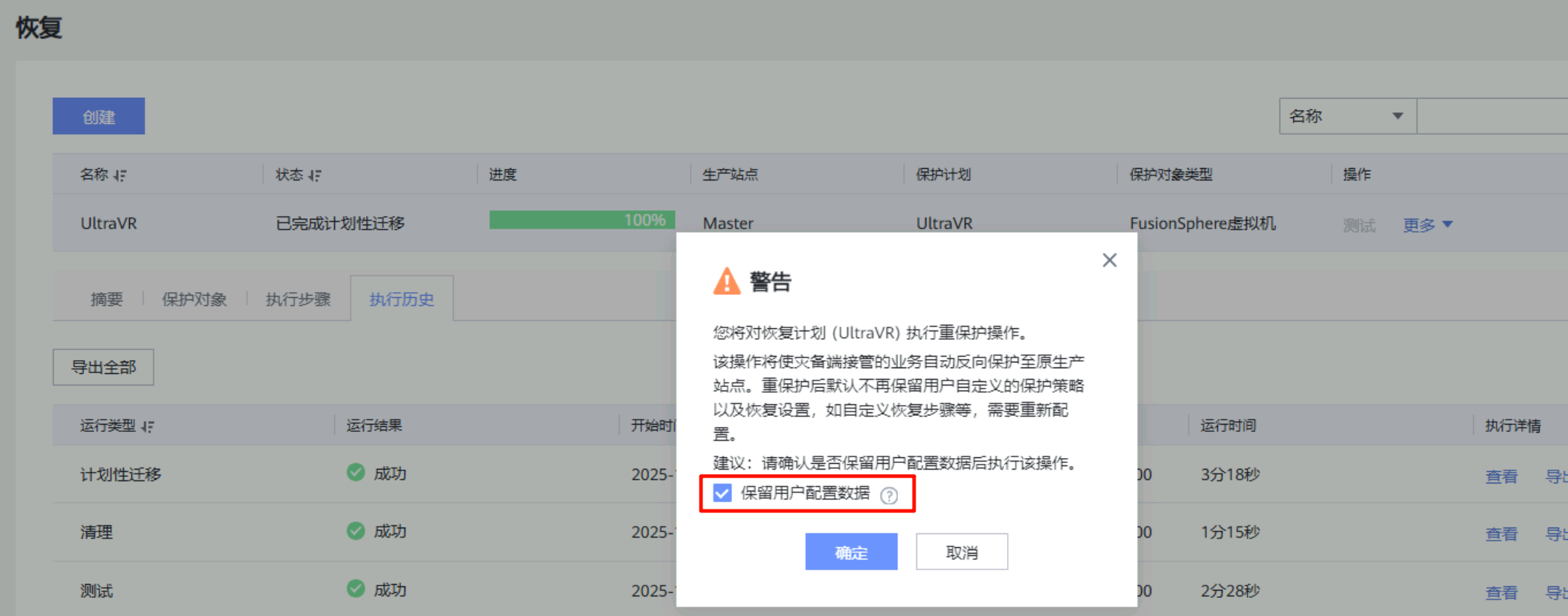
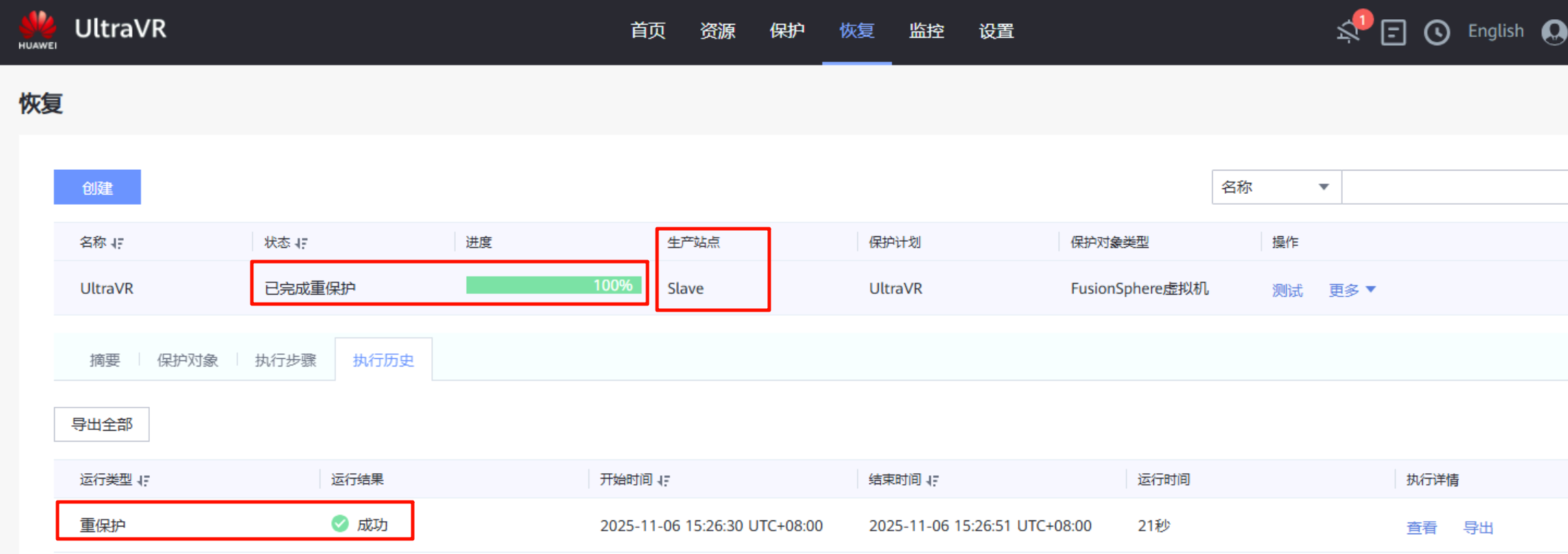
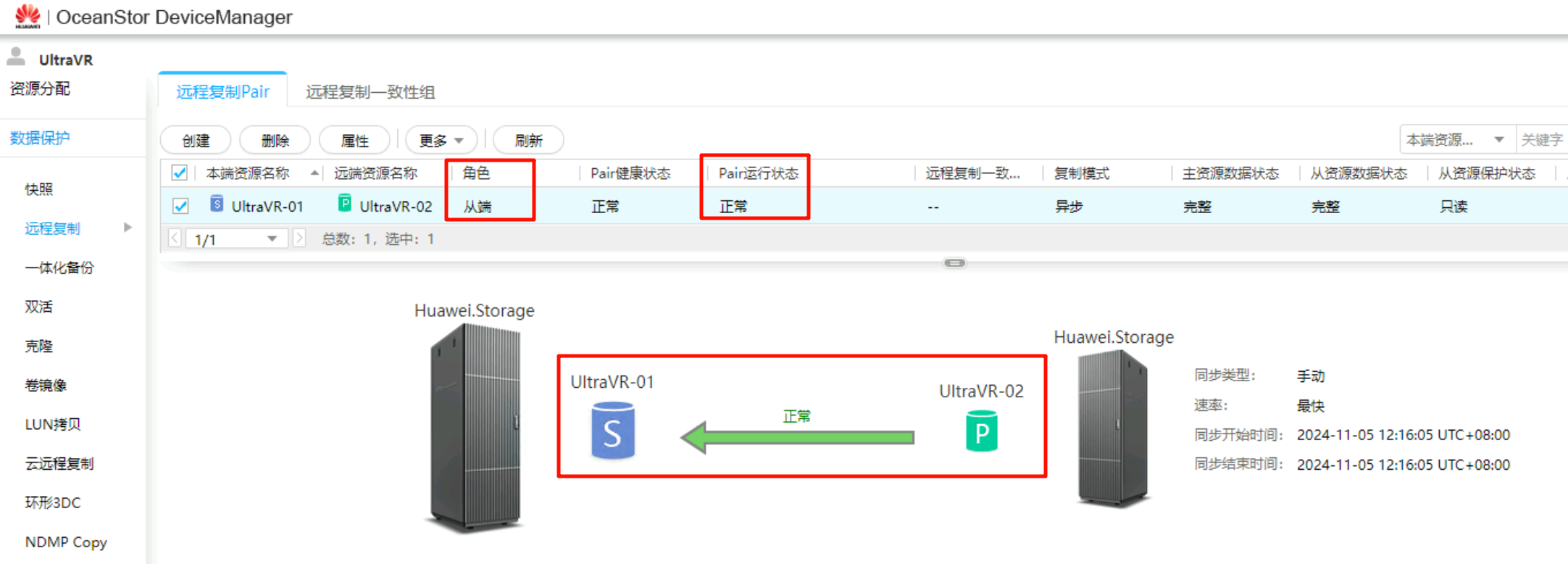
- 重保护执行完成后,生产站点的
远程复制Pair角色由原来的主端变为从端,Pair运行状态由分裂变为正常,数据开始由灾备站点Slave向生产站点Master进行同步
故障恢复
- 当生产站点Master故障恢复后,当前的生产站点变为真正的生产站点Master、灾备站点回到Slave
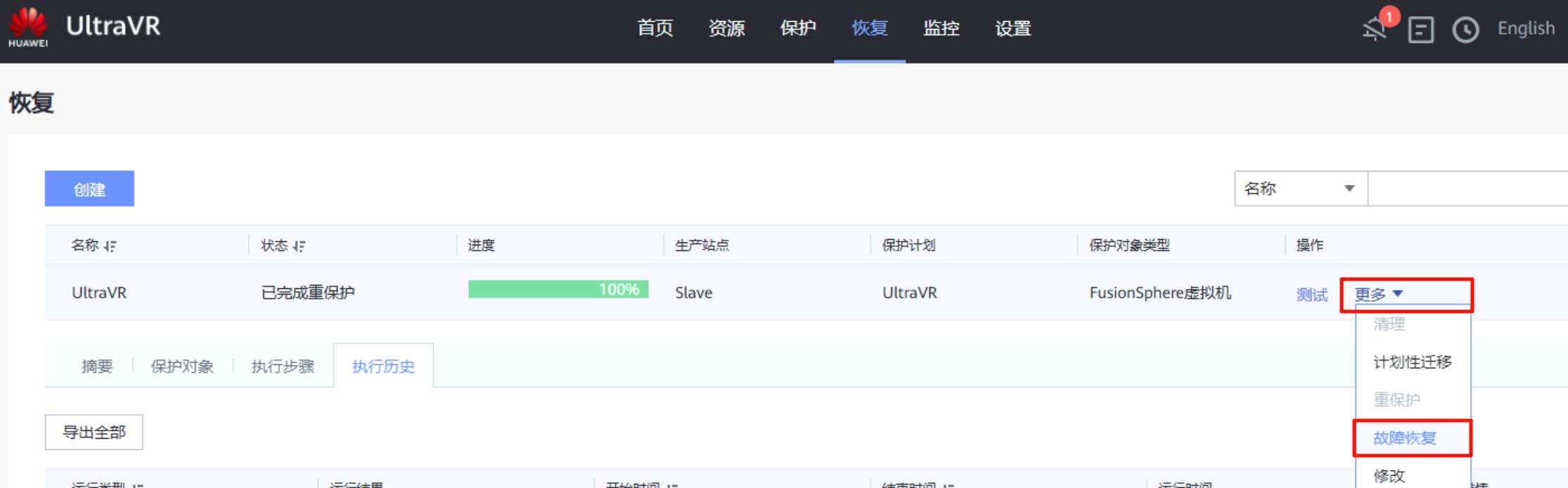
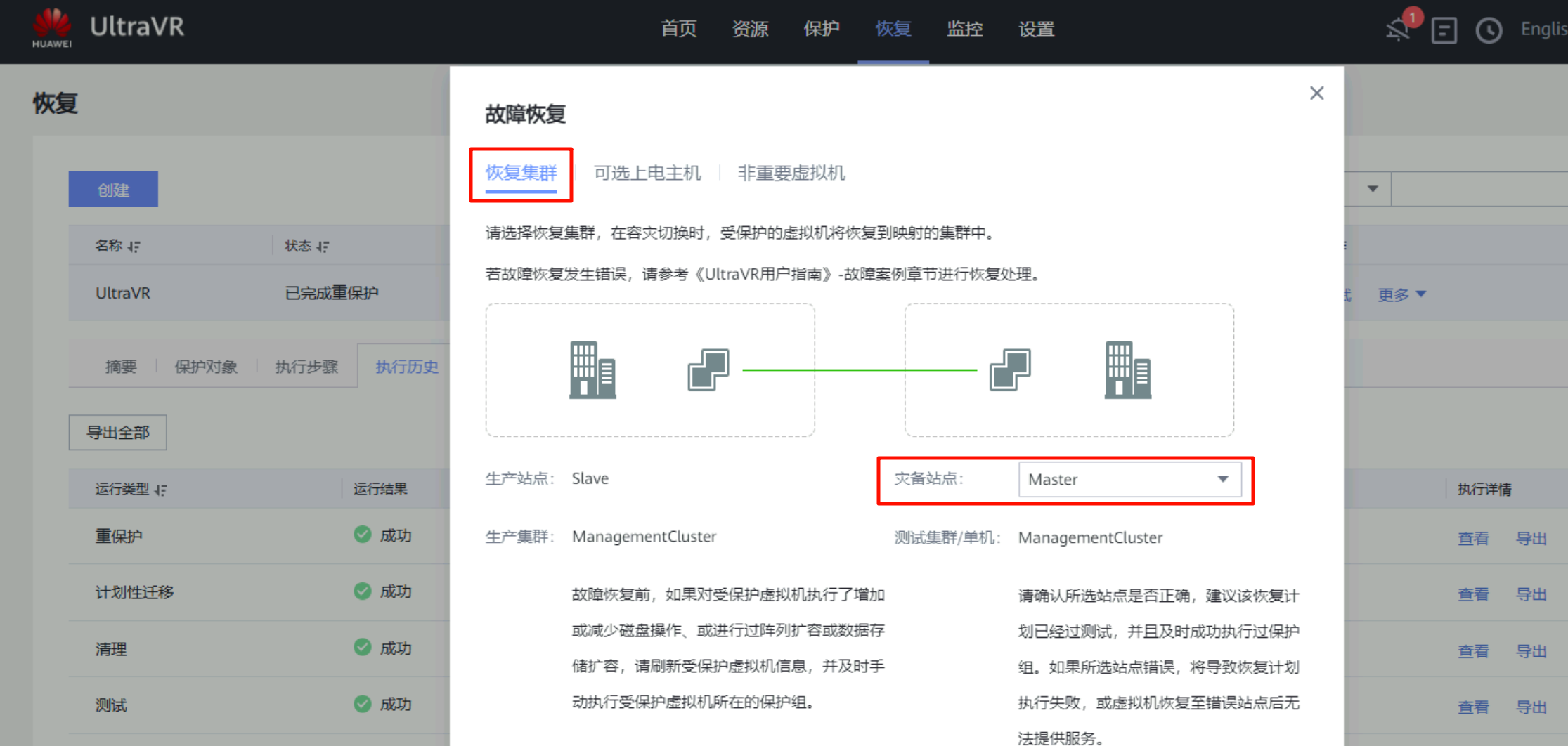
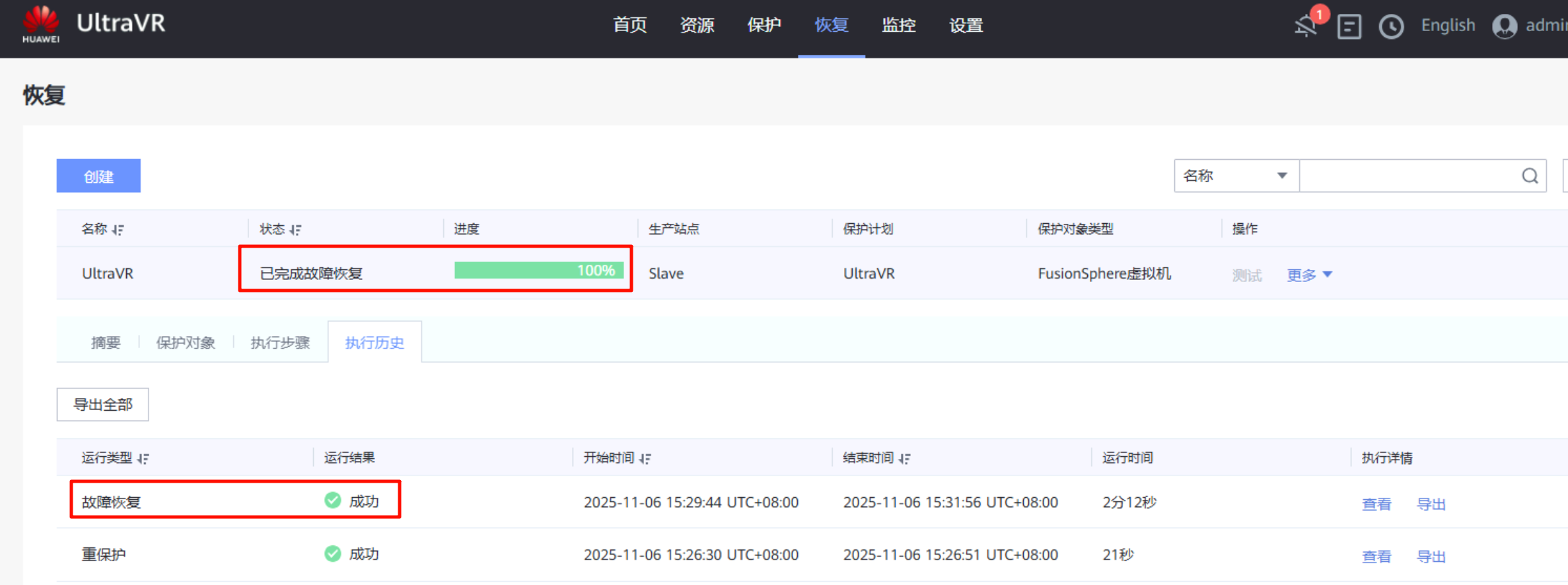
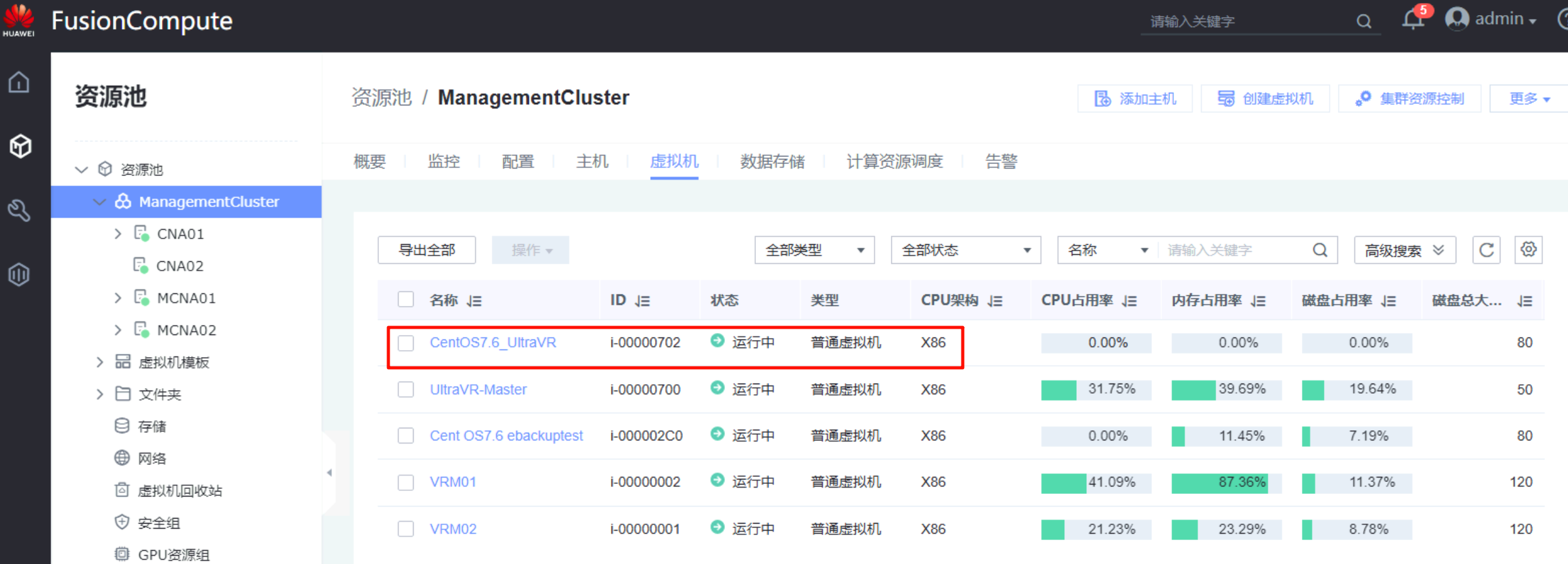
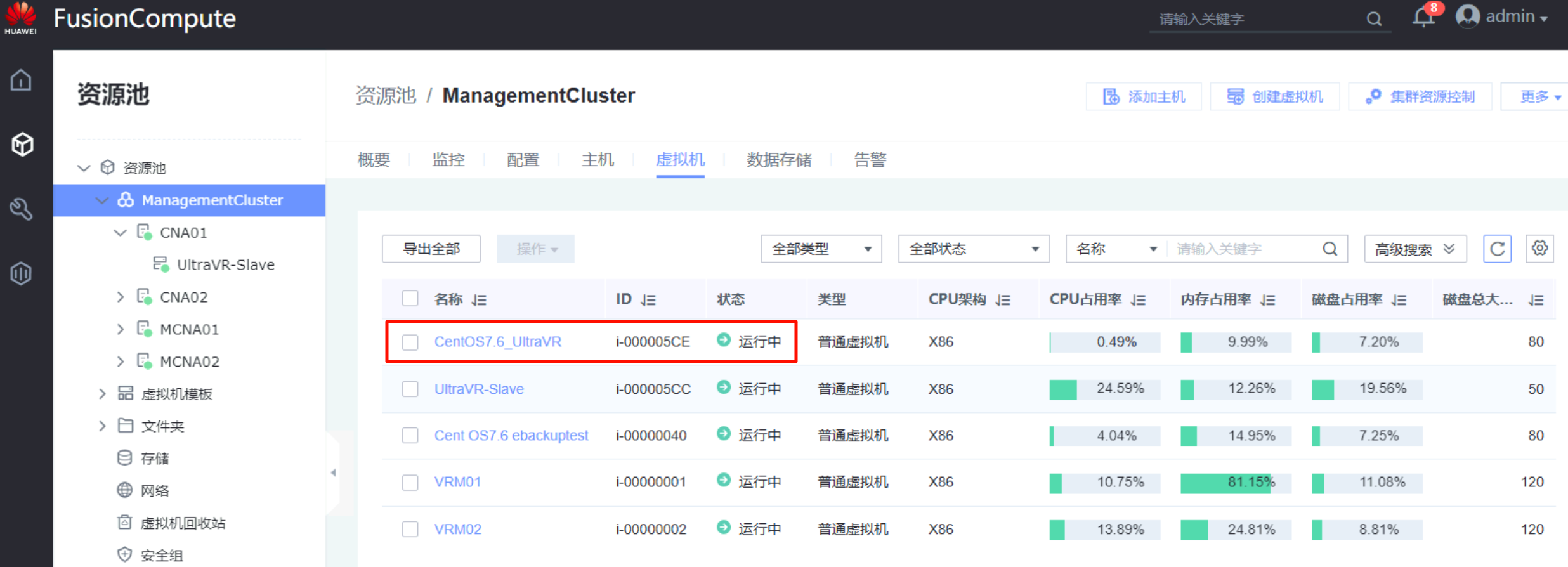
- 生产站点Master的测试主机
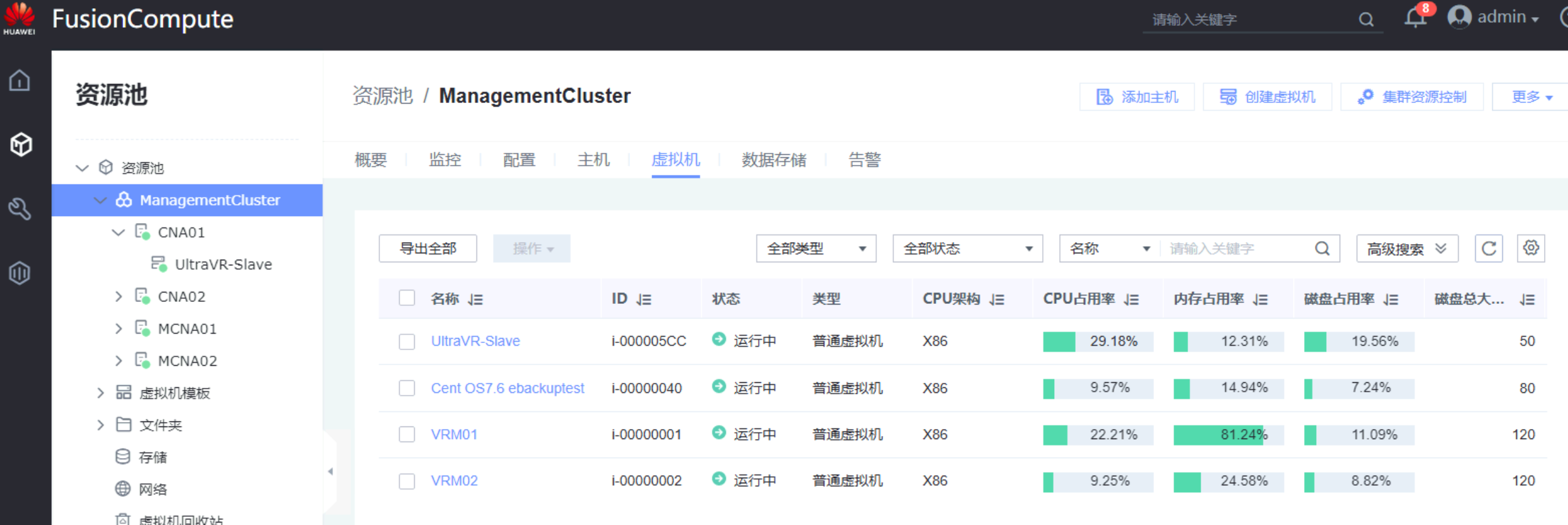
Centos7.6_UltraVR又回到了Master,同时灾备站的测试主机Centos7.6_UltraVR也在正常运行
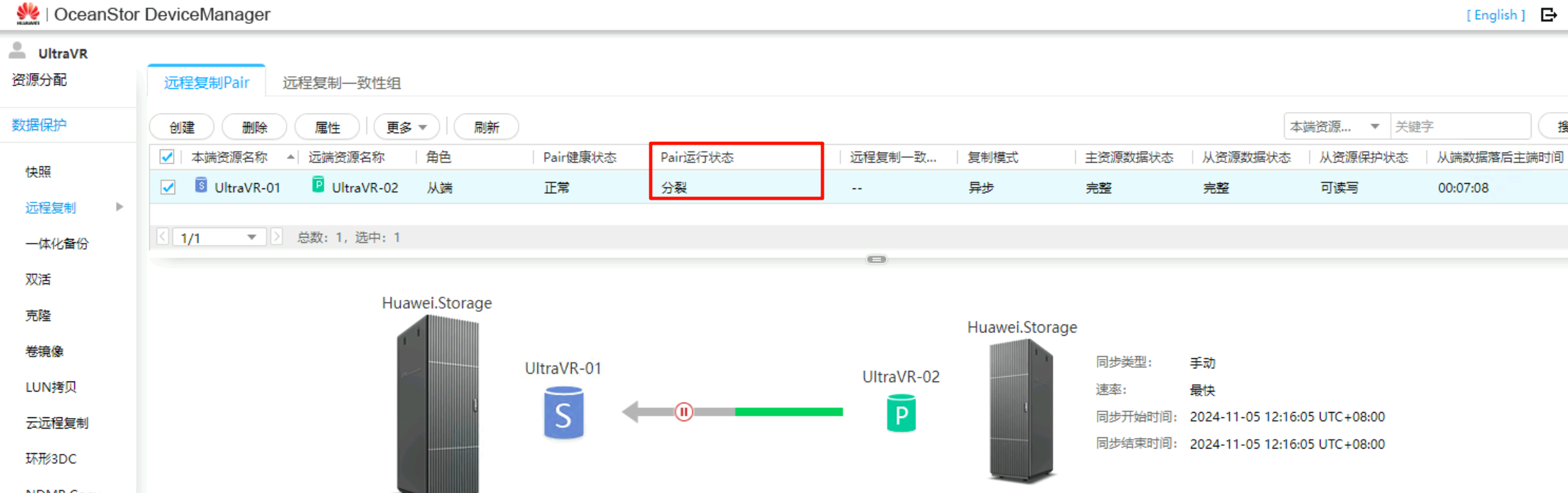
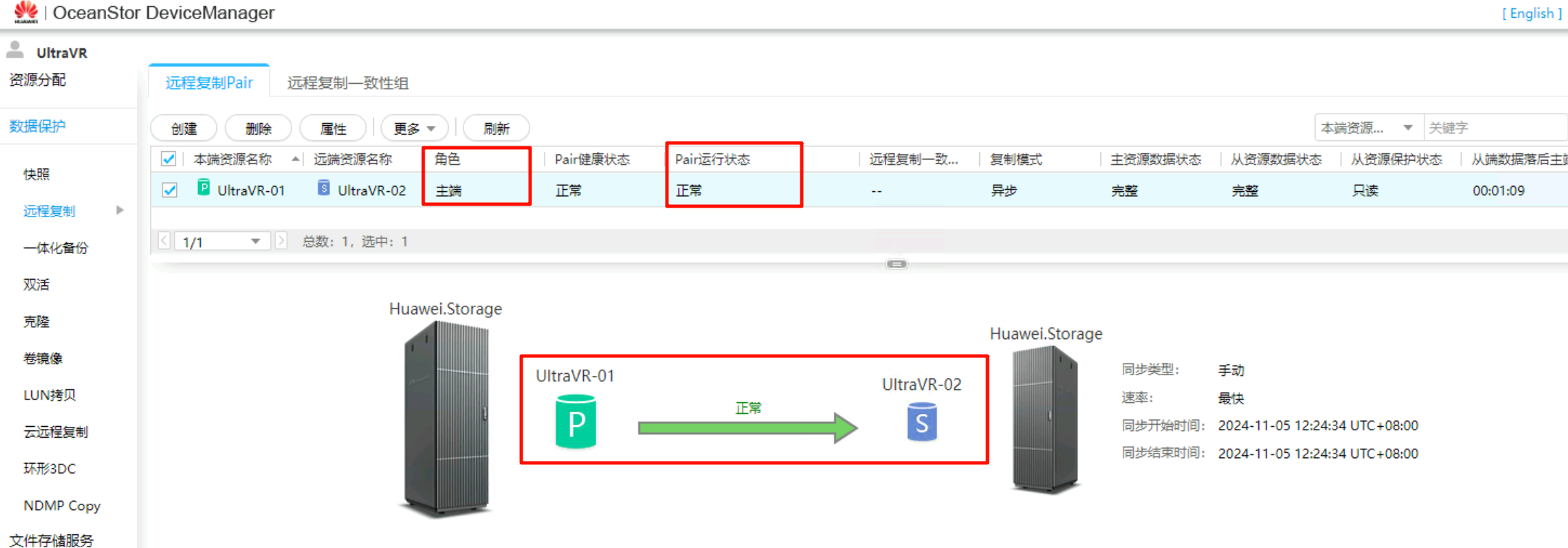
- 生产站点Master的存储设备上可看到远程复制Pair的状态为
分裂,需要执行重保护才能正常同步
- 生产站点Master的测试主机
Centos7.6_UltraVR正常运行,同时灾备站的测试主机Centos7.6_UltraVR被清理
 wechat
wechat alipay
alipay